1npx prisma -h
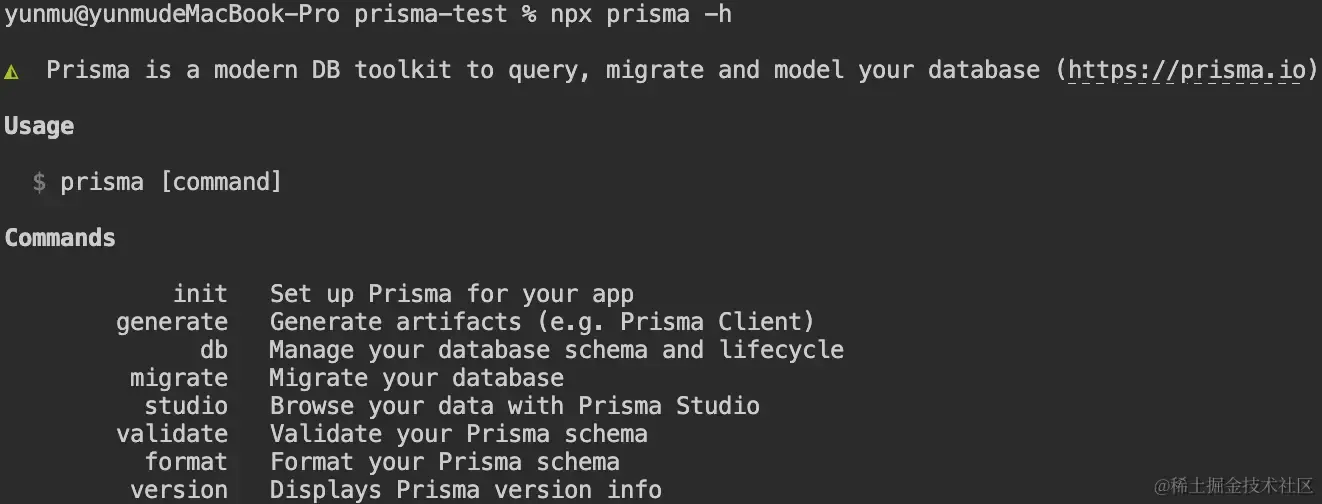
- init:创建 schema 文件,初始化项目结构。
- generate:根据 schema 文件生成客户端代码。
- db:包括数据库与 schema 的同步。
- migrate:处理数据表结构的迁移。
- studio:提供图形化界面进行 CRUD 操作。
- validate:验证 schema 文件的语法。
- format:格式化 schema 文件。
- version:显示版本信息。
环境设置与初始化
首先,我们需要创建一个新的项目并设置 Prisma:
1mkdir prisma-all-command
2cd prisma-all-command
3npm init -y
4npm install prisma -g
5prisma init
初始化与配置
执行 init 命令:
1prisma init --datasource-provider mysql
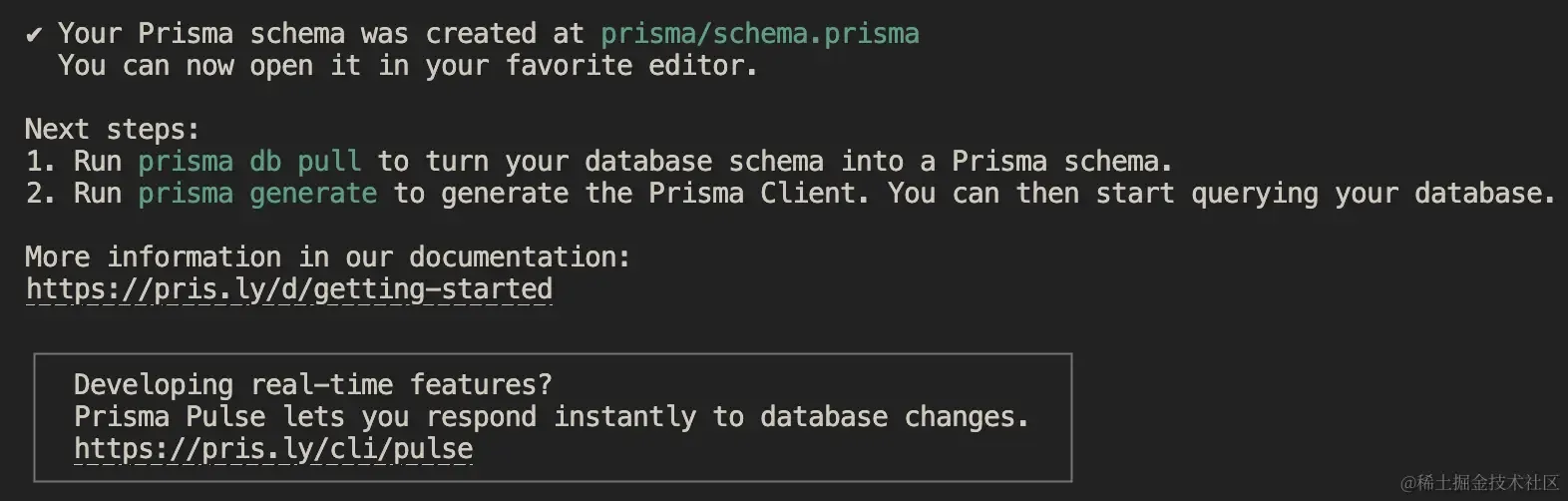
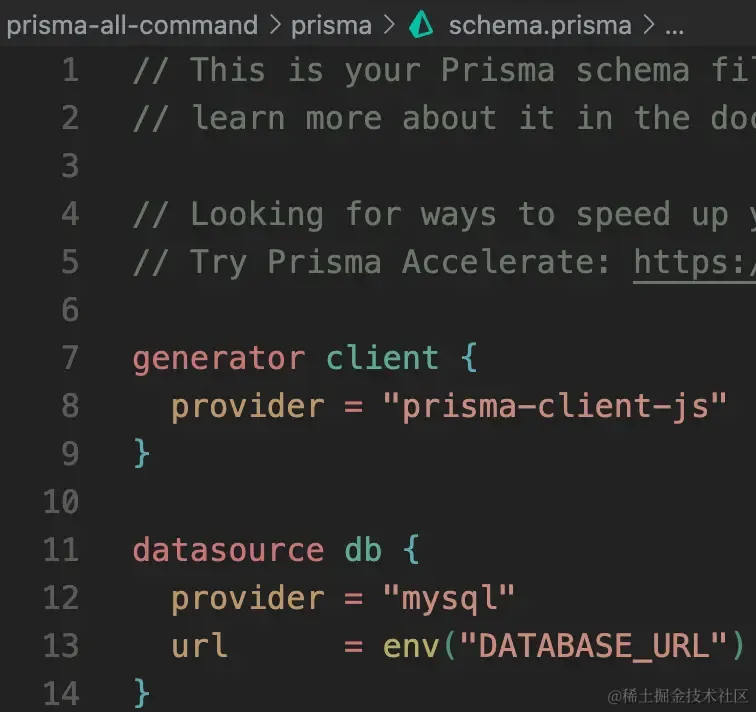
执行后,生成 prisma/schema.prisma 和 .env 文件,配置数据库连接。
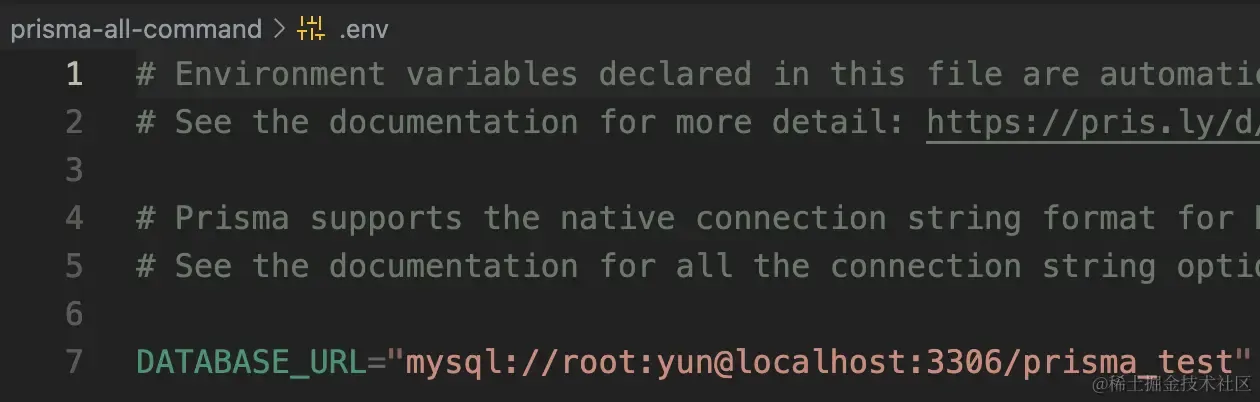
修改数据库连接:
- 可通过修改
.env文件中的 URL 来更改数据库连接,例如:
1prisma init --url mysql://root:password@localhost:3306/prisma_test
- password:这是连接数据库的密码。在实际使用中,你应该替换成你的实际数据库密码。
数据库与 Schema 同步
拉取数据库结构到 Schema
1prisma db pull
此命令将数据库中的表结构同步到 Prisma 的 schema 文件中。
现在连接的 prisma_test 数据库里是有这两个表:

执行 prisma db pull 后:
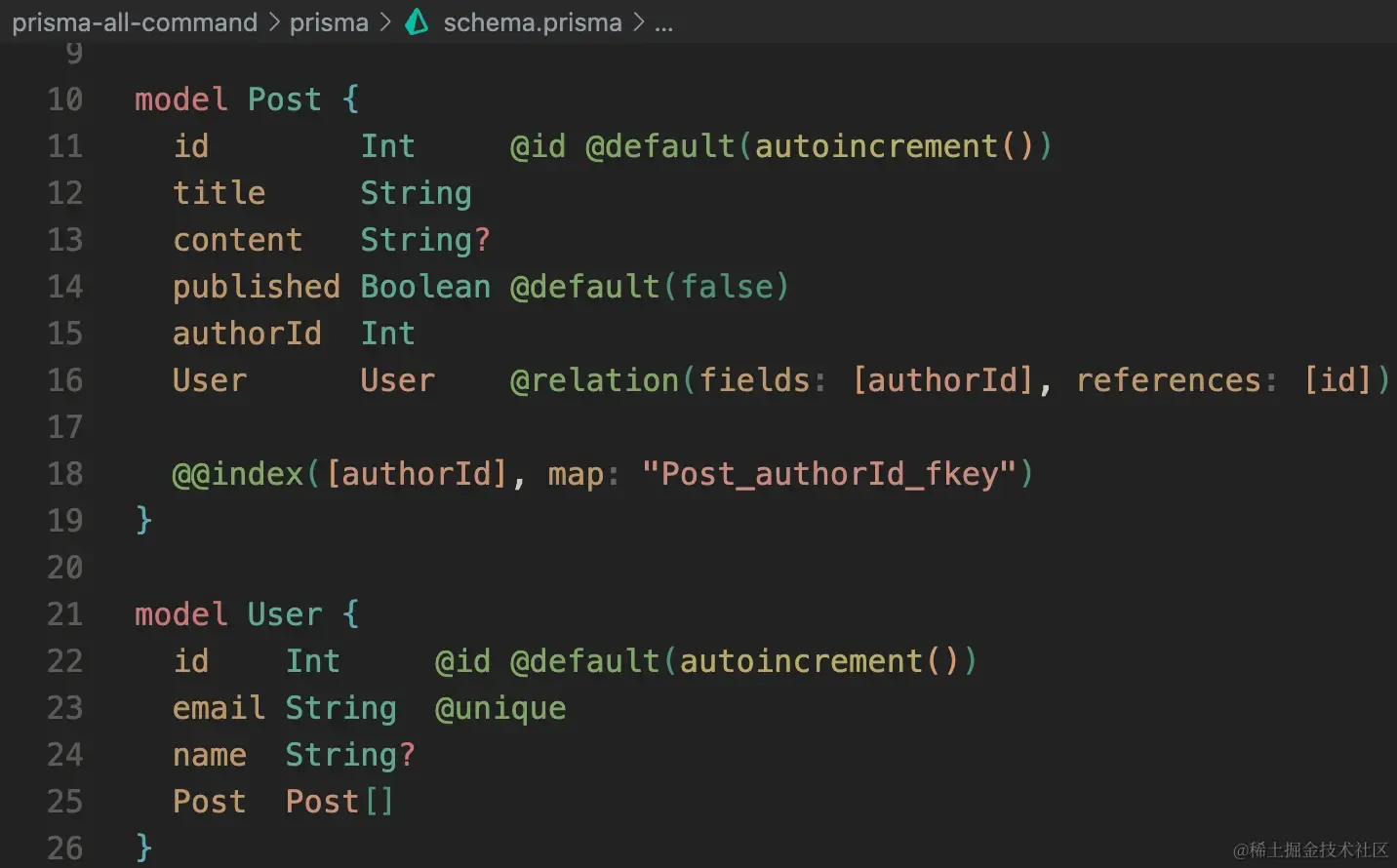
推送 Schema 更改到数据库
1prisma db push
将 schema 文件中的更改推送到数据库,同步表结构。
我们先把表全部删除:
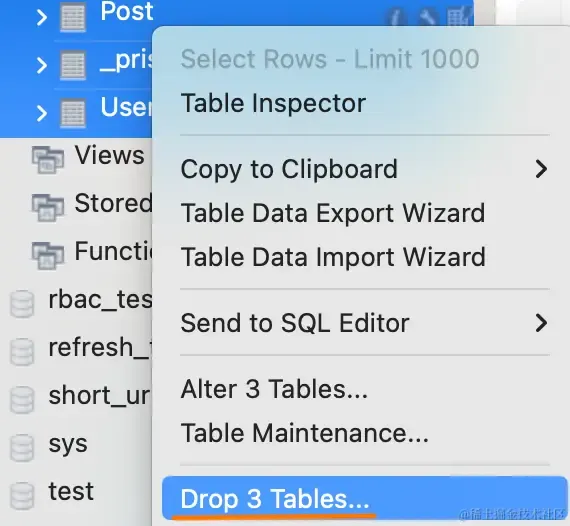
执行 prisma db push 后:
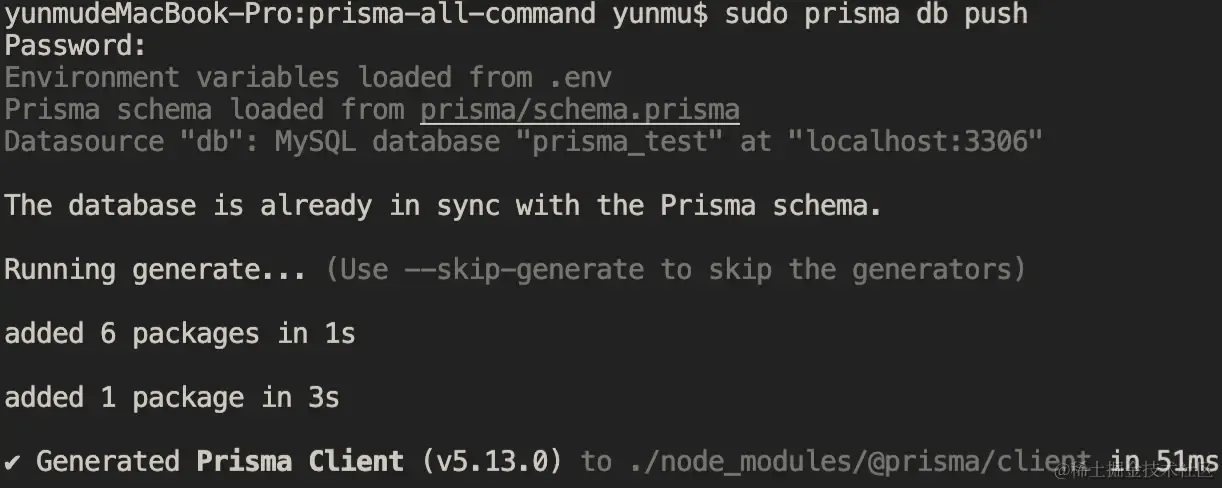
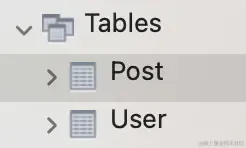
重新生成了这两张表。
数据迁移
创建与应用迁移:
1prisma migrate dev --name init
此命令根据 schema 的更改生成 SQL 文件,并执行这些 SQL 来更新数据库结构,同时生成客户端代码。
数据库中的 _prisma_migrations 表记录所有迁移历史,有助于跟踪每次迁移的详细信息:
数据初始化与脚本执行
数据初始化脚本
prisma/seed.ts:
1import { PrismaClient } from '@prisma/client';
2const prisma = new PrismaClient();
3async function main() {
4 const user = await prisma.user.create({
5 data: {
6 name: '云牧',
7 email: 'xx@xx.com',
8 Post: {
9 create: [
10 { title: '文章1', content: '内容1' },
11 { title: '文章2', content: '内容2' },
12 ],
13 },
14 },
15 });
16 console.log(user);
17}
18
19main();
在 package.json 中添加脚本执行命令:
1"prisma": {
2 "seed": "npx ts-node prisma/seed.ts"
3}
执行命令 prisma db seed 来插入初始数据:
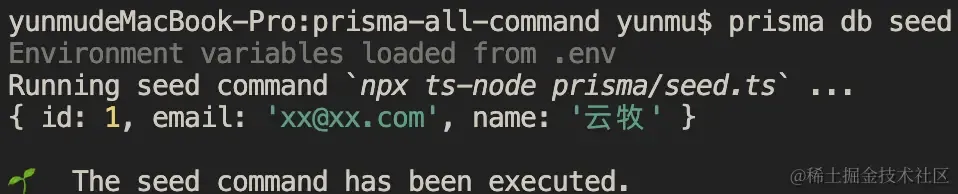
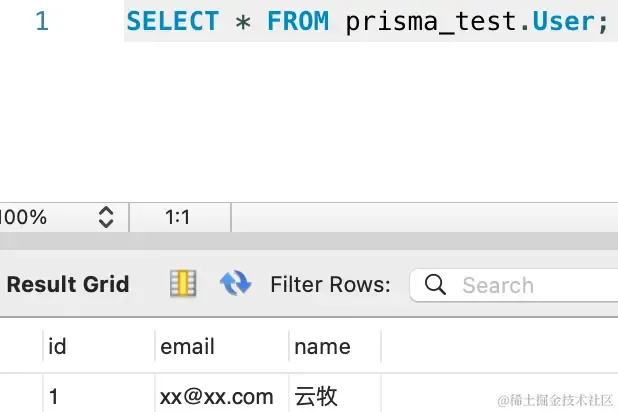
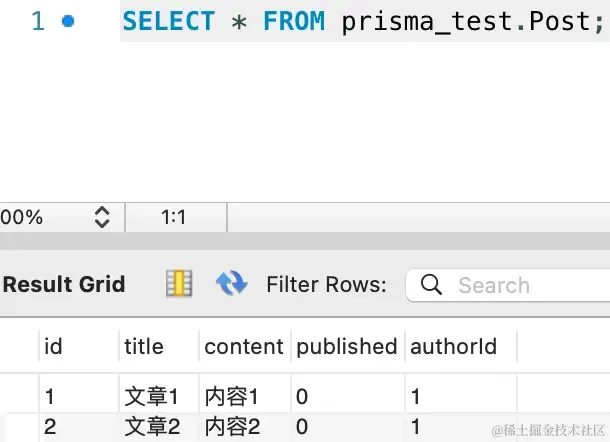
数据正确插入了。
执行 SQL 脚本
写一个 prisma/test.sql:

执行命令:
1prisma db execute --file prisma/test.sql --schema prisma/schema.prisma

SQL 脚本执行后,会删除 id 为 2 的文章:
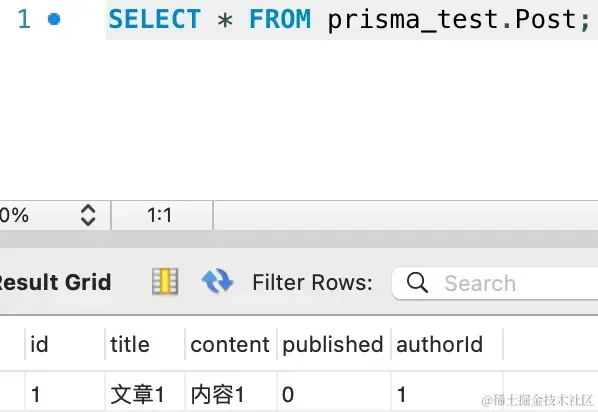
重置数据库
使用 prisma migrate reset 命令可以重置数据库,清空所有数据,并重新执行所有迁移和数据初始化。
代码生成
prisma generate 命令用于根据 schema.prisma 文件生成 Prisma 客户端代码,这些代码位于 node_modules/@prisma/client 目录下,主要用于实现 CRUD 操作。
注意:该命令不会同步数据库结构,仅根据 schema 文件生成客户端代码。
图形界面操作
prisma studio 提供了一个用户友好的图形界面,使得用户可以直接在浏览器中进行数据的增删改查操作:

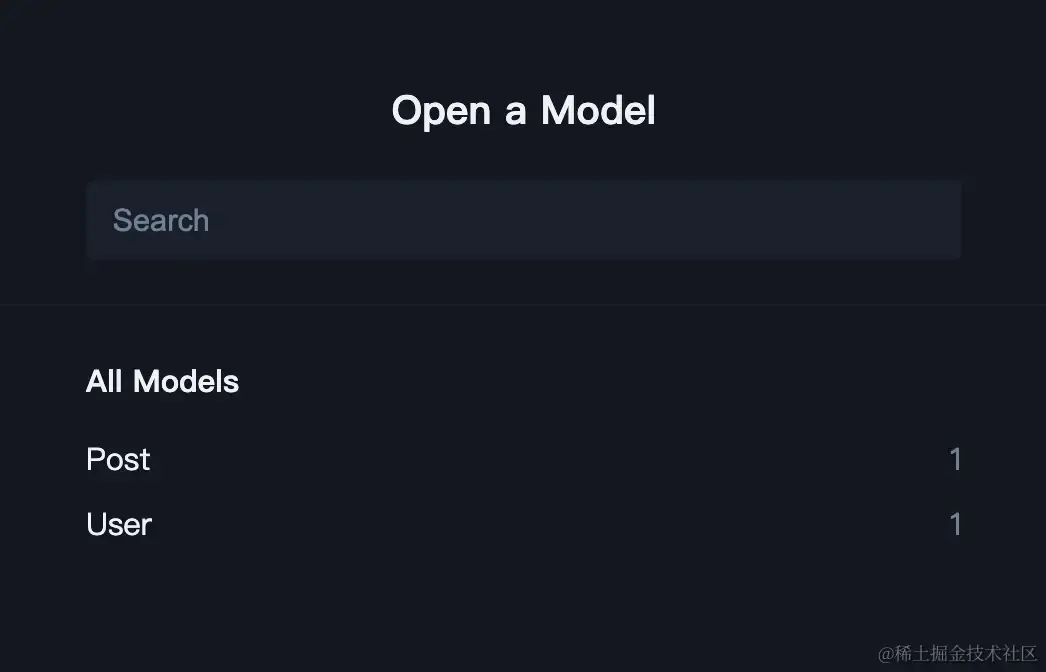

用户可以通过界面直接编辑、删除或新增数据记录。
一般我更倾向使用如 MySQL Workbench,进行数据库操作。
Schema 验证
prisma validate 命令用于检查 schema.prisma 文件中是否存在语法错误。
安装 Prisma 的 VSCode 插件后,可以在编辑器内直接看到 schema 文件的错误,类似于 ESLint 的功能。
文件格式化
prisma format 命令用于自动格式化 schema.prisma 文件,确保文件的风格一致性和可读性。
安装 Prisma 的 VSCode 插件,直接使用编辑器的格式化功能来格式化 schema 文件,提高开发效率。
版本信息
prisma version 命令用于显示 Prisma CLI 和 Prisma Client 的当前版本信息。这对于调试问题或确保使用的是最新功能非常有用。
初始化项目
首先,创建一个新的项目目录并初始化:
1mkdir prisma-schema
2cd prisma-schema
3npm init -y
4npm install prisma -g
在项目目录中执行初始化命令:
1prisma init
这将生成 .env 和 schema.prisma 文件。
配置数据库
编辑 .env 文件,设置数据库连接信息:
1DATABASE_URL="mysql://root:输入自己的密码@localhost:3306/prisma_test"
在 schema.prisma 文件中配置数据源和模型:
1datasource db {
2 provider = "mysql"
3 url = env("DATABASE_URL")
4}
5
6model User {
7 id Int @id @default(autoincrement())
8 email String @unique
9 name String?
10}
生成客户端代码
运行以下命令生成 Prisma 客户端:
1prisma generate
客户端代码默认生成在 node_modules/@prisma/client。可以通过修改 schema.prisma 中的 generator 配置来改变输出目录:
1generator client {
2 provider = "prisma-client-js"
3 output = "../generated/client"
4}
重新运行 prisma generate,客户端代码将在指定的目录生成。
数据库迁移
使用以下命令创建和运行迁移:
1prisma migrate dev --name init_migration
这会根据模型生成相应的 SQL 文件并执行:
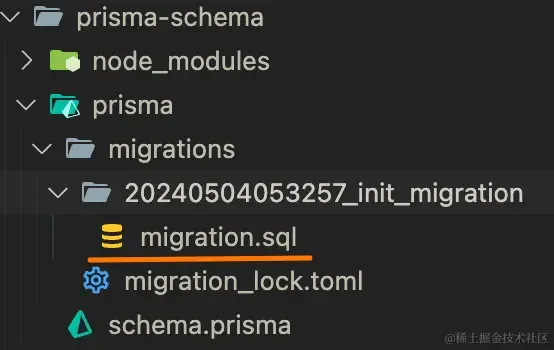
扩展模型和迁移
添加更复杂的模型,例如:
1model Test {
2 id Int @id @default(autoincrement()) // 定义一个名为 id 的整数字段,作为主键,且自动递增
3 t1 String @db.Text // 定义一个名为 t1 的文本字段,使用数据库的 Text 类型存储
4 t2 Int @map("tt2") @db.TinyInt // 定义一个名为 t2 的整数字段,使用数据库的 TinyInt 类型,实际在数据库中的字段名为 tt2
5 t3 String @unique @db.VarChar(50) // 定义一个名为 t3 的字符串字段,限定最大长度为50,且在数据库中该字段值唯一
6
7 @@index([t2, t3]) // 为 t2 和 t3 字段创建一个复合索引
8 @@map("test_test") // 指定在数据库中该表的实际名称为 test_test
9}
运行迁移:
1npx prisma migrate dev --name m1
生成了表:

定义关系
定义一对多和多对多的模型关系:
1
2model Department {
3 id Int @id @default(autoincrement())
4 name String @db.VarChar(20)
5 createTime DateTime @default(now())
6 updateTime DateTime @updatedAt
7 employees Employee[]
8}
9
10
11model Employee {
12 id Int @id @default(autoincrement())
13 name String @db.VarChar(20)
14 phone String @db.VarChar(30)
15 departmentId Int
16 department Department @relation(fields: [departmentId], references: [id])
17}
18
19
20model Post {
21 id Int @id @default(autoincrement())
22 title String
23 content String?
24 published Boolean @default(false)
25 tags TagOnPosts[]
26}
27
28
29model Tag {
30 id Int @id @default(autoincrement())
31 name String
32 posts TagOnPosts[]
33}
34
35
36model TagOnPosts {
37 post Post @relation(fields: [postId], references: [id])
38 postId Int
39 tag Tag @relation(fields: [tagId], references: [id])
40 tagId Int
41 @@id([postId, tagId])
42}
- Department 模型:代表一个部门,包含基本信息和与员工的关联。部门可以有多个员工。
- Employee 模型:代表一个员工,包含基本信息和与部门的关联。每个员工属于一个部门。
- Post 模型:代表一个帖子,包含标题、内容和发布状态。帖子可以有多个标签。
- Tag 模型:代表一个标签,可以标记多个帖子。
- TagOnPosts 模型:是一个中间表模型,用于实现帖子和标签之间的多对多关系。每个记录都包含一个帖子和一个标签的关联。
使用枚举
定义枚举类型并在模型中使用:
1
2enum Role {
3 ADMIN,
4 USER,
5 GUEST
6}
7
8
9model Account {
10 id Int @id @default(autoincrement())
11 name String?
12 role Role @default(USER)
13}
生成文档
安装并配置额外的 generator,例如文档:
1npm install prisma-docs-generator -D
schema.prisma:
1generator docs {
2 provider = "node node_modules/prisma-docs-generator"
3 output = "../generated/docs"
4}
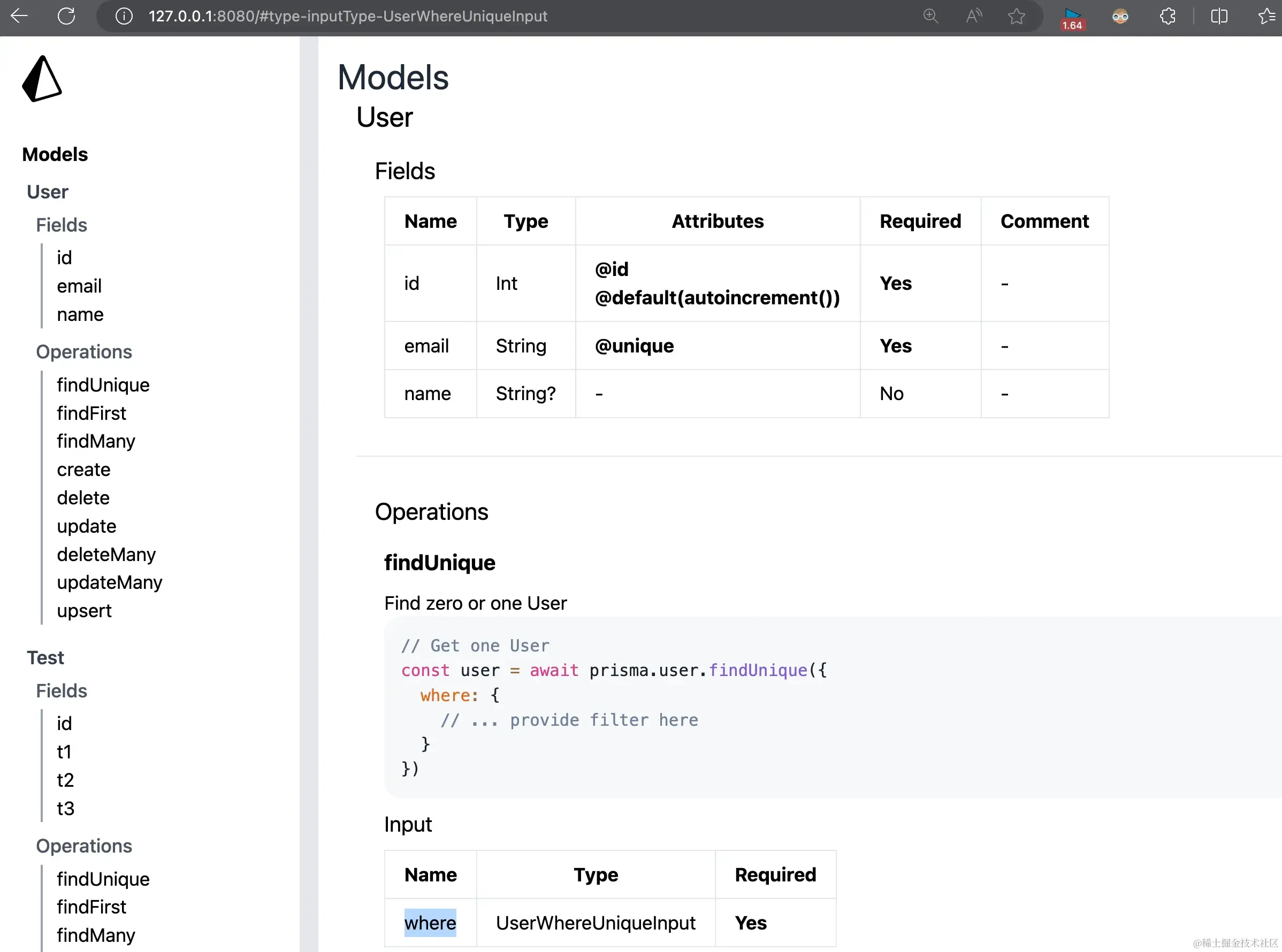
运行 npx prisma generate 生成文档。
查看生成的文档
使用 HTTP 服务器查看生成的文档:
1npx http-server ./generated/docs
文档中会列出所有模型的字段、CRUD 方法及其参数类型等:
总结
generator 部分可以指定多种生成器,比如生成 docs 等,可以指定生成代码的位置。
datasource 是配置数据库的类型和连接 url 的。
model 部分定义和数据库表的对应关系:
- @id 定义主键
- @default 定义默认值
- @map 定义字段在数据库中的名字
- @db.xx 定义对应的具体类型
- @updatedAt 定义更新时间的列
- @unique 添加唯一约束
- @relation 定义外键引用
- @@map 定义表在数据库中的名字
- @@index 定义索引
- @@id 定义联合主键
此外,还可以通过 enum 来创建枚举类型。
这些就是常用的 schema 语法了。