2024.08.17 - 2024.08.25 更新前端面试问题总结(20 道题)
获取更多面试相关问题可以访问
github 地址: https://github.com/pro-collection/interview-question/issues
gitee 地址: https://gitee.com/yanleweb/interview-question/issues
目录:
-
中级开发者相关问题【共计 8 道题】
- 835.[React] 类组件中,为什么修改状态要使用 setState 而不是用 this.state.xxx = xxx【热度: 414】【web 框架】【出题公司: TOP100 互联网】
- 836.proxy 能够监听到对象中的对象的引用吗?【热度: 112】【JavaScript】【出题公司: TOP100 互联网】
- 842.在创建对象的时候, new class 和 new function 可有什么区别【热度: 447】【JavaScript】【出题公司: 百度】
- 843.[vue] scope 是怎么做的样式隔离的【热度: 126】【web 框架】【出题公司: 京东】
- 844.JS 数据类型里面, Set 和 数组分别有哪些适用场景,开发中该如何抉择【热度: 333】【JavaScript】【出题公司: 美团】
- 848.介绍一下 fetch 请求 keepalive 属性【热度: 112】【网络】
- 849.介绍一下 navigator.sendBeacon 方法【热度: 66】【web 应用场景】
- 850.如何判断用户设备【热度: 551】【web 应用场景】【出题公司: 阿里巴巴】
-
高级开发者相关问题【共计 11 道题】
- 837.[webpack] 手写一个 plugin, 统计源码里面的 console.log 调用数量与调用路径【热度: 113】【工程化】【出题公司: 美团】
- 838.[webpack] 手写 webpack plugin 有那些重要 api 与注意的地方?【热度: 714】【工程化】【出题公司: 美团】
- 839.[webpack] 手写 loader: 我要在方法调用的时候, 上报调用源文件地址【热度: 117】【工程化】【出题公司: 阿里巴巴】
- 840.[webpack] 手写 webpack loader 有哪些重要 api 与注意事项?【热度: 718】【工程化】【出题公司: 阿里巴巴】
- 841.[webpack] 多个 loader 对同一个资源进行处理, 他们之间如何通信?【热度: 134】【工程化】【出题公司: 阿里巴巴】
- 845.介绍一下 TypeScript 类型兼容——逆变、协变、双向协变和不变 这四个概念【热度: 30】【TypeScript】
- 846.混动跟随导航(电梯导航)该如何实现【热度: 498】【web 应用场景】
- 847.退出浏览器之间, 发送积压的埋点数据请求, 该如何做【热度: 134】【web 应用场景】
- 851.如何统计页面的 long task(长任务)【热度: 140】【web 应用场景】【出题公司: 腾讯】
- 852.PerformanceObserver 如何测量页面性能【热度: 190】【web 应用场景】【出题公司: 百度】
- 853.移动端如何实现下拉滚动加载(顶部加载)【热度: 740】【web 应用场景】
-
资深开发者相关问题【共计 1 道题】
- 854.如何组织工程项目【热度: 517】【web 应用场景】【出题公司: 阿里巴巴】
835.[React] 类组件中,为什么修改状态要使用 setState 而不是用 this.state.xxx = xxx【热度: 414】【web 框架】【出题公司: TOP100 互联网】
关键词:react state 问题
在 React 类组件中,状态(state)是组件的局部状态,你可以通过调用 setState 方法来异步更新组件的状态。有几个重要原因解释了为什么在 React 类组件中应该使用 setState 而不是直接修改 this.state:
1. 保证状态的不可变性(Immutability)
React 强烈建议开发人员保持状态(state)的不可变性。这意味着状态不应被直接修改,而应该通过创建一个新的状态对象来更新。直接修改 this.state 不遵循不可变性原则,这可能会导致未定义的行为和性能问题。
React 可能会将多个 setState 调用批量处理为一个更新,以优化性能。因为 setState 是异步的,所以这意呀着在调用 setState 之后立即读取 this.state 可能不会返回预期的值。如果直接修改 this.state,则无法利用 React 的异步更新和批量处理机制。
setState 方法不仅更新状态,而且还告诉 React 该组件及其子组件需要重新渲染,以反映状态的变化。直接修改 this.state 不会触发组件的重新渲染,因此即使状态发生了变化,用户界面也不会更新。
使用 setState 方法可以确保所有状态更新都有一个清晰、可预测的流程。这使得调试和理解组件的行为变得更加容易。同时,setState 还提供了一个回调函数,只有在状态更新和组件重新渲染完成后,这个回调函数才会被执行,这样就可以安全地操作更新后的状态。
当你调用 setState,React 会将你提供的对象合并到当前状态中。这是一种浅合并(shallow merge),意味着只合并顶层属性,而不会影响到嵌套的状态。这种行为让状态更新变得简单而直接。如果直接修改 this.state,则需要手动处理这种合并逻辑。
因为以上原因,建议遵循 React 的最佳实践,即通过 setState 方法而不是直接修改 this.state 来更新组件的状态。这样可以保证应用的性能、可维护性和可预测性。
836.proxy 能够监听到对象中的对象的引用吗?【热度: 112】【JavaScript】【出题公司: TOP100 互联网】
关键词:proxy 监听引用
是的,Proxy 能够监听到对象属性的读取和设置操作,包括对象中嵌套的对象的引用操作。但是,要注意的是,如果你想要监听一个嵌套对象内部的变化(例如,对象的属性或者数组的元素),那么你需要单独为这个嵌套对象也创建一个 Proxy 实例。因为 Proxy 只能直接监听它直接代理的对象的操作,对于嵌套对象的操作,需要嵌套地使用 Proxy 来实现深度监听。
举个例子:
1function createDeepProxy(obj) {
2 // 递归函数,为对象及其嵌套对象创建代理
3 const handler = {
4 get(target, property, receiver) {
5 const value = Reflect.get(target, property, receiver);
6 if (typeof value === "object" && value !== null) {
7 // 如果属性是对象(且非 null),则为该属性也创建代理
8 return createDeepProxy(value);
9 }
10 return value;
11 },
12 set(target, property, value, receiver) {
13 console.log(`Setting property ${property} to ${value}`);
14 return Reflect.set(target, property, value, receiver);
15 },
16 };
17
18 return new Proxy(obj, handler);
19}
20
21const original = { name: "John", address: { city: "New York" } };
22
23const proxied = createDeepProxy(original);
24
25proxied.address.city = "San Francisco"; // 控制台输出:Setting property city to San Francisco
26console.log(original.address.city); // 输出 San Francisco在这个例子中,createDeepProxy 函数使用了递归,为对象及其所有嵌套对象创建了 Proxy 代理。因此,修改嵌套对象 address 下的 city 属性时,set 陷阱(trap)被触发,并且控制台有相应的输出。但注意这种递归创建 Proxy 的做法可能会带来性能问题,特别是在处理有很深嵌套结构或者很大的对象时。
此外,需要留意的是,由于每次访问嵌套对象时都会动态创建新的 Proxy 实例,这可能导致一些意料之外的行为,比如基于身份的比较或引用检查可能会失败。因此,在实际应用中,应根据需求精心设计 Proxy 的使用方式。
842.在创建对象的时候, new class 和 new function 可有什么区别【热度: 447】【JavaScript】【出题公司: 百度】
关键词:创建对象实例
在 JavaScript 中,使用new操作符创建对象时,既可以使用类(class)也可以使用构造函数(function)。二者都可以用来实例化新的对象,但它们之间存在一些关键的区别和相似之处:
当使用new操作符时,JavaScript 会执行以下步骤:
- 创建一个全新的空对象。
- 将这个空对象的原型(
__proto__)设置为构造函数的prototype属性。 - 将
this绑定到新创建的对象上,以便构造函数可以引用它。 - 执行构造函数内的代码(对新对象进行初始化)。
- 如果构造函数返回一个对象,则返回该对象;否则,返回刚才创建的新对象。
- 在使用函数时,实际上是在使用函数构造器模式。这个函数充当构造函数的角色,定义了如何初始化新对象的属性和方法。
1function Person(name, age) {
2 this.name = name;
3 this.age = age;
4}
5Person.prototype.greet = function () {
6 console.log("Hello, my name is " + this.name + " and I am " + this.age + " years old.");
7};
8const person1 = new Person("Alice", 30);
9person1.greet(); // 输出: Hello, my name is Alice and I am 30 years old.- ES6 引入了类语法(
class),使得基于类的面向对象编程在语法上更加清晰和直观。类的内部工作原理与使用构造函数的模式相似,但提供了更丰富的语法和特性,比如基于类的继承等。
1class Person {
2 constructor(name, age) {
3 this.name = name;
4 this.age = age;
5 }
6 greet() {
7 console.log(`Hello, my name is ${this.name} and I am ${this.age} years old.`);
8 }
9}
10const person2 = new Person("Bob", 25);
11person2.greet(); // 输出: Hello, my name is Bob and I am 25 years old.- 语法和语义:
class提供了一种清晰、模块化的方式来定义构造函数和原型方法。通过class关键字声明类使得代码更加直观易懂。 - 继承:使用
class语法,可以通过extends关键字更加简洁地实现继承。而在传统的函数式继承中,需要手动设置原型链。 - 严格模式:使用
class语法定义的类的方法自动运行在严格模式下("use strict"),而传统的构造函数则需要手动声明。 - 构造函数和原型方法的声明:
class语法使得构造函数和原型方法的声明更加直观和组织化,而在传统的构造函数中,需要分别设置构造函数的属性和其原型的方法。
虽然new function()和new class都可以用来创建新的对象实例,但class提供了更现代、更丰富的语法和特性,使得代码更加直观、易于管理和维护。然而,重要的是理解两者在 JavaScript 底层使用相同的原型继承机制。
843.[vue] scope 是怎么做的样式隔离的【热度: 126】【web 框架】【出题公司: 京东】
关键词:vue 样式个例
Vue 中的样式隔离是通过 Vue 单文件组件(Single File Components,简称 SFC)的 <style> 标签中的 scoped 属性实现的。当你在一个 Vue 组件的 <style> 标签上添加 scoped 属性时,Vue 会自动将该样式限定在当前组件的范围内,从而防止样式冲突和不必要的样式泄漏。
Vue 在编译带有 scoped 属性的 <style> 标签时,会按照以下步骤处理样式隔离:
-
生成唯一的作用域 ID:Vue 为每个带有
scoped属性的组件生成一个唯一的作用域 ID(如data-v-f3f3eg9)。这个 ID 是随机的,确保每个组件的作用域 ID 是独一无二的。 -
添加作用域 ID 到模板元素:Vue 会在编译组件模板的过程中,将这个作用域 ID 作为自定义属性添加到组件模板的所有元素上。例如,如果作用域 ID 是
data-v-f3f3eg9,那么在该组件模板的所有元素上都会添加一个属性data-v-f3f3eg9。 -
修改 CSS 选择器:对于组件内部的每个 CSS 规则,Vue 会自动转换其选择器,使其仅匹配带有对应作用域 ID 的元素。这是通过在 CSS 选择器的末尾添加相应的作用域 ID 属性选择器来实现的。例如,如果 CSS 规则是
.button { color: red; },并且作用域 ID 是data-v-f3f3eg9,那么该规则会被转换成.button[data-v-f3f3eg9] { color: red; }。
假设有如下 Vue 单文件组件:
1<template>
2 <button class="btn">Click Me</button>
3</template>
4
5<style scoped>
6.btn {
7 background-color: red;
8}
9</style>编译后,CSS 规则会变成类似于这样(注意:实际的作用域 ID 是随机生成的):
1.btn[data-v-f3f3eg9] {
2 background-color: red;
3}并且模板里的 <button> 元素会被编译为类似这样:
1<button class="btn" data-v-f3f3eg9>Click Me</button>这样,.btn 样式规则只会应用到当前组件中的 <button> 元素上,而不会影响到其他组件中的同类元素,实现了样式隔离。
- 由于样式隔离是通过属性选择器和自定义属性实现的,因此这种方法的性能可能会略低于全局样式规则。
scoped样式不能影响子组件,仅限于当前的组件。如果需要影响子组件,则需要使用深度选择器(>>>或/deep/)。- 其他 Web 组件技术如 Shadow DOM 也可以提供样式隔离的功能,但 Vue 选择了这种不需要 polyfill、兼容性更好的实现方式。
844.JS 数据类型里面, Set 和 数组分别有哪些适用场景,开发中该如何抉择【热度: 333】【JavaScript】【出题公司: 美团】
关键词:Set 和 数组 适用场景
在 JavaScript 中,Set和数组(Array)都是用来存储一系列数据的集合,但它们具有不同的特性和适用场景。了解这些差异可以帮助你在特定情况下做出更合适的选择。
特性:
Set是一种新的数据结构,被引入在 ES6 中。- 它类似于数组,但是成员的值都是唯一的,没有重复的值。
- 提供了简单的方法来进行添加(
add)、删除(delete)、检查(has)成员,以及获取集合大小(size)。 - 不支持索引访问(例如,
set[0]是不可能的),因此不适于通过索引获取或操作元素的场景。 - 对集合元素的迭代相对简单,有
values()、keys()(与values()相同)和entries()方法,以及forEach方法。
适用场景:
- 当你需要存储唯一值的集合时,比如集合、标签、关键字等。
- 当你需要高效地进行存在性检查(是否包含某个元素)时。
- 当你不需要元素的索引和顺序访问,或者添加和删除操作比查找和访问操作更频繁时。
特性:
- 数组是 JavaScript 中最基本的数据结构之一。
- 数组中的元素可以通过索引进行访问,提供了广泛的方法来进行遍历、映射(
map)、过滤(filter)、归并(reduce)等操作。 - 数组中可以包含重复的值。
- 数组的长度是可变的,可以通过
push、pop等方法动态地添加或移除元素。
适用场景:
- 当你需要通过索引访问元素时,数组提供了方便的方法。
- 当集合中允许存在重复的元素时。
- 当你需要使用一系列数组特有的方法操作数据时,比如
map、filter、reduce等。 - 当你需要对数据进行排序,或需要保持元素的添加顺序时。
选择Set还是数组主要取决于你的具体应用场景:
- 唯一性:如果你需要确保一个集合中元素的唯一性,那么
Set是一个更好的选择。 - 查找和删除:如果你需要高效的查找和删除操作,而且元素的唯一性很重要,
Set提供更优的性能。 - 索引访问和顺序:如果你需要通过索引来频繁访问或更新元素,或者需要对元素进行排序,那么数组会是更合适的选择。
- 数据处理:如果你需要对集合进行复杂的数据处理,比如映射、过滤、归并等操作,数组提供了丰富的方法来支持这些。
在设计你的应用或功能时,考虑数据结构的这些特性和适用场景,可以帮助你作出更合适、更高效的决策。
848.介绍一下 fetch 请求 keepalive 属性【热度: 112】【网络】
关键词:fetch keepalive 属性
keepalive 选项在 fetch 请求中的作用主要是允许在浏览器即将关闭或者用户即将离开当前页面时,仍然能够成功发送网络请求。这个选项的设计初衷是为了处理那些需要在页面生命周期结束时发送的统计或追踪数据的场景,比如用户的行为追踪数据、性能数据等。
-
异步发送:
keepalive选项允许请求在后台异步发送,即使在unload或beforeunload事件中触发。这确保了页面卸载过程不会因等待数据发送而延迟。 -
请求不会阻止页面关闭:使用了
keepalive选项的请求不会阻止浏览器关闭页面,提升了用户体验。 -
数据量限制:为了保证功能的有效性和避免滥用,
keepalive请求的数据大小有限制。最新的浏览器通常限制请求体的大小在 64KB 左右。 -
用例限制:考虑到
keepalive选项设计的是为了处理小量且关键的数据,比如统计和追踪数据,因此它并不适合用于发送大量数据。
以下是如何在 fetch 请求中使用 keepalive 选项的例子:
1window.addEventListener("beforeunload", (event) => {
2 // 构造你想要发送的数据
3 const data = {
4 // ...一些追踪数据
5 };
6
7 // 发送请求到服务器
8 fetch("https://yourserver.com/api/track", {
9 method: "POST",
10 body: JSON.stringify(data),
11 headers: {
12 "Content-Type": "application/json",
13 },
14 keepalive: true, // 使用 keepalive 选项
15 });
16});这种方法非常适合收集页面关闭前的最后一些用户行为数据,以便于更准确地追踪用户在网页上的活动和体验。但要记住,keepalive 选项应当谨慎使用,并确保发送的数据量不会超过浏览器的限制。
849.介绍一下 navigator.sendBeacon 方法【热度: 66】【web 应用场景】
关键词:sendBeacon 发送请求
navigator.sendBeacon() 方法使得网页可以异步地将数据发送到服务器,与页面的卸载过程同时进行,这一点非常重要,因为它允许在不影响用户体验的情况下,安全地结束会话或者发送统计数据。这方法主要用于追踪和诊断信息,特别是在需要确保数据被成功发送到服务器的场景中——比如记录用户在网页上的行为数据。
1navigator.sendBeacon(url, data);-
url:一个字符串,代表您想要发送数据到的服务器地址。 -
data:可选参数,要发送的数据。可以是ArrayBufferView、Blob、DOMString、或者FormData对象。 -
该方法返回一个布尔值:如果浏览器成功地将请求入队进行发送,则返回
true;如果请求因任何原因未能入队,则返回false。
- 异步:
sendBeacon()发送的请求是异步的,不会阻塞页面卸载过程或者延迟用户浏览器的关闭操作。 - 小数据量:适用于发送少量数据,如统计信息和会话结束信号。
- 不影响关闭:它允许在页面卸载或关闭时发送数据,而不会阻止或延迟页面的卸载过程。
- 可靠:它确保数据能够在页面退出时被送出,相较于
beforeunload或unload事件中使用同步的XMLHttpRequest更为可靠。
发送一些统计数据到服务器的简单示例:
1window.addEventListener("unload", function () {
2 var data = { action: "leave", timestamp: Date.now() };
3 navigator.sendBeacon("https://example.com/analytics", JSON.stringify(data));
4});在上面的例子中,当用户离开页面时,我们监听 unload 事件,并在该事件触发时使用 navigator.sendBeacon() 方法发送一些统计数据到服务器。使用 JSON.stringify(data) 将数据对象转换成字符串形式,因为 sendBeacon 需要发送的数据必须是文本或二进制形式。
- 虽然
navigator.sendBeacon()被现代浏览器广泛支持,但在使用前最好检查浏览器兼容性。 - 发送数据量有限制,一般适用于发送小量的数据。
- 某些浏览器实现可能有细微差异,建议在实际使用前进行充分测试。
通过使用 navigator.sendBeacon(),开发者可以确保在页面卸载过程中,重要的数据能够被可靠地发送到服务器,从而改善数据收集的准确性和用户体验。
850.如何判断用户设备【热度: 551】【web 应用场景】【出题公司: 阿里巴巴】
关键词:判断设备
在 Web 前端开发中,判断用户设备类型(如手机、平板、桌面电脑)主要依赖于用户代理字符串(User-Agent)和/或视口(Viewport)的尺寸。以下是一些常用方法:
用户代理字符串包含了浏览器类型、版本、操作系统等信息,可以通过分析这些信息来大致判断用户的设备类型。navigator.userAgent 属性用于获取用户代理字符串。
1function detectDevice() {
2 const userAgent = navigator.userAgent;
3
4 if (/mobile/i.test(userAgent)) {
5 return "Mobile";
6 }
7 if (/tablet/i.test(userAgent)) {
8 return "Tablet";
9 }
10 if (/iPad|iPhone|iPod/.test(userAgent) && !window.MSStream) {
11 return "iOS Device";
12 }
13 // Android, Windows Phone, BlackBerry 识别可以类似添加
14
15 return "Desktop";
16}
17
18console.log(detectDevice());有时候用户代理字符串可能不够准确或被修改,此时可以根据视口尺寸作为补充手段。通过检测屏幕的宽度,你可以推断出设备的大致类别。
1function detectDeviceByViewport() {
2 const width = window.innerWidth;
3
4 if (width < 768) {
5 return "Mobile";
6 }
7 if (width >= 768 && width < 992) {
8 return "Tablet";
9 }
10 return "Desktop";
11}
12
13console.log(detectDeviceByViewport());虽然 CSS 媒体查询主要用于响应式设计,但你也可以在 JavaScript 中使用 window.matchMedia() 方法来判断设备类型。这提供了一种基于 CSS 媒体查询语法来检测设备/视口特性的方式。
1function detectDeviceByMediaQuery() {
2 if (window.matchMedia("(max-width: 767px)").matches) {
3 return "Mobile";
4 } else if (window.matchMedia("(min-width: 768px) and (max-width: 991px)").matches) {
5 return "Tablet";
6 } else {
7 return "Desktop";
8 }
9}
10
11console.log(detectDeviceByMediaQuery());- 用户代理字符串被视为不可靠:由于用户代理字符串可以被修改,某些情况下可能不能准确反映用户的设备信息。
- 响应式设计原则:在进行设备检测时,最佳实践是根据内容和功能的需要来适应不同设备,而不是针对特定设备进行优化或限制。
综上,设备检测方法多种多样,选择合适的方法取决于你的具体需求和场景。在可能的情况下,优先考虑使用响应式设计原则,来创建能够在不同设备上良好工作的网页。
837.[webpack] 手写一个 plugin, 统计源码里面的 console.log 调用数量与调用路径【热度: 113】【工程化】【出题公司: 美团】
关键词:手写 webpack plugin
创建一个 webpack 插件需要遵循 webpack 插件的基本结构和原则,同时为了实现统计源码里的 console.log 调用数量与调用路径的目标,我们可能需要对 webpack 的编译过程有一定的了解,尤其是如何操作 webpack 的模块系统内部的原始源代码。
以下是创建这样一个插件的步骤与代码示例:
首先,你需要定义一个 JavaScript 类。在类的 apply 方法中,你将会监听 webpack 的 compilation 钩子来访问并处理模块的源代码。
针对源代码的处理,我们选择监听 compilation 阶段的 optimizeModules 钩子。在这个阶段,模块的原始源代码可以被访问和修改。
处理每个模块的源代码,你可以使用简单的正则表达式或更高级的方法(如 AST 解析)来识别 console.log 的调用。在这个示例中,我将使用正则表达式来简化处理流程。
下面是一个插件的基本实现:
1class ConsoleLogStatsPlugin {
2 apply(compiler) {
3 compiler.hooks.compilation.tap("ConsoleLogStatsPlugin", (compilation) => {
4 compilation.moduleTemplates.javascript.hooks.render.tap("ConsoleLogStatsPlugin", (moduleSource, module) => {
5 // 计算当前模块的 console.log 调用并记录文件路径
6 const source = moduleSource.source();
7 const consoleLogMatches = source.match(/console\.log\(/g) || [];
8
9 if (consoleLogMatches.length > 0) {
10 console.log(`模块 ${module.resource} 包含 ${consoleLogMatches.length} 次 console.log 调用。`);
11 }
12
13 return moduleSource;
14 });
15 });
16 }
17}
18
19module.exports = ConsoleLogStatsPlugin;要在你的 webpack 配置中使用这个插件,首先要导入它,然后将它的一个实例添加到配置的 plugins 数组中:
1const ConsoleLogStatsPlugin = require("./path/to/ConsoleLogStatsPlugin");
2
3module.exports = {
4 // ...其他配置...
5 plugins: [
6 new ConsoleLogStatsPlugin(),
7 // ...其他插件...
8 ],
9};- 性能考虑:直接操作源码可能对构建性能有一定影响。如果项目较大,可能需要考虑更高效的方式,例如仅在生产构建中运行该插件,或者使用更高效的代码分析方法。
- 正则表达式的局限性:简单的正则表达式可能无法准确匹配所有
console.log调用的场景,尤其是当代码中包含多行语句或复杂表达式时。更复杂的场景可能需要使用抽象语法树(AST)解析工具,如 Babel。 - webpack 版本兼容性:webpack 的插件 API 在不同的版本之间可能会有所变化。上述代码示例是基于假定的 API 结构编写的,实际使用时需要根据你的 webpack 版本调整 API 的使用。
此插件可以视为检测源代码中 console.log 使用情况的起点,可以根据具体需求进行扩展和优化。
838.[webpack] 手写 webpack plugin 有那些重要 api 与注意的地方?【热度: 714】【工程化】【出题公司: 美团】
关键词:手写 webpack plugin
在手写一个 webpack 插件时,理解和使用一些核心的 API 是非常关键的。以下是编写 webpack 插件时需要知道的一些重要的 API 和注意事项。
-
compiler 对象:
compiler.hooks: 提供了一系列的钩子,用于插件挂载到 webpack 的整个编译过程。这些钩子包括:compile、compilation:允许你在编译器开始编译以及创建新的编译对象时挂载功能。emit、done:这些阶段更适合于生成资源、修改输出和记录状态。
-
compilation 对象:
- 同样提供了一系列钩子,它们以更细粒度控制编译阶段,比如:
optimize、optimizeModules:用于优化阶段。buildModule:在构建模块时触发。moduleAssets:处理模块产出的资源。
- 同样提供了一系列钩子,它们以更细粒度控制编译阶段,比如:
-
tapable:
- webpack 依赖于 tapable 库来实现钩子系统。使用
tap()或tapAsync()方法来挂载这些钩子。这些方法通常接受两个参数:插件名称和一个回调函数。
- webpack 依赖于 tapable 库来实现钩子系统。使用
-
异步操作:
- 如果你的插件中涉及异步操作,确保正确处理。如果使用异步钩子,可以使用
tapAsync()方法,它提供了一个回调函数来告知 webpack 何时异步操作完成。
- 如果你的插件中涉及异步操作,确保正确处理。如果使用异步钩子,可以使用
-
资源操作:
- 当操作 compilation 中的资源时,务必小心。确保不要删除或覆盖 webpack 或其他插件所需的关键资源。
-
性能考虑:
- 插件的性能影响编译时长。避免在插件中执行过重的操作,尤其是在像
compiler或compilation这样的生命周期钩子中,它们会影响到整个编译过程。
- 插件的性能影响编译时长。避免在插件中执行过重的操作,尤其是在像
-
webpack 版本兼容性:
- webpack 的 API 在不同版本间可能会有变动。编写插件时,需要注意兼容性,并明确指出插件支持的 webpack 版本范围。
-
钩子选择:
- 精确选择最适合的钩子对性能和功能都至关重要。了解每个钩子的含义和最佳用途能帮助插件更高效地工作。
以下是一个简单的 webpack 插件示例,展示了如何使用上述 API:
1class MyWebpackPlugin {
2 apply(compiler) {
3 // 监听 emit 钩子
4 compiler.hooks.emit.tapAsync("MyWebpackPlugin", (compilation, callback) => {
5 // 在这里可以处理 compilation 中的资源、模块等
6 console.log("This is an example webpack plugin!");
7
8 // 完成插件处理后调用 callback 通知 webpack
9 callback();
10 });
11 }
12}这个简单的插件打印一条消息,在 emit 阶段被触发。尽管这个示例很基础,但是它展示了插件的基本结构和一些重要的 API。记得在编写更复杂的插件时阅读并理解 webpack 的文档,以利用 webpack 提供的完整能力。
839.[webpack] 手写 loader: 我要在方法调用的时候, 上报调用源文件地址【热度: 117】【工程化】【出题公司: 阿里巴巴】
关键词:手写 webpack loader
要在方法调用时上报调用源文件的地址,并且希望通过 webpack 编译时来实现,你可以通过编写一个自定义的 webpack loader 来操作源代码,为特定的方法调用插入上报的代码。自定义 loader 本质上是一个函数,该函数接收源码作为输入,对源码进行处理后返回新的源码。
首先明确你想要上报的信息和上报的方式。比如,你可能想要在方法调用时,插入一个上报函数调用,该函数包含当前文件的路径和文件名。
你可以开始编写你的 loader。假设你有一个上报函数 reportFunction(filePath),你希望自动为所有 targetMethod() 调用注入这个上报函数。
loader 文件 report-loader.js 可能看起来像这样:
1module.exports = function (source) {
2 // 使用此 loader 处理的文件的路径
3 const filePath = this.resourcePath;
4
5 // 定义一个正则表达式匹配特定的方法调用,比如 targetMethod()
6 const methodCallRegex = /targetMethod\(\)/g;
7
8 // 替换匹配到的方法调用
9 const modifiedSource = source.replace(methodCallRegex, function (match) {
10 // 插入上报函数调用,传入文件路径
11 return `reportFunction('${filePath}'); ${match}`;
12 });
13
14 return modifiedSource;
15};这个简单的 loader 使用正则表达式查找文件中所有的 targetMethod() 调用,并在每个调用前插入 reportFunction(filePath) 的调用。注意,考虑到文件路径可能需要处理才能安全地用作字符串字面量(例如,转义特殊字符),这里的实现做得很简单,可能需要根据你的具体需求调整。
步骤 3: 在 webpack 配置中使用你的 Loader
在你的 webpack.config.js 文件中,添加一个 module.rules 条目,以确定哪些文件应该通过你的 loader 处理:
1module.exports = {
2 module: {
3 rules: [
4 {
5 test: /\.js$/, // 匹配 JavaScript 文件
6 use: [
7 {
8 loader: "path/to/your/report-loader.js", // 使用自定义 loader 的路径
9 },
10 ],
11 },
12 ],
13 },
14};确保将 loader 属性设置为你自定义 loader 文件的路径。
-
正则表达式: 我在例子中使用的正则表达式非常简单,只匹配特定形式的方法调用。根据你的需要,可能要编写更复杂的正则表达式或使用其他方法(比如抽象语法树解析库,如 Babel)来更准确地识别和修改代码。
-
安全性: 自动修改源代码会带来风险,确保你的匹配和替换逻辑不会导致代码中出现意外的改变。
-
性能: 增加自定义 loader 可能会影响构建的速度,特别是匹配和修改逻辑比较复杂的时候。
编写和测试好你的 loader 后,就可以集成到你的项目中,通过 webpack 构建过程中自动执行所需的代码注入了。
840.[webpack] 手写 webpack loader 有哪些重要 api 与注意事项?【热度: 718】【工程化】【出题公司: 阿里巴巴】
关键词:手写 webpack loader
在开发一个 webpack loader 时,除了理解 loader 的基本概念和功能之外,还有一些重要的 API 和注意事项是必需了解的。这些能够帮助你更高效地编写和调试 loader。
-
this.callback:
- 在 loader 函数内部,
this.callback是一个允许 loader 异步返回结果的函数。你可以通过this.callback(err, content, sourceMap, meta)来传递错误或返回结果。
- 在 loader 函数内部,
-
this.async:
- 调用
this.async会返回一个 callback 函数,你可以在异步操作完成后通过这个函数返回结果。如果 loader 要进行异步处理,这个方法非常有用。
- 调用
-
this.loaders:
this.loaders是一个包含所有需要应用到当前处理文件的 loaders 的数组,当前 loader 的信息也包含在内。
-
this.resourcePath 和 this.resourceQuery:
- 这两个属性提供了当前正在处理的资源文件的路径和查询字符串。
-
this.data:
- 在 loader 的 pitch 阶段和普通阶段之间共享数据的自由对象。
-
Loader Utils (loader-utils):
loader-utils提供了一些实用的工具函数,比如getOptions(this)用于获取 loader 配置项。
-
使用异步 API 处理异步任务:
- 对于需要进行异步操作的 loader,应使用
this.async来获取异步 callback 函数,而不是直接返回内容。
- 对于需要进行异步操作的 loader,应使用
-
保持 loader 的简单:
- 按照最佳实践,每个 loader 只做一件事情。这让 loader 链更加灵活和可维护。
-
避免使用箭头函数:
- 在编写 loader 时,避免使用箭头函数来声明 loader 函数,因为箭头函数会绑定父作用域的
this,而你需要访问 webpack 传递给 loader 函数的this上下文。
- 在编写 loader 时,避免使用箭头函数来声明 loader 函数,因为箭头函数会绑定父作用域的
-
处理异常:
- 在处理资源的过程中,如果遇到错误,应该使用
this.emitError方法或通过this.callback函数的第一个参数传递错误。
- 在处理资源的过程中,如果遇到错误,应该使用
-
缓存:
- 除非有特定的理由,否则避免关闭 loader 的缓存。webpack 默认会缓存 loader 的结果,以提升构建性能。
-
资源映射(Source Maps):
- 如果你的 loader 转换源内容,生成新的源内容,应当生成新的 source map。然后,使用
this.callback来返回更新后的代码和对应的 source map。
- 如果你的 loader 转换源内容,生成新的源内容,应当生成新的 source map。然后,使用
-
通信:
- 如果有多个 loader 对同一个资源进行处理,它们之间可以通过
this.data来共享数据。
- 如果有多个 loader 对同一个资源进行处理,它们之间可以通过
掌握并妥当使用上述 API 和注意事项,将帮助你开发出高效、健壮且易于维护的 webpack loader。
841.[webpack] 多个 loader 对同一个资源进行处理, 他们之间如何通信?【热度: 134】【工程化】【出题公司: 阿里巴巴】
关键词:webpack loader 通信
在 webpack 中,loader 之间传递数据的常见方式是通过资源文件(即要处理的源文件本身)的内容。每个 loader 接收上一个 loader 的处理结果作为输入,并提供自己的输出给下一个 loader。这种方式适用于大多数使用场景。然而,在某些情况下,loader 需要在它们之间共享额外的状态或数据,而不仅仅是文件内容。对于这种需求,webpack 提供了一种机制,允许 loader 之间共享数据。
在 webpack 4 及以后的版本中,一个 loader 可以利用它的 this.data 属性来共享会话数据。这个属性是特定于当前 loader 运行实例的,可以在 loader 的 pitch 阶段和正常的加载阶段之间共享数据。
1// pitch 阶段
2module.exports.pitch = function (remainingRequest, precedingRequest, data) {
3 data.sharedValue = "Hello from pitch phase";
4};在上面的代码片段中,pitch 方法设置了 data.sharedValue。这个 pitch 方法是可选的,它在 loader 处理资源之前执行。data 对象会从 pitch 阶段传递到正常的加载阶段,从而可以在后者中访问之前设置的共享值。
1// 正常的加载阶段
2module.exports = function (content) {
3 const callback = this.async();
4 const sharedValue = this.data.sharedValue;
5
6 // 这里可以根据 sharedValue 来处理 content
7 console.log(sharedValue); // 将输出 "Hello from pitch phase"
8
9 callback(null, content);
10};一些特定的 loader 实现可能通过向源文件内容附加额外的信息来实现间接的通信。例如,一个 loader 可以在文件内容的末尾追加一些注释或者特殊标记,然后下一个 loader 可以读取这些注释或标记来获取必要的信息。然而,这种方法是高度依赖上下文且难以维护的,不推荐在实际项目中使用。
当使用一种方法在 loader 之间共享数据时,请注意数据的共享是在每个模块的构建过程中进行的,这些数据是特定于当前处理中的资源文件的。通过这种方式共享的数据不应该包含敏感信息,也不应该用于在不同模块或不同构建之间共享全局状态。
理解这些机制以及如何在 loader 之间正确共享数据是创建高效可维护 webpack 构建流程的关键。
845.介绍一下 TypeScript 类型兼容——逆变、协变、双向协变和不变 这四个概念【热度: 30】【TypeScript】
关键词:TS 类型兼容
TypeScript 中的类型系统允许类型之间存在不同的兼容性关系,这在处理复杂的类型结构时非常重要,尤其是涉及到函数类型和类结构的相互作用。以下是对逆变、协变、双向协变和不变这四个概念的解释:
- 定义:如果
A类型是B类型的子类型,则由A构成的类型T<A>也是由B构成的类型T<B>的子类型。 - 应用场景:在 TypeScript 中,数组类型是协变的。这意味着如果我们有类型
string extends object,那么string[] extends object[]也成立。 - 函数返回值:在函数类型中,返回值类型是协变的,意味着函数的返回类型可以是其声明的返回类型的子类型。
代码示例:
数组的协变是最常见的例子:
1class Animal {}
2class Dog extends Animal {}
3
4// 协变:Dog是Animal的子类,因此Dog[]也可以赋值给Animal[]
5let dogs: Dog[] = [new Dog(), new Dog()];
6let animals: Animal[] = dogs; // 协变函数返回值的协变:
1function getAnimal(): Animal {
2 return new Animal();
3}
4function getDog(): Dog {
5 return new Dog();
6}
7
8// 协变:getDog的返回类型是getAnimal返回类型的子类型
9let animalFunction: () => Animal = getDog; // 协变- 定义:在特定情况下,如果
A类型是B类型的子类型,则由B构成的类型T<B>也是由A构成的类型T<A>的子类型。 - 应用场景:主要体现在函数参数中。如果函数
f的参数类型是B,那么一个参数类型为A的函数可以分配给f,前提是A是B的超类型。这意味着函数可以接受更泛化的参数类型。 - 函数参数:在 TypeScript 的严格模式下,函数参数是双向协变的(见下),但在某些上下文中可以被视为逆变。
代码示例
在 TypeScript 中,函数参数在默认情况下是双向协变的,但我们可以使用逆变的方式理解它们在特殊情况下的行为,比如在启用 --strictFunctionTypes 标志后,函数参数表现出逆变:
1class Parent {}
2class Child extends Parent {}
3
4// 逆变:参数具有逆变的特性
5let fn1: (param: Parent) => void = (child: Child) => {};- 定义:如果类型
A可以赋值给类型B,或者类型B可以赋值给类型A,则类型A与B是双向协变的。 - 应用场景:TypeScript 中函数参数的默认行为。意味着如果有两个函数,其参数类型分别是彼此的父类型或子类型,这两个函数类型被认为是兼容的。
- 注意事项:这种设计是出于实用和方便考虑,但可能会导致类型系统的一些不直观行为,特别是在函数参数类型检查上。
代码示例
默认情况下,TypeScript 中的函数参数是双向协变的:
1function fnA(param: Animal) {}
2function fnD(param: Dog) {}
3
4// 双向协变:尽管参数类型不完全相同,但两个函数类型在TS中是兼容的
5let fn: (param: Dog) => void = fnA; // 双向协变允许这种赋值
6fn = fnD;- 定义:类型
T<A>仅与类型T<B>兼容,如果且仅如果A与B完全相同。 - 应用场景:当我们处理类的实例类型时,经常会出现不变性。例如,如果有一个以
T为泛型参数的类Container<T>,则Container<string>与Container<object>将不兼容,除非它们具有完全相同的类型。 - 类和接口成员:在 TypeScript 中,类和接口的成员默认是不变的。这意味着在赋值兼容性方面,类和接口的成员类型必须完全相同。
代码示例
对于类的实例类型的兼容性,体现为不变性:
1interface IContainer<T> {
2 value: T;
3}
4
5let stringContainer: IContainer<string> = { value: "Hello, World!" };
6let objectContainer: IContainer<object> = { value: { message: "Hello, World!" } };
7
8// 不变:即使string是object的子类型,以下赋值仍然是不允许的。
9// stringContainer = objectContainer; // 错误!
10// objectContainer = stringContainer; // 错误!这些类型兼容性的概念是理解和使用 TypeScript 高级类型系统的基础,尤其是在设计通用库或进行复杂类型转换时。
846.混动跟随导航(电梯导航)该如何实现【热度: 498】【web 应用场景】
关键词:电梯导航、混动导航
作者备注, 这个问题实际上是介于中等难度和 高难度之间的问题, 主要看怎么回答 文本回答涉及到了 IntersectionObserver + scrollIntoView 实现, 可以归为 「高」里面
具体 api 本文不再介绍, 可以直接翻看 MDN 即可
思路很简单, 利用 scrollIntoView 进行导航滚动、利用 IntersectionObserver 进行可视区判断;
具体实现:
- 第一步:点击右边的导航菜单,利用 scrollIntoView 方法使内容区域对应的元素出现在可视区域中。
1let rightBox = document.querySelector(".rightBox");
2rightBox.addEventListener(
3 "click",
4 function (e) {
5 let target = e.target || e.srcElement;
6 if (target && !target.classList.contains("rightBox")) {
7 document.querySelector("." + target.className.replace("Li", "")).scrollIntoView({
8 behavior: "smooth",
9 block: "center",
10 });
11 }
12 },
13 false
14);- 第二步:页面容器滚动时,当目标元素出现在检测区域内则联动改变对应导航的样式。
1let observer = new IntersectionObserver(
2 function (entries) {
3 entries.forEach((entry) => {
4 let target = document.querySelector("." + entry.target.className + "Li");
5
6 if (entry.isIntersecting && entry.intersectionRatio > 0.65) {
7 document.querySelectorAll("li").forEach((el) => {
8 if (el.classList.contains("active")) {
9 el.classList.remove("active");
10 }
11 });
12
13 if (!target.classList.contains("active")) {
14 target.classList.add("active");
15 }
16 }
17 });
18 },
19 {
20 threshold: [0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8],
21 }
22);完整效果请看下面链接: https://codepen.io/xingba-coder/pen/ZEdKRKJ
参考文档:https://juejin.cn/post/7399982698846404649
847.退出浏览器之间, 发送积压的埋点数据请求, 该如何做【热度: 134】【web 应用场景】
关键词:退出浏览器发送积压请求数据
退出浏览器时发送积压的埋点数据请求是 web 开发中的一个常见需求,尤其是在需要确保用户活动数据尽可能准确地被记录的场景下。实现这一需求的关键在于捕获用户关闭浏览器或离开页面的时刻,并在这一时刻尽可能快速地发送所有积压的数据。由于浏览器对于即将关闭时发出的请求处理方式不同,这一过程可能会有些复杂。
使用 navigator.sendBeacon()
navigator.sendBeacon() 方法允许你在浏览器会话结束时异步地向服务器发送小量数据。这个方法的设计初衷就是为了解决上述问题。sendBeacon() 在大多数现代浏览器中得到支持,并且其异步特性意味着它不会阻塞页面卸载或影响用户体验。
1window.addEventListener("beforeunload", function (event) {
2 var data = {
3 /* 收集的埋点数据 */
4 };
5 var beaconUrl = "https://yourserver.com/path"; // 你的服务器接收端点
6
7 navigator.sendBeacon(beaconUrl, JSON.stringify(data));
8});使用 fetch() API 与 keepalive 选项
如果因某种原因 navigator.sendBeacon() 不能满足需求,fetch() API 的 keepalive 选项是另一个选择。这个选项允许你发送一个保持存活状态的请求,即使用户已经离开页面。但是,需要注意的是,使用 keepalive 选项发送的请求有大小限制(大约为 64KB)。
1window.addEventListener("beforeunload", function (event) {
2 var data = {
3 /* 收集的埋点数据 */
4 };
5 var beaconUrl = "https://yourserver.com/path"; // 你的服务器接收端点
6
7 fetch(beaconUrl, {
8 method: "POST",
9 body: JSON.stringify(data),
10 headers: {
11 "Content-Type": "application/json",
12 },
13 keepalive: true, // 保持请求存活
14 });
15});- 浏览器兼容性:尽管
navigator.sendBeacon()和fetch()的keepalive选项被许多现代浏览器支持,但在实施解决方案时仍然需要考虑目标用户可能使用的浏览器类型和版本。 - 数据量限制:
sendBeacon()和keepalive选项的请求都有数据量限制。确保不要发送超过限制大小的数据。 - 可靠性:虽然这些方法能够提高数据发送的成功率,在浏览器关闭时发送数据的操作本身依然不能保证 100% 的成功率,特别是在网络状况不佳的情况下。
通过上述方法,你可以在浏览器即将关闭时尝试发送积压的埋点数据,从而尽可能减少数据丢失的情况。
851.如何统计页面的 long task(长任务)【热度: 140】【web 应用场景】【出题公司: 腾讯】
关键词:统计 long task
统计网页中的 LongTask 是性能监控的一部分,特别是在测量和优化页面的响应能力方面非常有用。LongTask API 提供了一种监测浏览器主线程被长时间任务阻塞的能力,这些任务通常会影响用户体验,如使滚动卡顿或延迟输入响应。下面是一些基本步骤,帮助你开始监控 LongTask:
-
使用 Performance Observer API: 这个 API 允许你注册一个观察者来获取性能相关的数据,包括
LongTask。 -
注册 LongTask 观察者:
- 创建一个
PerformanceObserver实例,并为其提供一个回调函数。这个回调函数会在观察到LongTask时被调用。 - 在回调函数中,你可以获取到每个
LongTask的详细信息,如开始时间、持续时间等。 - 调用
observe()方法开始观察性能条目,指定{entryTypes: ['longtask']}来仅观察LongTask。
- 创建一个
-
处理 LongTask 数据:
- 在上述回调中,你可以收集
LongTask的数据并进行处理,例如计算平均持续时间,或将数据发送到服务器进行进一步分析。
- 在上述回调中,你可以收集
下面是一个简单的示例代码,演示如何注册 LongTask 观察者并打印任务的一些基本信息:
1const observer = new PerformanceObserver((list) => {
2 list.getEntries().forEach((entry) => {
3 console.log(`LongTask Detected:`, entry);
4 console.log(`Start Time: ${entry.startTime}, Duration: ${entry.duration}`);
5 // TODO: 这里可以根据需要进一步处理这些数据,比如发送给服务器
6 });
7});
8
9// 开始观察长任务
10observer.observe({ entryTypes: ["longtask"] });-
优化相关代码:
- 一旦你开始收集到
LongTask数据,可以识别出影响性能的代码区域,并进行相应的优化。
- 一旦你开始收集到
-
监控页面性能:
- 持续监控并优化,根据收集到的数据调整策略。
记住,只有支持 Performance Timeline Level 2 规范的浏览器才能使用 LongTask API。在实际部署之前,确保你有对应的浏览器兼容性检查和错误处理代码。
852.PerformanceObserver 如何测量页面性能【热度: 190】【web 应用场景】【出题公司: 百度】
关键词:PerformanceObserver api 使用
PerformanceObserver API 是一个强大的浏览器接口,允许开发者订阅性能相关的事件,实时收集和分析用户当前浏览器会话中的性能数据。这个 API 是 Web 性能监测工具箱的一部分,与 window.performance 对象紧密协作,后者提供了对网页性能数据的访问。PerformanceObserver 允许应用异步监听性能测量事件,而不需要定时检查 window.performance 的条目。
-
实时性能数据收集:随着网页生命周期中各种事件的触发,
PerformanceObserver支持实时捕获和处理性能数据条目。 -
减少资源消耗:与轮询
window.performance对象相比,使用PerformanceObserver可以降低资源消耗,并提供更及时的数据收集。 -
灵活的数据订阅模型:可以指定订阅一个或多个特定类型的性能条目,根据需要接收相关数据。
-
observe():开始观察一个或多个特定类型的性能条目。通过指定条目类型,应用可以订阅感兴趣的性能事件。 -
disconnect():停止观察性能数据。这可以释放相关资源,并停止进一步的回调执行。
下面的例子展示了如何使用 PerformanceObserver 来监听首次内容绘制 (First Contentful Paint, FCP) 和最大内容绘制 (Largest Contentful Paint, LCP) 的性能指标。
1const perfObserver = new PerformanceObserver((entryList) => {
2 for (const entry of entryList.getEntries()) {
3 if (entry.name === "first-contentful-paint") {
4 console.log("FCP:", entry.startTime);
5 } else if (entry.name === "largest-contentful-paint") {
6 console.log("LCP:", entry.startTime);
7 }
8 }
9});
10
11perfObserver.observe({ type: "paint", buffered: true });在这个例子中,perfObserver 被配置为监听包含 FCP 和 LCP 的 paint 类型的性能条目。当这些指标被记录到性能时间线上时,回调函数将被执行,并可以对这些数据进行进一步的处理,比如打印在控制台或发送到服务器。
PerformanceObserverAPI 的支持程度取决于浏览器和浏览器版本。为了最好地利用这一 API,推荐检查目标用户群体最常用浏览器的兼容性。- 合理使用
disconnect()方法来停止数据的观察(特别是在单页应用中或在不再需要收集数据时)有助于保持应用的性能。 buffered选项允许接收到观察者激活之前已经记录的性能条目,这在页面加载阶段尤其有用。
通过 PerformanceObserver,开发者可以精细控制性能数据的收集过程,有效监控和分析网页性能,从而提升用户体验。
853.移动端如何实现下拉滚动加载(顶部加载)【热度: 740】【web 应用场景】
关键词:移动端下拉加载
有现成的文档可以直接参考, 讲得非常的全面 文章链接: https://juejin.cn/post/7340836136208859174 一下是作者对于改文章的总结
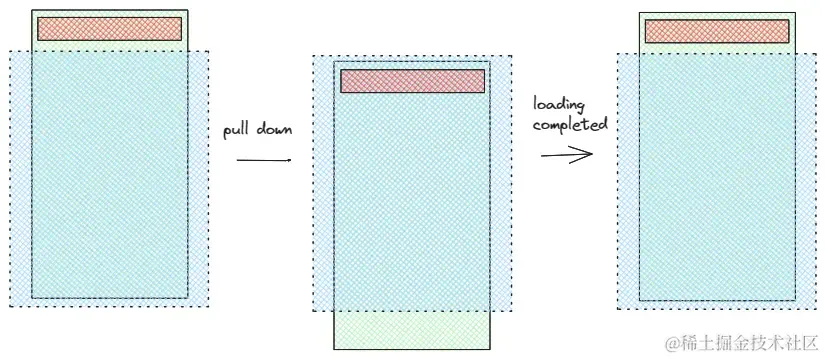
如图所示,蓝色框代表视口,绿色框代表容器,橙色框代表加载动画。最开始时,加载动画处于视口外;开始下拉之后,容器向下移动,加载动画从上方进入视口;结束下拉后,容器又开始向上移动,加载动画也从上方退出视口。
看完布局代码,我们再看逻辑代码。逻辑代码中,我们要监听用户的手指滑动、实现下拉手势。我们需要用到三个事件:
- touchstart 代表触摸开始;
- touchmove 代表触摸移动;
- touchend 代表触摸结束。
从 touchstart 和 touchmove 事件中我们可以获取手指的坐标,比如 event.touches[0].clientX 是手指相对视口左边缘的 X 坐标,event.touches[0].clientY 是手指相对视口上边缘的 Y 坐标;从 touchend 事件中我们则无法获得 clientX 和 clientY。
我们可以先记录用户手指 touchstart 的 clientY 作为开始坐标,记录用户最后一次触发 touchmove 的 clientY 作为结束坐标,二者相减就得到手指移动的距离 distanceY。
设置手指移动多少距离,容器就移动多少距离,就得到了我们的逻辑代码:
1 代码解读const box = document.getElementById('box')
2const loader = document.getElementById('loader')
3let startY = 0, endY = 0, distanceY = 0
4
5function start(e) {
6 startY = e.touches[0].clientY
7}
8
9function move(e) {
10 endY = e.touches[0].clientY
11 distanceY = endY - startY
12 box.style = `
13 transform: translateY(${distanceY}px);
14 transition: all 0.3s linear;
15 `
16}
17
18function end() {
19 setTimeout(() => {
20 box.style = `
21 transform: translateY(0);
22 transition: all 0.3s linear;
23 `
24 loader.className = 'loading'
25 }, 1000)
26}
27
28box.addEventListener('touchstart', start)
29box.addEventListener('touchmove', move)
30box.addEventListener('touchend', end)逻辑代码实现一个简陋的下拉效果,当然现在还有很多缺陷。

- 没有最小、最大距离限制
- 加载动画没有停留在视口顶部
- 重复触发
- 没有限制方向
- 没有阻止原生滚动
- 没有阻止 iOS 橡皮筋效果
请看原文
854.如何组织工程项目【热度: 517】【web 应用场景】【出题公司: 阿里巴巴】
关键词:组织工程项目
该话题是开放性话题,难度系数可高可低,请自己探索答案吧。