prisma
官网地址:Prisma | Simplify working and interacting with databases
什么是prisma?
Prisma(棱镜)是一个现代的开源数据库工具集,提供了一系列工具来简化数据库操作。主要用于Node.js和TypeScript环境,旨在提供一个强大、灵活且易于使用的数据库访问层
- 和我们上一章节用到的knex比起来,这是真正企业级的ORM工具。但不管是
Prisma还是Knex.js都是流行的ORM(对象关系映射)工具- 他们两者之间各有优势,
Prisma是企业级基本上就代表了没有Knex那么轻便 - 但不具备轻便性的同时也拥有了更多强大的功能(更现代、高级别抽象,且强调类型安全和简化的数据库操作)
- 和Knex一样具备支持多种主流数据库
- 他们两者之间各有优势,
- 通过官网的文档,我们也能够看到他对于自身的定义,以及他们名字Prisma所对应的
棱镜logo图标
prisma特点
- 类型安全:Prisma 提供
强类型的API,特别适合TypeScript开发者。这使得在开发过程中能够利用静态类型检查来减少错误。 - 易用性:Prisma 的客户端API设计得更加现代和直观。它简化了数据模型的设置和查询的编写,使得
数据库交互更加直接和简单。 - 自动生成的查询构建器:Prisma 自动生成的客户端API根据你的数据库模式提供具体的查询方法和属性,大大提高了开发效率。
- 数据库迁移工具:Prisma 提供了集成的数据库迁移工具(Prisma Migrate),这是一个非常强大的特性,可以帮助开发者以声明性的方式管理数据库模式。
- ORM (Object-Relational Mapping):
Prisma和knex一样是一个ORM工具,开发者可以使用简洁的代码操作数据库,而不需要写复杂的SQL语句。它将数据库的表映射成代码中的对象,让数据库操作更加直观和安全。
使用prisma
安装prisma CLI
1npm install prisma -g
- 使用了全局安装后,我们就能使用对应的专属命令:
prisma作为前缀开头,在我们不知道这一系列中都有哪些命令的时候,我们通过prisma --help来查看命令
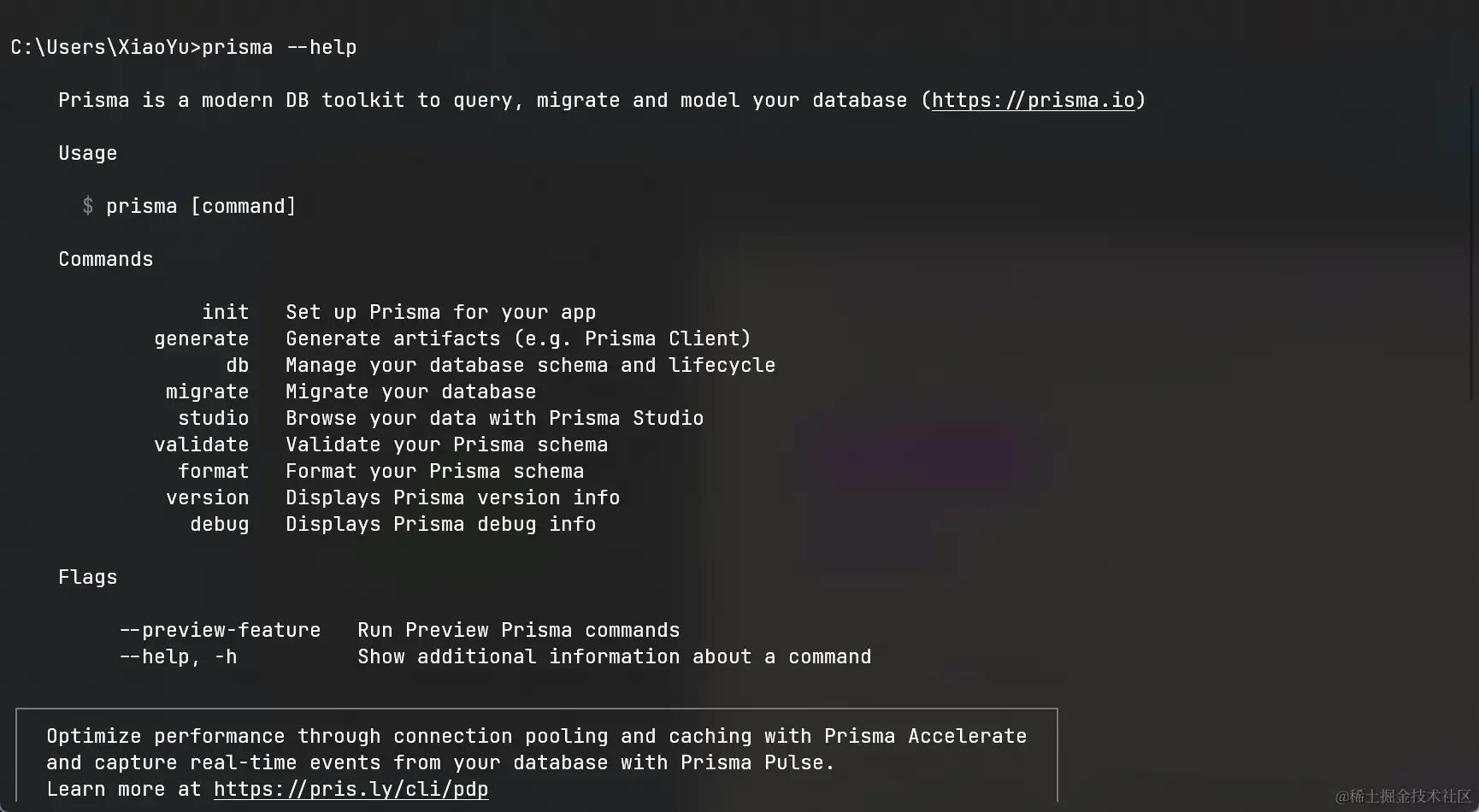
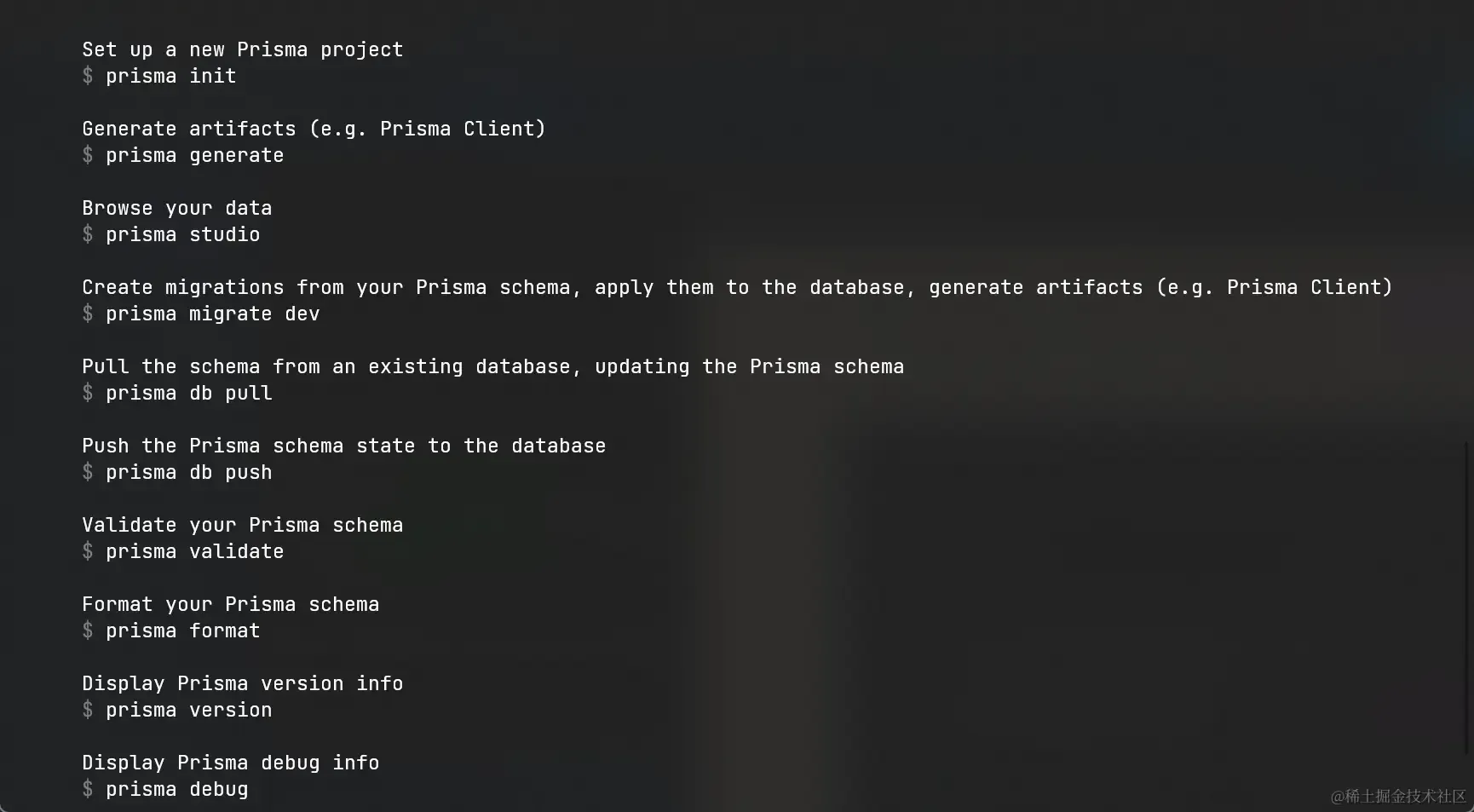
- 可以看到这个命令也是非常的丰富
- 命令是没有必要去背的,自己归纳总结起来,常用的自然就记住了,不常用的去背也没有任何意义,只需要知道去哪里查就行了。
- 我们在文章的末尾处会为大家将这些命令的作用总结起来作为归纳工具使用
初始化prisma
- 首先,我们通过help命令给出提示的,使用如下命令初始化项目:
- datasource:数据源
- provider:提供者
- 完整的意思就是,我通过prisma初始化了一个以mysql(提供者)作为数据源的项目
1prisma init --datasource-provider mysql
- 此时就会
创建生成基本目录
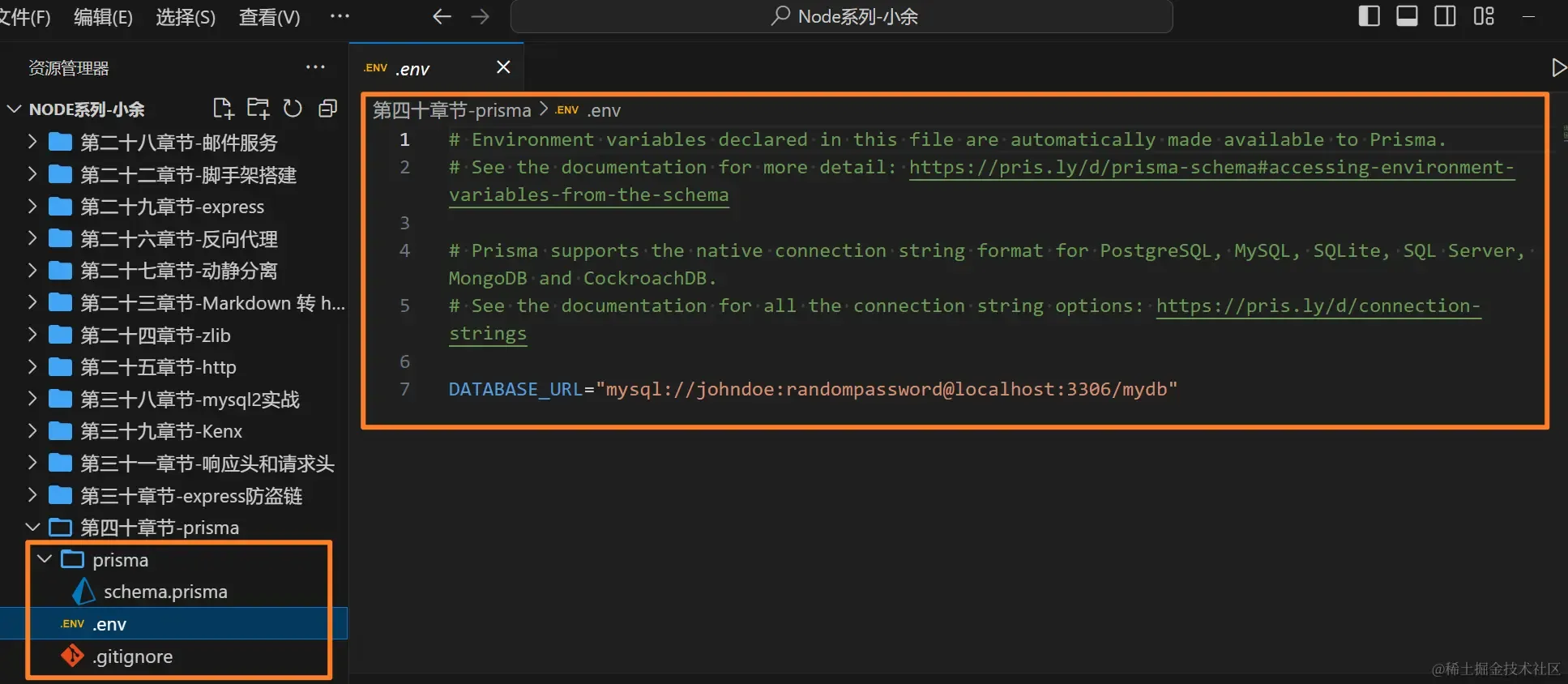
基础目录含义
schema.prisma:Prisma 的核心文件之一,包含数据库的模型定义,这些模型是数据库表的表示,用于定义表的结构、关系以及其他Prisma客户端API需要的配置信息- 也包含数据库连接器配置,这决定了 Prisma 如何连接到指定的数据库
- 还可以包含生成器配置,例如设置 Prisma 客户端或其他工具的生成选项
.env:Prisma 使用这个文件中定义的环境变量(如DATABASE_URL)来连接到数据库,而不需要在schema.prisma文件中直接暴露敏感信息.gitignore:git提交忽略文件,基本上算是创建项目必备文件了
1DATABASE_URL="mysql://root:root@localhost:3306/xiaoyu02"
代码高亮
- 我们的
schema.prisma核心编写文件后缀是专属后缀,一般情况下,vscode是没有高亮的,就像这样
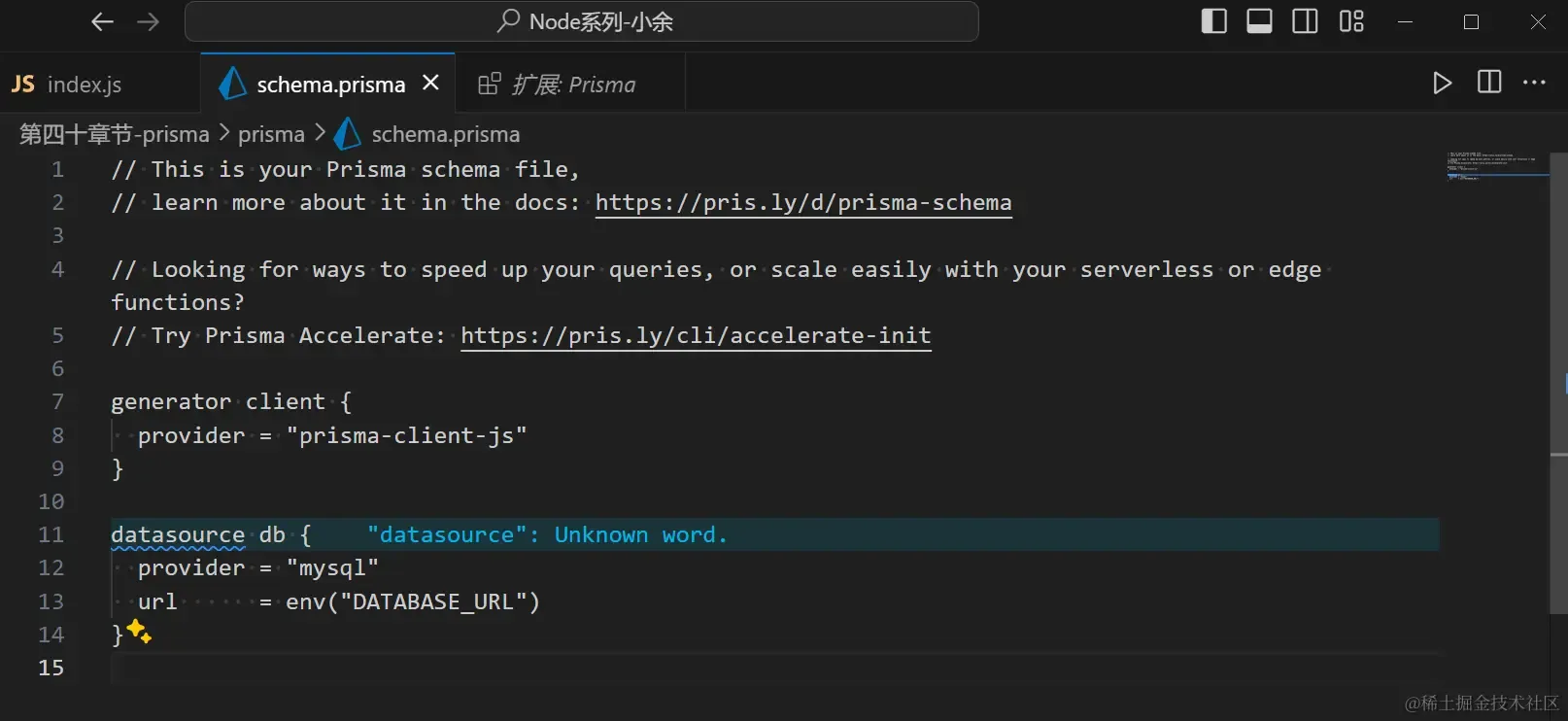
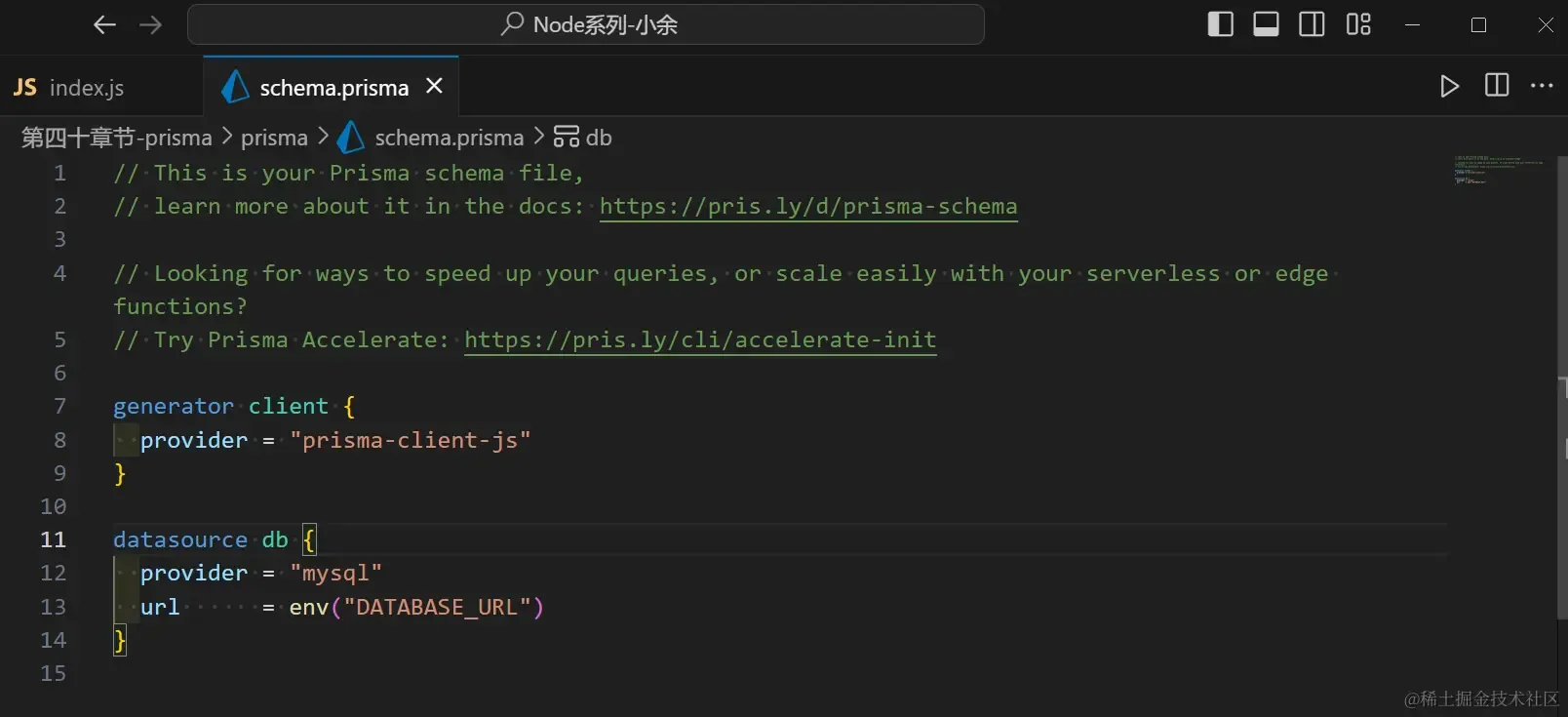
- 但这个问题是可以解决的,通过安装Prisma官方插件即可,在扩展商店直接搜索Prisma即可
- 此时我们的
schema.prisma核心文件即可进入高亮,正常编写代码
创建表
-
在我们通过
.env文件连接数据库之后,就可以开始创建表了-
这个流程其实跟前面knex是一模一样的:
连接数据库 => 创建表 => 对表本身进行增删改查操作
-
每一点都是依赖上一个环节的,所以顺序是不可以乱来的~,顺着思路逻辑来思考,更容易串联,如果
从侧边文件目录的初始化文件从上到下按顺序写下来的话,我觉得那个逻辑乱七八糟的,应该没人记得住这种奇怪的写法
-
-
通过
.env文件连接数据库后,我们进行下一步,创建表- 创建表等操作,都在
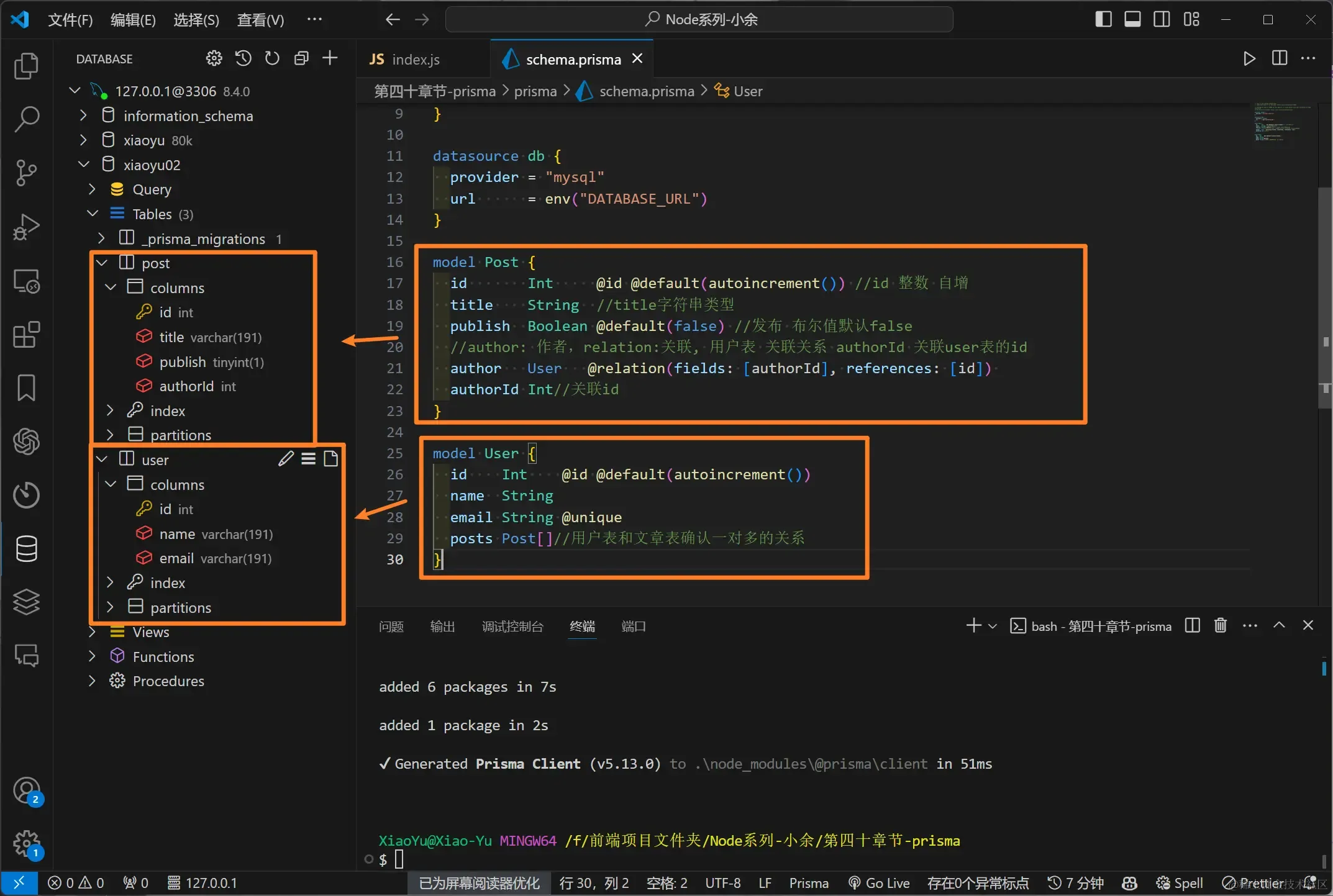
schema.prisma文件内 - 我们这里创建了两张表,分别是Post文章表和User用户表
- 在创建表的时候,我们看到了类似
TS装饰器写法,而这也是Prisma的强类型API体现
- 创建表等操作,都在
-
一个用户可以创建(对应)多篇文章,用户表中的**posts Post[]**写法就是实现此功能
- posts 是用户表本身字段(自由起名),
Post[]表示关联到多个Post实体,即多个文章记录 - 这里的[]数组形式来表示一对多关系,从本身意思就可以知晓其数组内部可以push多条数据的功能,且每一篇Post文章都是不同的(
id自增唯一标识),所以Post[]整体表达的意思就是:多篇文章,Post[]用数组形式来表示一对多关系,这表明一个User实例可以关联多个Post实例。
- posts 是用户表本身字段(自由起名),
1model Post {
2 id Int @id @default(autoincrement())
3 title String
4 content String
5 publish Boolean @default(false)
6
7 author User @relation(fields: [authorId], references: [id])
8 authorId Int
9}
10
11model User {
12 id Int @id @default(autoincrement())
13 name String
14 email String @unique
15 posts Post[]
16}Prisma 属性配置
- 对于上面的表结构是倾向于SQL创建表的情况,我们只需要额外了解对应的属性就能理解了
| 修饰符 | 描述 |
|---|---|
@id | 标识这个字段是模型的主键。 |
@default(...) | 为字段定义一个默认值,例如 autoincrement() 生成自增的ID,或为布尔值字段指定 false。 |
@unique | 确保该字段在表中的值唯一,常用于像 email 这样需要唯一性的字段。 |
@relation(...) | 指定模型间的关系,包括关联的字段和引用的字段。例如,定义外键和它应该参照的主键。 |
@updatedAt | 指示某个字段应该在记录被更新时自动设置为当前日期和时间。 |
| 方法 | 作用 |
| --- | --- |
autoincrement() | 用于为整数字段设置自动递增的主键。 |
now() | 设置字段的默认值为当前的日期和时间。 |
uuid() | 生成一个新的全局唯一标识符(UUID)作为默认值。 |
cuid() | 生成一个新的短字符串标识符,适用于具有较小存储需求的唯一标识。 |
dbgenerated() | 指示默认值由数据库在插入记录时自动生成。 |
通过上面的表格,我们可以举个例子:
1author User @relation(fields: [authorId], references: [id])
2authorId Int
- @relation:Prisma用于定义模型间关系的修饰符。它用于说明模型之间如何关联,并可以指定哪个字段作为连接点(即外键)。
- fields: [authorId]:指定了当前模型(
Post模型)中用于存储关联模型(User模型)主键的字段名是authorId。此字段在Post模型中充当外键,用于链接到User模型。 - references: [id]:指明了当前模型的外键
authorId引用了User模型的哪个字段——在这种情况下,是User模型的id字段。这说明了Post模型的authorId直接关联到User模型的id,建立了一个从多到一的关系(多个帖子可以对应一个用户)。
- fields: [authorId]:指定了当前模型(
生效表命令
- 表写完了并不是马上生效的,在Knex中,我们是运行了express的服务后生效。那目前在Prisma中,有他专属的命令
1Prisma migrate dev
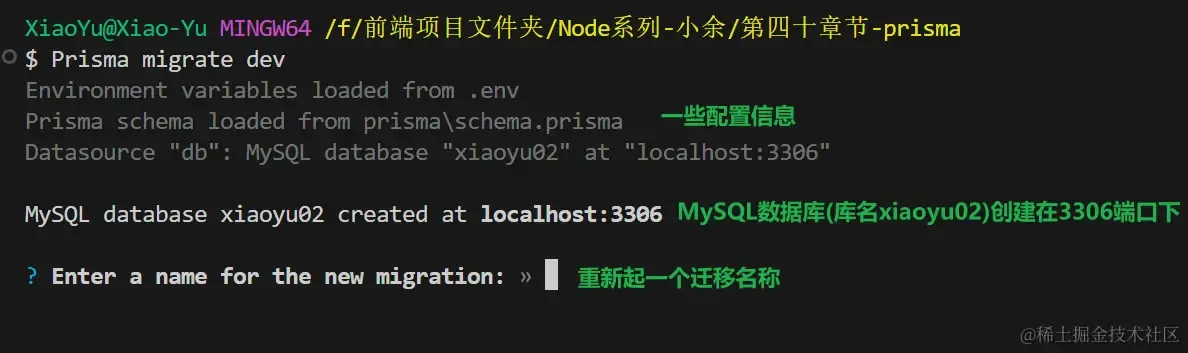
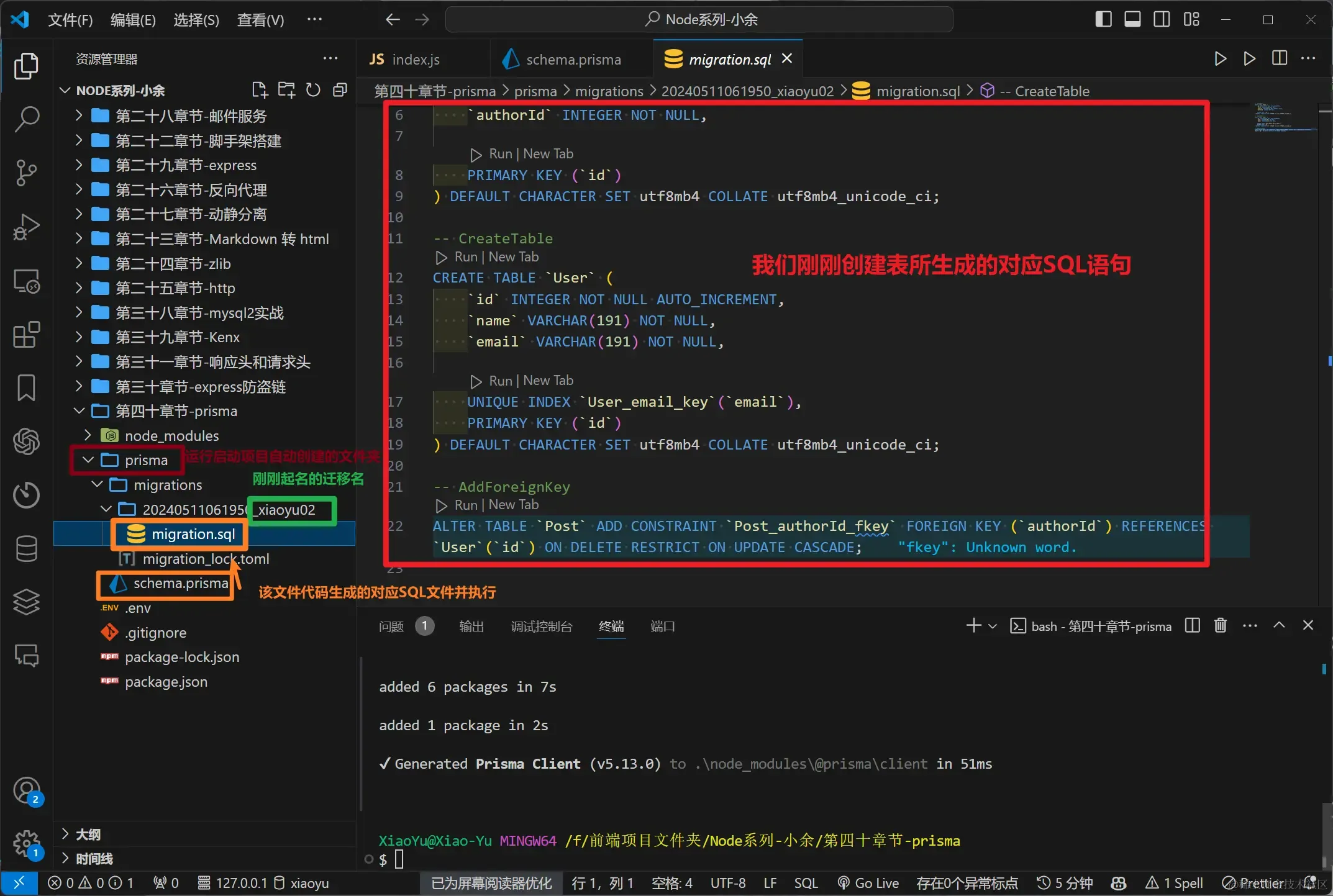
- 生成之后,会有以下几点改变:
- 在项目下自动创建
prisma文件夹,该文件夹下的migrations文件夹就会放着我们核心文件schema.prisma所生成的对应SQL文件,并执行 - 生成对应的package.json配置文件和lock锁文件,以及配套的
node_modules依赖 - 如果你该数据库中有内容,会直接覆盖掉原有内容(
不是替换)。所以我建议重新在.env起个新的数据库名,在运行项目的时候,会连着数据库都给你创建好
- 在项目下自动创建
强类型API的好处
通过上面初步创建表的用法而言,我们已经感受到了一点和之前使用
Knex进行创建表的不同了。那这样做有什么好处?Prisma为什么要采用这种方法而不是链式调用呢?
- 明确性和自文档化:直观的语法对于整体的结构会更加清晰,通过上面列出来的对比,我们发现
Prisma的写法更接近于原生SQL的格式,增加了代码的可读性和易维护性。 - 类型安全:使用类似
TypeScript的语法可以帮助 Prisma 客户端生成类型安全的代码,减少运行时错误,提高开发效率。
装饰器用法与链式调用的区别
- 两者之间不存在谁更优谁更劣的问题,他们各有自己所优秀的特点
- 声明性 vs 命令性:装饰器提供了一种声明性的方法来定义模型和设置属性,强调“什么”而非“如何”。而链式调用则更加命令性,强调执行的过程和步骤
- 结构化 vs 流程化:装饰器通过在定义时就确定所有属性,使得模型结构化清晰。链式调用则侧重于逐步构建查询或命令,流程化强,适合动态构建复杂查询
- 类型集成:Prisma 的模型装饰器语法直接与其类型生成系统集成,自动为每个模型和关联提供强类型支持,这在传统ORM的链式调用中可能需要额外的类型定义工作
初始化项目
-
第一步还是我们经常做的,先把对应需要的最基础文件夹和文件创建好
-
src文件夹:放源码的app.ts文件:写代码的主文件(这种是约定俗成的规范)- 同时需要在项目中安装
express以及对应的声明文件来配合Prisma使用:
1npm i express 2npm i --save-dev @types/express -
request.http文件:用来发送请求测试 -
tsconfig.json文件:通过tsc --init命令创建对应的TS配置文件(因为Prisma在TS方面很厉害,所以物尽其用)。如果没有tsc这个命令,说明没有安装typescript这个第三方库,安装一下就OK了,同时需要安装ts-node用来启动项目
1npm i typescript ts-node -g -
编写项目
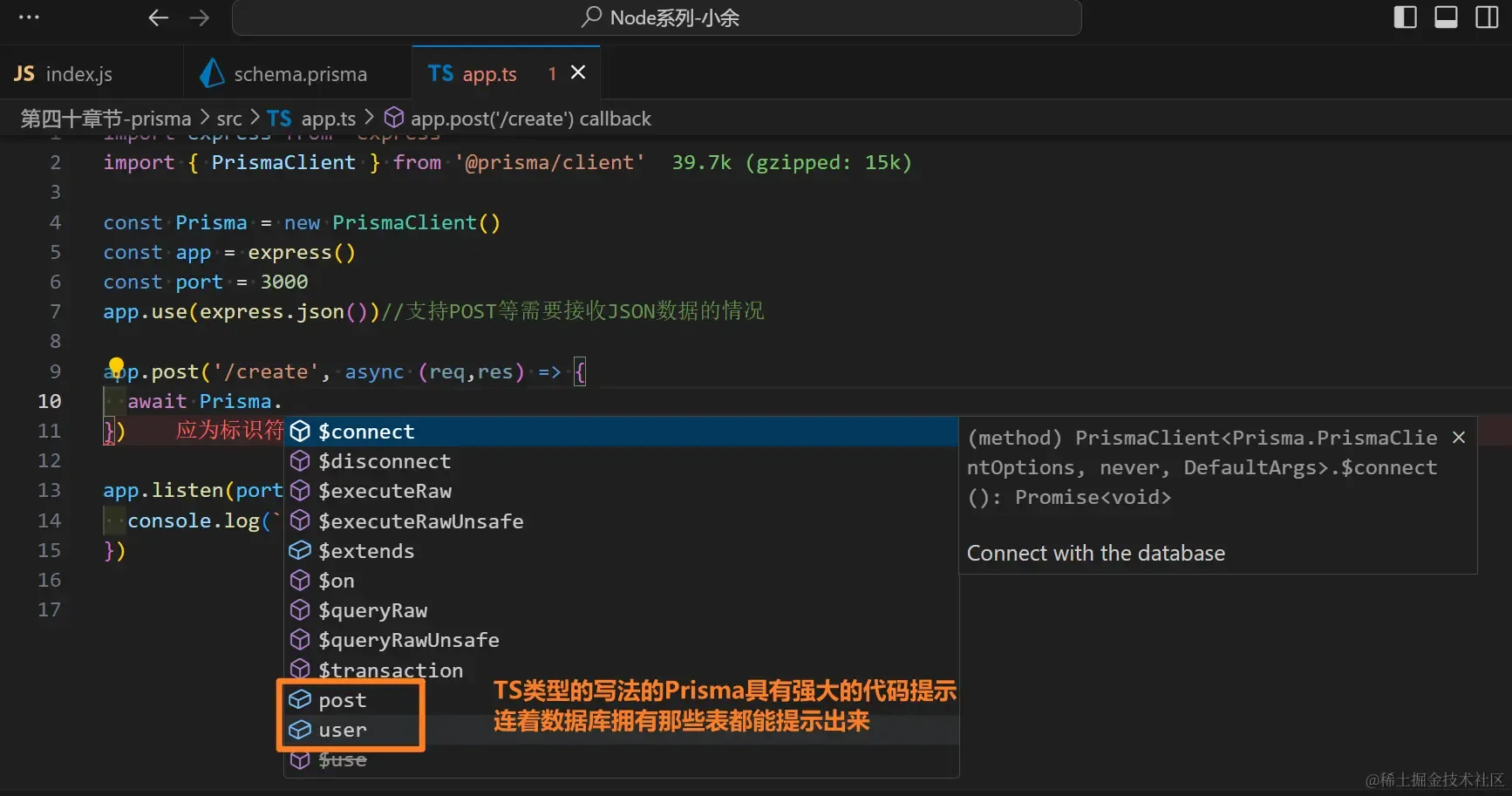
- 首先在src中的
app.js文件内导入对应的包,起一个服务- 我们能够看到
prisma和express是两种不同形式的使用方式 - 这两种形式分别对应了两种主流,也就是
类与函数。类的调用需要创建new实例,而函数不用,由此区分
- 我们能够看到
1import express from "express"
2import { PrismaClient } from '@prisma/client'
3
4const Prisma = new PrismaClient()
5const app = express()
6app.use(express.json())
7const port = 3000
8
9app.listen(port,()=>{
10 console.log(`端口:${port}服务已开启`);
11})
新增接口
- 在Knex中,我们通常使用链式调用的方式来编写数据库接口,这种方式以方法链的形式逐步构建查询。
- 相对地,Prisma采用了基于Promise的异步查询构建器,并且利用了TypeScript的强类型特性来增强代码的可读性和健壮性。使数据库操作接口的编写更加直观,接近声明式风格。Prisma的强类型系统不仅提供编译时错误检查,还大大增强了自动完成功能,开发更加高效。
- 在进行使用的时候,我们的主查询表和子查询表也可以嵌套起来,Prisma会进行解耦处理,并根据表之间的联系去进行处理数据
1app.post('/api/create', async (req, res) => {
2 const { name, email } = req.body
3 await Prisma.user.create({
4 data: {
5 name, email,
6 posts: {
7 create: [
8 {
9 title: '小余Node系列第一章-概述',
10 content: 'nodejs 并不是JavaScript应用,也不是编程语言,因为编程语言使用的JavaScript,Nodejs是JavaScript的运行时。',
11 publish: true
12 },
13 {
14 title: '小余Node系列第二章-安装',
15 content: '通常点击这里之后,Node官网会直接根据你的电脑环境,自动选择最适合你的版本,当然你也可以点击左上角的Download选项去下载你想要的其他版本',
16 publish: true
17 }
18 ]
19 }
20 }
21 })
22})
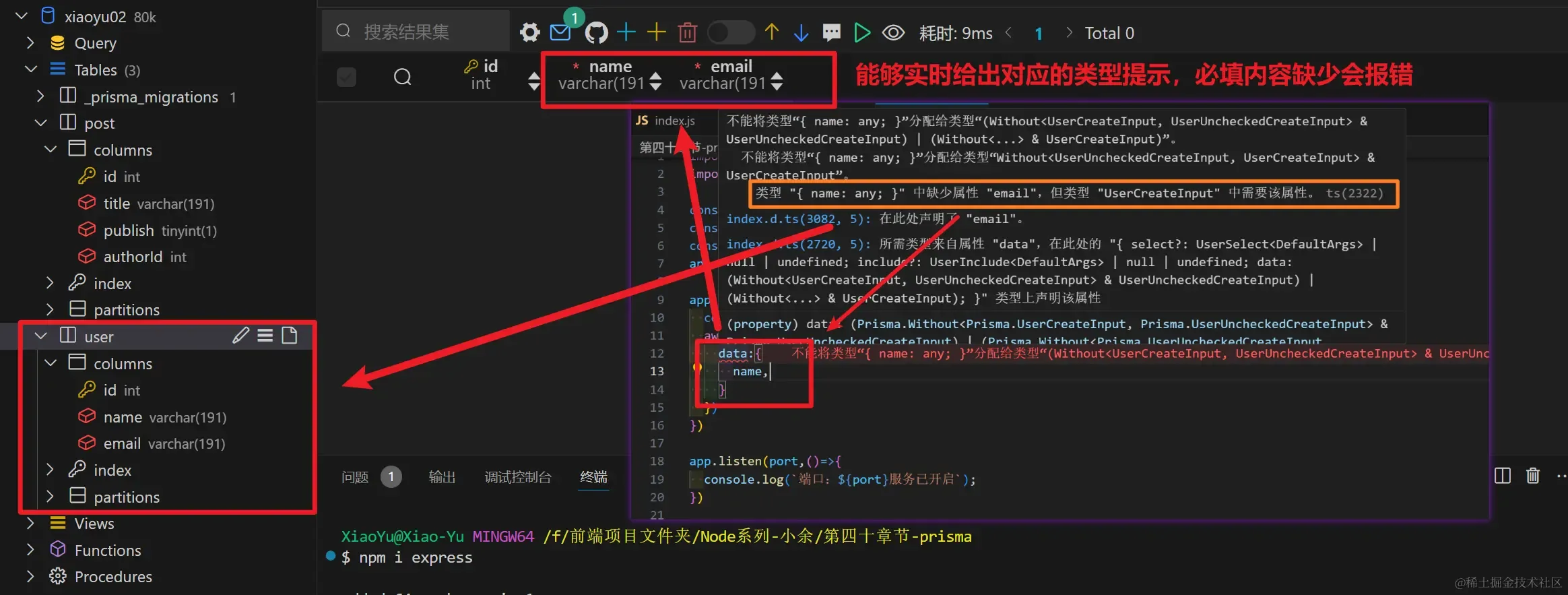
- 编写OK之后,我们通过运行express端口来执行命令
1nodemon src/app.ts
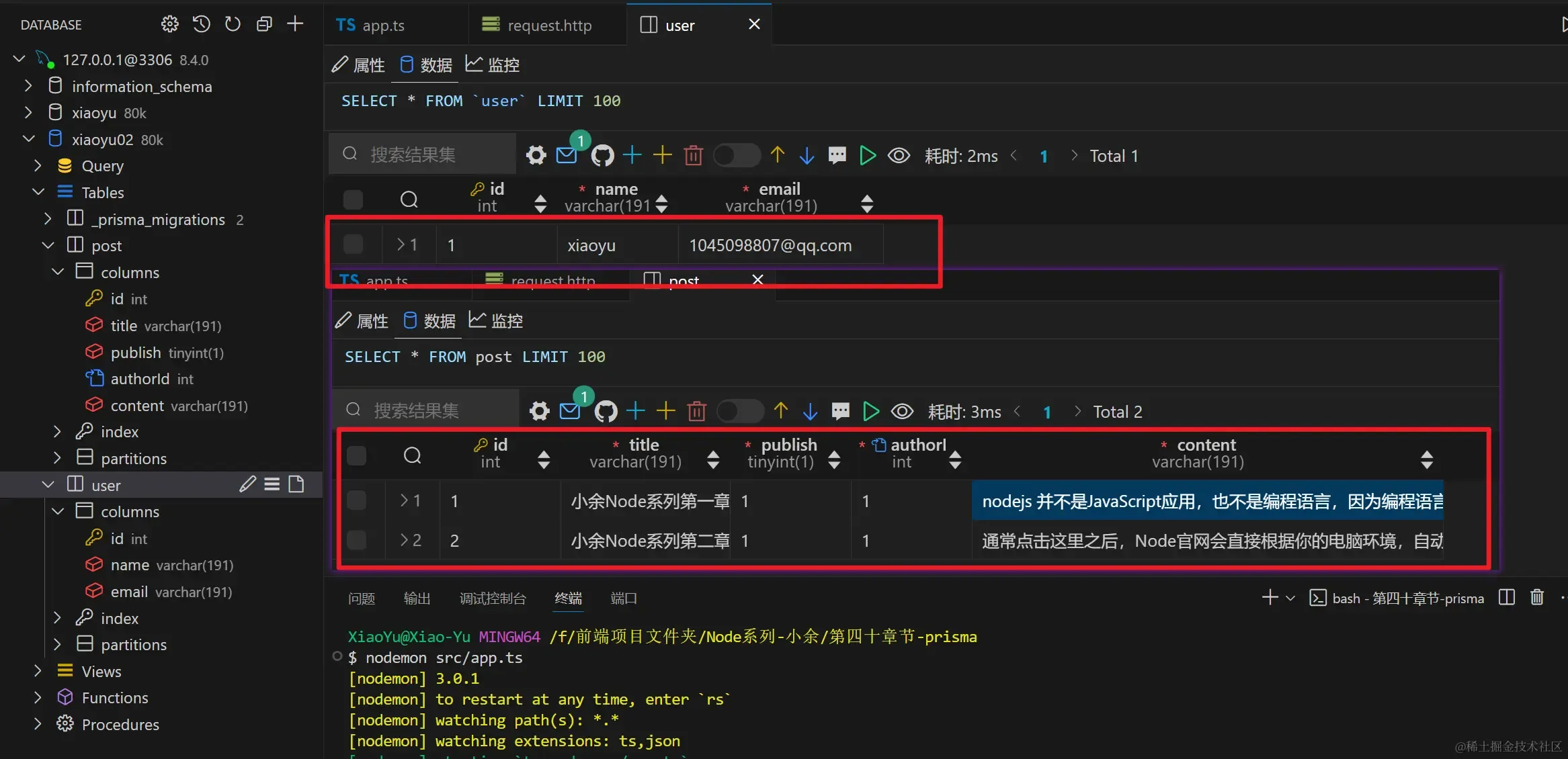
测试接口
- 使用
request.http文件发送请求测试
1POST http://localhost:3000/api/create HTTP/1.1
2Content-Type: application/json
3{
4 "name":"xiaoyu",
5 "email":"1045098807@qq.com"
6}
- 然后查看数据库,可以看到嵌套形式的新增内容,通过外键的联系,成功对两个表同时进行了输入
- 如果有更多的表进行串联起来,也可以进行更多层的嵌套
删改查接口
-
通过详细的讲解第一个新增接口后,剩下的接口也是同样逻辑,就变得简单了
-
我们能够看到Prisma在使用的时候,也是使用了模块化的思想:
Prisma.表名.操作({})的形式使其结构清晰明了,可读性强等优点 -
删除内容的时候,需要连着关联他的内容也一起删掉。这一样是优先度思想的逻辑,很像JS的垃圾回收机制,当没有内存指向内容的时候,内存才会被回收。而这里则是需要一起打包丢掉,或者你断掉两者的外键连接其实也行
-
但断掉两者的外键连接”实际上指的是在删除操作之前解除外键约束,这在实践中比较少见,因为通常我们希望保持数据的完整性。更常见的做法是在设计数据库模型时就定义好外键的行为,如设置 ON DELETE CASCADE(级联删除),从而在删除主记录时自动删除所有依赖的记录
-
1app.get('/api/search', async (req, res) => {
2 const data = await Prisma.user.findMany({
3
4 include: {
5 posts: true
6 }
7 })
8 res.json(data)
9})
10
11
12app.get('/api/user/:id', async (req, res) => {
13 const row = await Prisma.user.findUnique({
14
15 where: {
16 id: Number(req.params.id)
17 },
18 include: {
19 posts: true
20 }
21 })
22 res.json(row)
23})
24
25
26app.post('/api/update', async (req, res) => {
27 const { id, name, email } = req.body
28 const data = await Prisma.user.update({
29 where: {
30 id: Number(id)
31 },
32 data: {
33 name,
34 email
35 }
36 })
37 res.json(data)
38})
39
40
41app.post('/api/delete', async (req, res) => {
42 const { id } = req.body
43 await Prisma.post.deleteMany({
44 where: {
45 authorId: Number(id)
46 }
47 })
48 const data = await Prisma.user.delete({
49 where: {
50 id: Number(id)
51 }
52 })
53 res.json(data)
54})
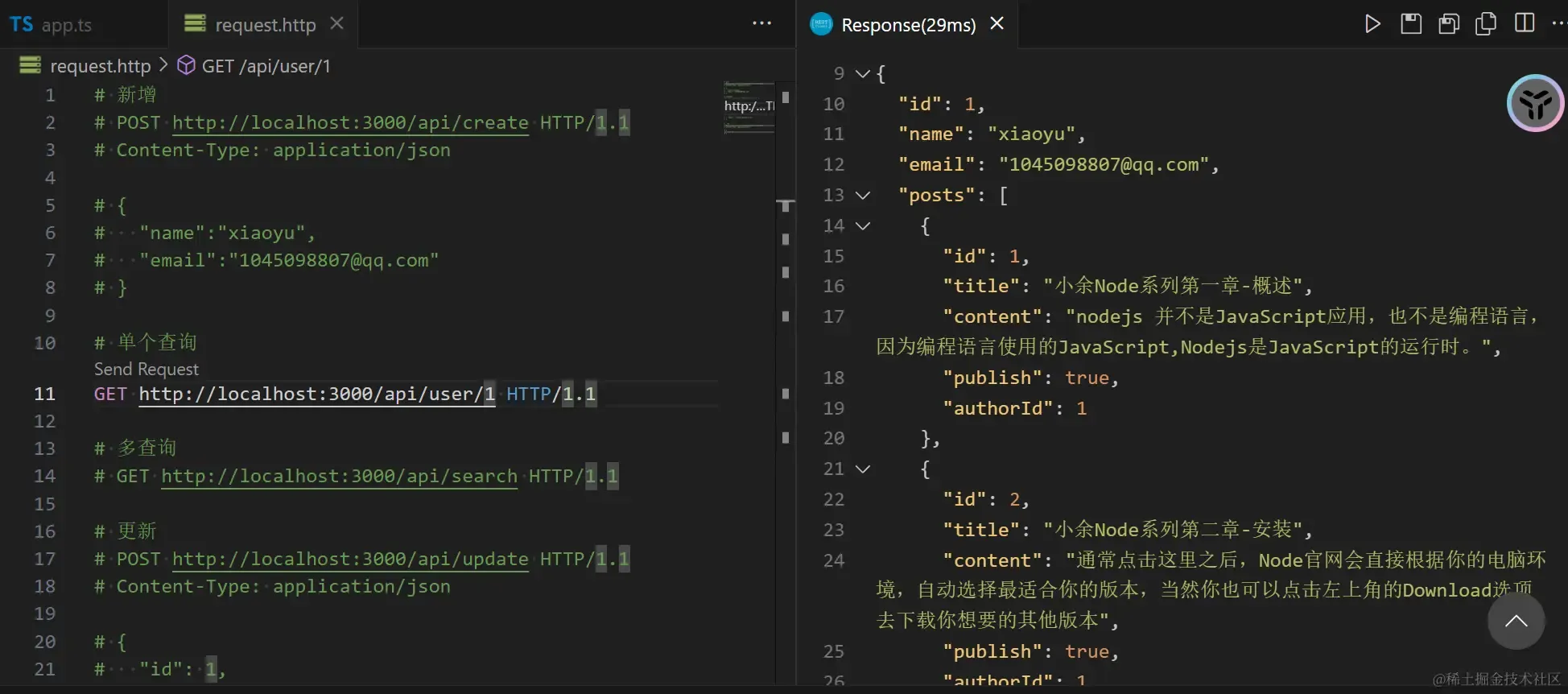
测试接口
- 剩下的接口就自己进行测试就好了
1# 单个查询
2GET http://localhost:3000/api/user/1 HTTP/1.1
3
4# 多查询
5# GET http://localhost:3000/api/search HTTP/1.1
6
7# 更新
8# POST http://localhost:3000/api/update HTTP/1.1
9# Content-Type: application/json
10
11# {
12# "id": 1,
13# "name": "新名字",
14# "email": "newemail@example.com"
15# }
16
17
18# 删除
19# POST http://localhost:3000/api/delete HTTP/1.1
20# Content-Type: application/json
21
22# {
23# "id": 1
24# }
Prisma增删改查API
- 在上面的使用中,有些最常见的API使用,也是很好理解的,在这里进行汇总讲解
- 这些方法通过 Prisma 的客户端API调用,并结合异步操作(使用
async/await)
- 这些方法通过 Prisma 的客户端API调用,并结合异步操作(使用
| 方法 | 作用描述 |
|---|---|
create | 创建新记录。允许在一个操作中插入新数据到数据库表中。 |
findMany | 检索多条记录。用于获取满足特定条件的所有记录。 |
findUnique | 检索唯一记录。用于获取单个唯一记录,通常基于主键或唯一字段。 |
update | 更新现有记录。允许修改数据库中的现有记录。 |
delete | 删除记录。用于从数据库中删除一条记录。 |
deleteMany | 删除多条记录。用于删除满足特定条件的所有记录。 |
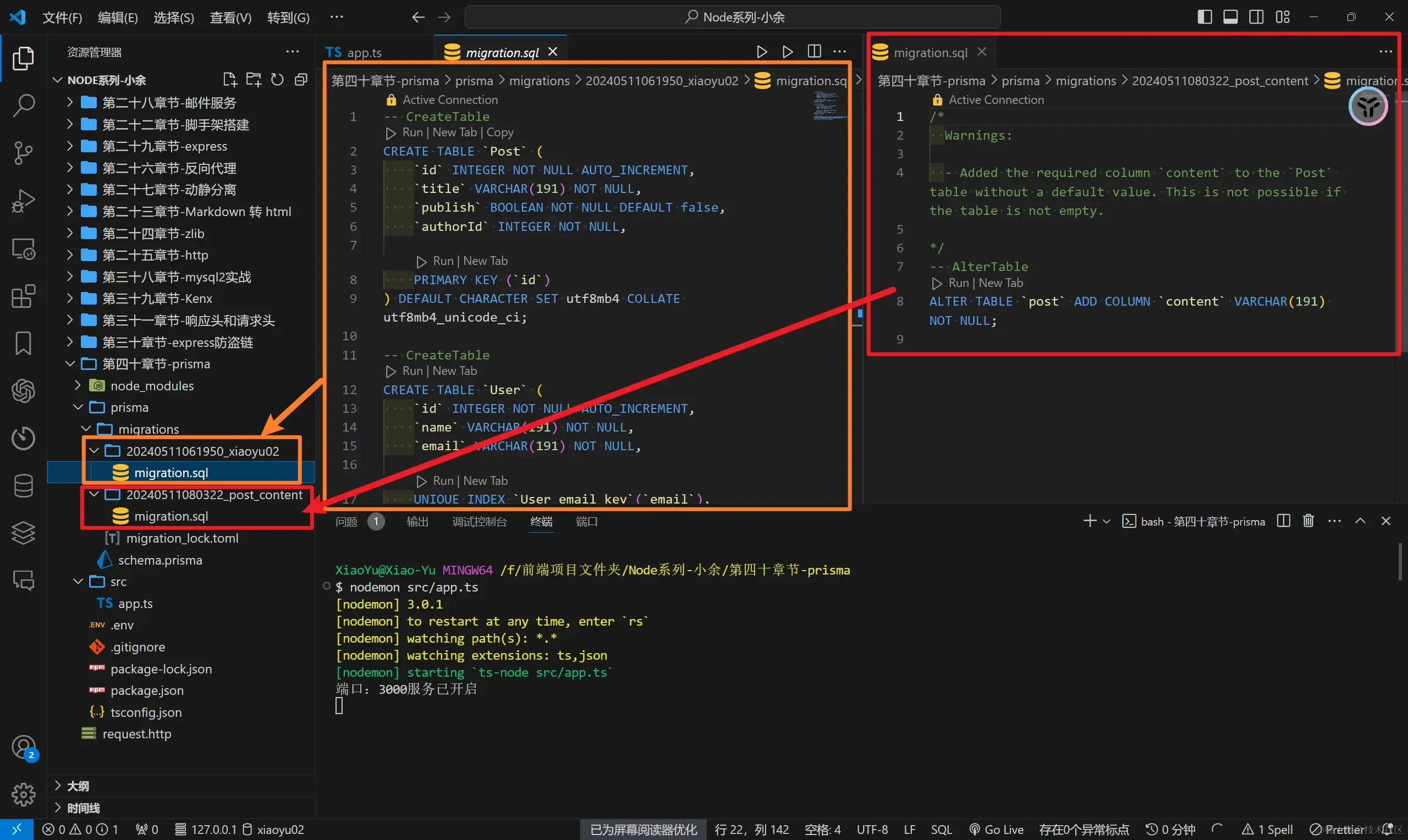
补充
- 在我们代码中,有一个很强大的功能没有提现到,那就是当我们在
schema.prisma核心文件进行其他操作的时候,重新运行Prisma启动命令,是会重新发起操作的,对其中多出来的操作进行实现和记录 - 这里多出来的记录,会以
时间戳+操作命名的方式,继续放在migrations文件夹中。这个操作的思想和逻辑是和Git很像的,而其中的好处也是类似
- 版本控制和可追踪性:
- 明确的历史记录:每个迁移文件都记录了数据库模式的一次具体更改,这与Git提交日志类似。开发者可以清楚地看到数据库结构随时间的变化。
- 回退能力:如果最新的迁移引入了问题,可以轻易地回退到前一个稳定的数据库结构版本,这与Git的回退功能相似。
- 团队协作:
- 避免冲突:迁移文件的时间戳和描述性名称减少了多人开发时迁移之间的冲突。每个开发者都在独立的文件中工作,合并变更时冲突的可能性较低。
- 一致性保证:所有团队成员应用相同的迁移可以确保每个人的本地开发环境与生产环境保持一致。
- 自动化和安全性:
- 自动化迁移:Prisma的迁移命令可以自动应用所有待处理的迁移,确保数据库结构的正确更新,这减少了人为操作数据库结构的错误。
- 审核和回顾:迁移文件可以被审查和包含在代码审查流程中,这提高了更改的可见性和安全性。
- 文档化:
- 自我记录的变更:迁移文件本身就是对数据库架构更改的文档,新团队成员可以通过查看这些文件来理解数据库的演进。