2024.08.31 - 2024.09.17 更新前端面试问题总结(21 道题)
获取更多面试相关问题可以访问
github 地址: https://github.com/pro-collection/interview-question/issues
gitee 地址: https://gitee.com/yanleweb/interview-question/issues
目录:
-
中级开发者相关问题【共计 12 道题】
-
- [] == ! [] 为什么返回 true【热度: 100】【JavaScript】
-
- 长文本场景,中间显示省略号…, 两端正常展示【热度: 351】【JavaScript】【出题公司: 美团】
-
- JS 如何计算一段文本渲染之后的长度【热度: 648】【JavaScript】【出题公司: 百度】
-
- flex 布局中子元素不压缩, 该如何设置属性【热度: 200】【CSS】【出题公司: 小米】
-
- 在开发过程中,想做 git 代码暂存,该如何做【热度: 342】【web 应用场景】【出题公司: 百度】
-
- 介绍一下 position sticky【热度: 826】【CSS】【出题公司: 美团】
-
- pnpm install 和 npm install 有何区别【工程化】【出题公司: 阿里巴巴】
-
- npm run start 的过程是啥,为何能执行对应的命令【热度: 170】【web 应用场景】【出题公司: 腾讯】
-
- http 的请求和响应都有哪些传输数据格式【热度: 149】【网络】【出题公司: 美团】
-
- http 常见的几个重定向 code 是多少,区别是啥【热度: 172】【网络】【出题公司: 美团】
-
- http 的请求和响应报文 有啥区别【网络】【出题公司: TOP100 互联网】
-
- http 的 请求和 响 应报文分 别是什么样的【网络】【出题公司: TOP100 互联网】
-
-
高级开发者相关问题【共计 7 道题】
-
- eslint 如何设置只校验本次 MR 变更的文件内容【热度: 200】【web 应用场景】【出题公司: 小米】
-
- 需要详细记录多个操作链路的性能耗时,进行结构化场景分析,该如何做【热度: 378】【web 应用场景】【出题公司: 美团】
-
- websocket 断联之后如何重连,且保证断链期间数据不丢失【热度: 200】【web 应用场景】【出题公司: 腾讯】
-
- 如何做静态资源预加载【热度: 696】【web 应用场景】【出题公司: 腾讯】
-
- [webpack] 代码分割中,让所有的外部依赖打成一个包,源码 source 打成一个包,该如何配置【热度: 352】【工程化】【出题公司: 阿里巴巴】
-
- [webpack] 如何优化产物大小【热度: 521】【工程化】【出题公司: 阿里巴巴】
-
- 发送请求的时候, method = OPTIONS 是什么请求【热度: 717】【网络】【出题公司: 小米】
-
-
资深开发者相关问题【共计 2 道题】
-
- 请求数量过多,该如何治理【热度: 418】【网络】【出题公司: 阿里巴巴】
-
- monorepo 工程有哪些工具架构, 该如何选型【热度: 450】【工程化】【出题公司: 阿里巴巴】
-
877. [] == ! [] 为什么返回 true【热度: 100】【JavaScript】
关键词:js 隐式转换
这个问题涉及到 JavaScript 中的类型转换和比较操作的规则。
在 JavaScript 中,[] == ![]的比较过程如下:
-
![]的计算
!是逻辑非操作符,它会首先将右侧的操作数转换为布尔值,然后反转该布尔值。对于空数组[],在 JavaScript 中,所有对象(包括数组)在布尔上下文中都被认为是true。因此,![]首先将[]转换为true,然后取反,变成false。 -
比较
[]与false根据 ECMAScript 规范,在进行抽象等值比较(
==)时,如果比较的两个操作数类型不同,JavaScript 会尝试将它们转换成一个共同的可比较类型。在本例中,一边是对象(空数组[]),另一边是布尔值false。规则是,如果有布尔值参与比较,先将布尔值转换为数值再进行比较。布尔值
false转换为数值0。 -
比较
[]与0现在比较的是对象(空数组
[])与数字(0)。根据规范,当比较对象与数字时,对象会先尝试转换为原始值(通过调用它的valueOf和(或)toString方法),用于比较。对于空数组
[],[].toString()结果是""(空字符串)。 -
比较
""与0最后的比较是在空字符串(
"")与数字0之间进行。在这个阶段,字符串会被转换为数字,空字符串转换为数字时结果是0。因此,最终比较的是
0 == 0,这显然是true。
因此,[] == ![]返回true的原因是,在 JavaScript 中将操作数从对象到布尔值,再到字符串,最后到数字的一系列隐式类型转换导致的。这也展示了 JavaScript 中类型强制转换规则的复杂性和==运算符可能带来的意外行为。这就是为什么很多 JavaScript 编程风格指南推荐使用===(严格等于运算符),因为它不会进行类型转换,可以避免这种类型的意外结果。
878. 长文本场景,中间显示省略号…, 两端正常展示【热度: 351】【JavaScript】【出题公司: 美团】
关键词:长文本隐藏
在前端处理长文本且需要在中间显示省略号(…),两端保留完整文本的情况,通常有下面几种方法可以达到效果:
对于单行的文本,可以使用 CSS 的text-overflow属性来实现,但这种方法一般只能实现末尾的省略号,无法直接实现中间省略的效果。
当需要在文本中间显示省略号时,就需要结合使用 JavaScript 和 CSS 来处理。以下是一种可能的实现方法:
- 确定保留文本的长度。 首先确定需要在文本的开始和结束保留多少字符。
- 使用 JavaScript 计算并处理文本。 根据上面确定的长度,使用 JavaScript 截取字符串,并添加省略号。
- 使用 CSS 来保证文本的美观展示。
下面是一个简单的示例代码:
1<!DOCTYPE html>
2<html lang="en">
3 <head>
4 <meta charset="UTF-8" />
5 <meta name="viewport" content="width=device-width, initial-scale=1.0" />
6 <title>Document</title>
7 <style>
8 .text-container {
9 width: 60%;
10 white-space: nowrap;
11 overflow: hidden;
12 text-overflow: ellipsis;
13 margin: 20px auto;
14 }
15 </style>
16 </head>
17 <body>
18 <div id="text" class="text-container">
19 <!-- 动态生成的文本会放在这里 -->
20 </div>
21
22 <script>
23 function truncateText(selector, text, frontLen, backLen) {
24 const totalLen = frontLen + backLen;
25 if (text.length > totalLen) {
26 const startText = text.substr(0, frontLen);
27 const endText = text.substr(-backLen);
28 document.querySelector(selector).textContent = `${startText}...${endText}`;
29 } else {
30 document.querySelector(selector).textContent = text;
31 }
32 }
33
34 const exampleText = "这是一个长文本示例,需要在中间显示省略号,同时保留两端的文本内容。";
35 truncateText("#text", exampleText, 10, 10);
36 </script>
37 </body>
38</html>在这个例子中,truncateText函数接收一个选择器(在这里是指容器的 ID)、要处理的文本、前端和后端应保留文本的长度。函数计算并生成了新的文本内容,其中间部分被省略号(…)替代。
这个方法给予了你灵活性去确定前后端保留的文本长度,以及省略的部分。但需要注意,这是针对简单场景的解决方案,对于更复杂的布局或特殊字体,可能需要更细致的处理来保证良好的显示效果。
879. JS 如何计算一段文本渲染之后的长度【热度: 648】【JavaScript】【出题公司: 百度】
关键词:计算文本长度
追加描述
需要根据这个长度来动态计算文本是否折叠, 所以这个文本没有计算出长度是否折叠之前,还不能在用户可视区域渲染出来
要在 JavaScript 中计算一段文本渲染之后的长度,可以通过几种方法来实现。这里的“长度”可以是文本渲染后的像素宽度,它取决于具体的字体、字号、文本内容等因素。以下是一些可行的方法:
这个方法涉及到创建一个与目标文本拥有相同样式(字体、字号等)的临时 DOM 元素,将目标文本内容设置到临时元素中,然后插入到文档流(不可见状态下)来测量其尺寸。测量完成后,再从文档中移除该临时元素。
1function getTextWidth(text, font) {
2 // 创建一个临时的span元素
3 let tempEl = document.createElement("span");
4 tempEl.style.visibility = "hidden"; // 确保元素不可见
5 tempEl.style.whiteSpace = "nowrap"; // 防止文本换行
6 tempEl.style.font = font; // 应用字体样式
7 tempEl.textContent = text;
8
9 document.body.appendChild(tempEl);
10 let width = tempEl.offsetWidth; // 获取元素的宽度
11 document.body.removeChild(tempEl);
12
13 return width;
14}
15
16// 示例用法
17const font = "16px Arial";
18const text = "这是一段测试文本";
19console.log(getTextWidth(text, font));2. 使用 Canvas 的 measureText 方法
如果你不想与 DOM 打交道,也可以使用 Canvas 的 API 来测量文本宽度。CanvasRenderingContext2D.measureText() 方法返回一个对象,该对象包含了给定文本渲染后的宽度(以像素为单位)。
1function measureTextWidth(text, font) {
2 let canvas = document.createElement("canvas");
3 let ctx = canvas.getContext("2d");
4 ctx.font = font; // 应用字体样式,格式与 CSS font 属性相同
5 let metrics = ctx.measureText(text);
6 return metrics.width;
7}
8
9// 示例用法
10const font = "16px Arial";
11const text = "这是一段测试文本";
12console.log(measureTextWidth(text, font));- 尽量在文档加载完毕后使用这些方法,特别是如果你依赖于页面上的样式信息时。
- 如果文本在页面上多次出现且样式一致,可以考虑缓存测量结果来提升性能。
881. flex 布局中子元素不压缩, 该如何设置属性【热度: 200】【CSS】【出题公司: 小米】
关键词:flex 子元素不压缩
在 Flex 布局中,如果你想要子元素在容器内不被压缩,即保持其原始尺寸或指定尺寸,不受容器大小变化的影响,可以通过设置子元素的flex-shrink属性来实现。flex-shrink属性决定了当父容器大小小于其所有 flex 项总大小时,各 flex 项的缩小比例。默认值是 1,表示 flex 项会等比例缩小,以适应父容器的大小。
要阻止子元素压缩,你应该将它的flex-shrink属性设置为 0。这样,无论容器大小如何变化,子元素都不会缩小。
示例如下:
HTML:
1<div class="flex-container">
2 <div class="flex-item">不压缩的项目</div>
3 <!-- 其他的flex-item -->
4</div>CSS:
1.flex-container {
2 display: flex;
3 /* 添加其他需要的flex布局属性 */
4}
5
6.flex-item {
7 flex-shrink: 0; /* 这使得该flex项目不会被压缩 */
8 /* 设置宽度或其他样式 */
9}在这个例子中,任何带有flex-item类的元素都不会在容器空间不足时被压缩。
此外,flex属性是flex-grow、flex-shrink和flex-basis这三个属性的简写。如果你想在保证元素不被压缩的同时,具体控制元素的放大行为或基础大小,也可以直接使用flex属性进行设置。例如,如果你还希望元素不放大,并且有一个固定的基础大小,可以这样设置:
1.flex-item {
2 flex: 0 0 auto; /* 不放大,不缩小,基础大小为auto */
3}这种方式提供了更细致的控制,0 0 auto分别对应flex-grow、flex-shrink和flex-basis的值。这告诉浏览器该项目即不应放大,也不应缩小,并且以其默认大小作为基础大小。
883. 在开发过程中,想做 git 代码暂存,该如何做【热度: 342】【web 应用场景】【出题公司: 百度】
关键词:git stash 使用
作者备注
这个问题的指向性非常明显, 就是在问 git stash 的使用
在 Git 中,如果你想要暂存当前的工作进度,可以使用git stash命令。这个命令会将你的工作目录中的修改(已追踪文件的修改和暂存的改动)保存到一个未完成工作的栈中,同时将你的工作目录恢复到上次提交的状态,从而让你可以转而处理其他工作,之后再回来继续刚才的工作。
- 暂存当前的工作
或者,为这次暂存操作添加一个描述,以便之后更容易识别:
- 查看暂存列表
这个命令会显示所有被暂存的进度列表。
- 应用最近的暂存
默认情况下,git stash apply将重新应用最近暂存的进度。如果你有多个暂存进度,可以通过指定 stash 的名称(例如:stash@{0})来选择具体的一个进度使用。
1git stash apply stash@{0}- 弹出最近的暂存
这个命令将应用最近的暂存进度,并将这个暂存记录从暂存的栈中移除。
-
删除一个指定的暂存
-
清除所有暂存
-
暂存未追踪的文件
如果你还想暂存那些新添加到工作目录中但还没有加入版本控制的文件(即未追踪文件),可以使用-u或--include-untracked选项:
或
1git stash --include-untracked- 暂存忽略文件
默认git stash不会暂存.gitignore中忽略的文件。如果你希望连同这些文件一起暂存,可以使用-a或--all选项:
git stash 是一个非常有用的功能,特别是当你需要快速切换到另一个分支处理一些工作,而你的当前分支有未完成的工作时。它允许你临时保管你的工作进度,防止未完工的更改妨碍其他任务的进行。
884. 介绍一下 position sticky【热度: 826】【CSS】【出题公司: 美团】
关键词:position sticky
position: sticky; 是 CSS 中的一个定位属性值,它允许元素在页面滚动到某个阈值时“固定”在位置上,而在达到这个阈值之前,元素会像正常文档流中的元素一样表现(也就是说,在特定条件下它表现得像 position: relative;,在另一些条件下表现得像 position: fixed;)。这种特性使 sticky 定位成为实现网页上吸顶或吸底效果的一种非常实用的手段。
- 吸顶效果:最常见的用途之一是导航栏吸顶。当用户向下滚动页面时,导航栏到达视口顶部后就会固定在那里,直到用户向上滚动至原始位置。
- 滚动容器:
sticky元素将相对于离其最近的拥有滚动机制(例如,overflow: auto;或overflow: scroll;)的祖先元素进行定位。
要使元素具有 sticky 定位,你需要为它指定 position: sticky; 以及至少一个“边缘”属性(top, right, bottom, left)的值。这个值决定了元素在满足“粘性”条件前与边缘的距离。
1.sticky-element {
2 position: -webkit-sticky; /* Safari */
3 position: sticky;
4 top: 0; /* 距离顶部 0px 时生效 */
5 z-index: 1000; /* 确保在其他内容之上 */
6 background-color: white; /* 可选:为了视觉效果更明显 */
7}
8
9.container {
10 overflow-y: auto; /* 确保是滚动容器 */
11 height: 500px; /* 举例,根据实际需求设置 */
12} 1<div class="container">
2 <div class="sticky-element">我在滚动时会吸顶</div>
3 <!-- 其他内容 -->
4</div>- 兼容性:
position: sticky;在大多数现代浏览器上都得到了支持,但在一些旧版浏览器中可能需要使用前缀或不被支持。 - 父元素的
overflow: 如果一个元素的任何父元素具有overflow: hidden、overflow: scroll或overflow: auto样式,则position: sticky可能不会生效。 - 祖先的
display: 某些display值(如display: table-cell等)也可能影响position: sticky的行为。 - 使用时机:虽然
sticky提供了一种便捷的方式来实现吸附效果,但在一些复杂的布局中,可能需要额外的样式调整或脚本支持来达到预期的效果。
通过灵活运用 position: sticky;,可以在无需 JavaScript 的情况下,实现许多响应用户滚动的交互效果。
889. pnpm install 和 npm install 有何区别【工程化】【出题公司: 阿里巴巴】
pnpm install 和 npm install 都是用于安装 JavaScript 项目依赖的命令,但它们背后的包管理器(分别是 pnpm 和 npm)在处理依赖安装、存储和优化方面有一些关键区别。
-
npm:在每个项目的
node_modules文件夹中分别存储其依赖。这意味着如果你有多个项目,它们共享相同的依赖库,这些依赖库的多个副本将在你的文件系统中的每个项目内分别存储。这样做会占用更多的磁盘空间。 -
pnpm:采用一种称为内容寻址文件系统的方式来存储依赖。所有项目的依赖被存储在一个共享的位置,各个项目中的
node_modules目录通过硬链接(hard links)或符号链接(symlinks)指向这个共享位置。该方法有效地减少了磁盘空间的占用,并加快了依赖的安装速度。 -
pnpm:由于对依赖进行了有效的复用,并且使用硬链接来减少磁盘上的副本数量,通常可以提供比
npm更快的安装速度。 -
npm:近几个大版本中也进行了许多性能改进,但在多个项目中共享相同依赖时,它可能仍然比
pnpm更慢,尤其是在首次安装依赖时。 -
npm:自版本 3 以后,默认创建扁平的
node_modules结构(尽可能),这样做是为了避免 Windows 系统中路径过长的问题。但在必要时,npm仍然会创建嵌套的node_modules目录结构,以解决依赖冲突。 -
pnpm:通过使用符号链接,
pnpm维护了一个严格的嵌套依赖结构,更接近每个包的package.json文件所声明的依赖树形态。这提供了更高的一致性和在某些情况下更好的包隔离性。 -
pnpm:更好地隔离了依赖,每个包只能访问其在
package.json中声明的依赖。这一特性增强了项目的安全性,因为它阻止了未声明的依赖被意外引入的情况。 -
npm:虽然
npm也遵循package.json中的声明,但其扁平化的node_modules结构有时可能会容易地让包访问到未明确声明的依赖。 -
这两个工具的命令行界面(CLI)和配置都非常直观且类似,但它们的某些命令和选项可能会有细微差别。
pnpm为了优化性能和安全性引入了一些特有的命令和配置选项。
总的来说,pnpm 在多项目管理、磁盘空间和安装速度方面提供了优于 npm 的性能和利益。对于新项目或在寻求性能优化的既存项目,考虑试用 pnpm 可能是个不错的选择。
890. npm run start 的过程是啥,为何能执行对应的命令【热度: 170】【web 应用场景】【出题公司: 腾讯】
关键词:npm run start 过程
当你在项目的根目录下执行 npm run start 命令时,实际上触发了一个由 Node.js 包管理器(npm)管理的一系列流程。理解这一过程,可以帮助你更好地掌握项目的构建和开发流程。以下是 npm run start 执行过程的概述:
-
查找
package.json文件:npm 首先在当前目录下查找package.json文件。这个文件包含了项目的元数据和配置信息,包括一系列定义了脚本(scripts)的键值对。 -
解析
scripts对象:npm run start会在package.json文件的scripts对象里查找名为"start"的脚本命令。例如:1"scripts": { 2 "start": "node index.js" 3} -
执行命令:找到
"start"脚本后,npm 会在命令行中执行其定义的命令,如上述例子中的node index.js。这里的命令可以是任何可以在终端或命令提示符下运行的命令,包括启动一个服务器、打包应用等。
2. npm run start 为何能够执行对应命令?
这归功于 npm 的工作方式。npm run 命令是一个通用命令,用于执行 package.json 文件中 scripts 属性下定义的任意脚本。这些脚本可以是几乎任何你希望自动运行的命令行指令。当执行 npm run start 时,npm 会查找并执行与 start 相关联的脚本指令。
使用 npm run start 以及 package.json 中的其他脚本有几个好处:
- 标准化:为常用任务(如启动开发服务器、构建生产代码等)提供一致的命令接口。
- 简化复杂命令:将长长的、可能很复杂的命令简化为一个简单的脚本命令,提高开发效率。
- 跨平台兼容:一些命令(尤其是 UNIX 命令)在不同的操作系统下表现不同。使用 npm 脚本可以通过特定工具(如
cross-env)来实现跨平台兼容。 - 依赖局部安装的包:在 npm 脚本中运行的命令可以直接使用项目
node_modules/.bin目录下安装的本地依赖,无需全局安装或在命令前添加路径。
总结而言,npm run start 以及 package.json 中定义的其他脚本,为项目开发提供了一种灵活、标准化、易于管理的方式来执行各种命令行任务。
892. http 的请求和响应都有哪些传输数据格式【热度: 149】【网络】【出题公司: 美团】
关键词:http 传输格式
HTTP(超文本传输协议)是一种用于传输超媒体文档(如 HTML)的应用层协议。在 HTTP 请求和响应中,可以传输多种数据格式。这些数据格式主要通过 HTTP 头部中的Content-Type字段来指定。下面是一些常见的 HTTP 传输数据格式:
-
text/plain:纯文本格式,不包含任何格式化。 -
text/html:HTML 格式,用于网页。 -
text/css:层叠样式表(CSS)格式,用于样式信息。 -
text/javascript(或application/javascript):JavaScript 代码。 -
application/json:JSON(JavaScript Object Notation)格式,常用于 Web 应用中的数据交换。 -
application/xml:XML(可扩展标记语言)格式,类似于 HTML 但更加通用,也用于数据交换。 -
application/x-www-form-urlencoded:这是 HTML 表单提交时最常用的编码格式,键值对都被编码为键=值对,并且使用&字符分隔。 -
application/form-data:常用于文件上传。在表单数据被编码为一系列键值对时使用,每对键值对都表示为一个表单部分。 -
application/octet-stream:任意的二进制数据。通常用于下载或上传文件。 -
image/png:PNG 图像格式。 -
image/jpeg:JPEG 图像格式。 -
image/gif:GIF 图像格式。 -
image/webp:WebP 图像格式,提供了比 JPEG 更好的压缩。 -
audio/mpeg:MP3 音频格式。 -
audio/ogg:Ogg 音频格式。 -
video/mp4:MP4 视频格式。 -
video/webm:WebM 视频格式,提供高质量的视频压缩。 -
font/woff:Web 开放字体格式。 -
font/woff2:Web 开放字体格式的第二版,较 WOFF 更加高效。
893. http 常见的几个重定向 code 是多少,区别是啥【热度: 172】【网络】【出题公司: 美团】
关键词:http 重定向 code
HTTP 重定向是指当客户端访问一个页面时,服务器返回一个重定向状态码,告诉客户端去访问另一个 URL。常见的 HTTP 重定向状态码有以下几种,每个状态码都有其特定的意义和使用场景:
1. 301 Moved Permanently(永久移动)
- 含义:请求的资源已被永久移动到新位置,未来任何对此资源的引用都应使用返回的新 URI。
- 使用场景:当你永久性地更改了网页的 URL 地址,比如网站改版后结构变化导致 URL 变更。
2. 302 Found(临时移动)/ 307 Temporary Redirect
-
含义(302):请求的资源临时移到了新的 URI 下,客户端应继续使用原有 URI。
-
含义(307):与 302 类似,资源临时从不同的 URI 访问,但保证请求方法(如 POST)不变,307 在 HTTP/1.1 中引入,以明确分清与 302 的本意不同。
-
使用场景:当资源或页面需要临时性地从不同的 URI 访问时使用,且期望方法和消息主体不改变(特别适用 307)。
-
含义:这个状态码用于重定向,目的是让客户端访问新 URI 并使用 GET 方法获取资源,无论原始请求是什么方法。
-
使用场景:通常用于处理表单提交后的重定向,以避免刷新页面时重复提交表单。
4. 308 Permanent Redirect(永久重定向)
-
含义:类似于 301,但它禁止改变请求的方法。因此,例如,应用在一个 POST 请求上时,接下来的请求仍然是一个 POST 请求。
-
使用场景:对于需要保留相同 HTTP 方法(如 POST)情况下的永久重定向。
-
301 和 308:这两个状态码表示资源已被永久移动。区别在于 308 要求后续请求使用与原始请求相同的方法。
-
302 和 307:这两个状态码表示资源临时移动。区别在于 307 明确规定客户端后续请求应使用与原始请求相同的方法,而 302 没有这样的强制规定,但在实际使用中客户端一般会将 POST 请求改变为 GET 请求,从而在一些情况下可能与预期不符。
894. http 的请求和响应报文 有啥区别【网络】【出题公司: TOP100 互联网】
作者备注
可以当做一个科普来看, 单纯的八股, 没有实际价值, 所以不做评分
HTTP 请求和响应报文都遵循类似的结构,但它们服务于通信过程中的不同阶段,并具有一些关键的区别。下面是请求和响应报文之间的主要区别:
-
请求行 vs 状态行:
- 请求报文的第一行是请求行,包含了方法(如 GET、POST)、请求的 URI 和 HTTP 版本。
- 响应报文的第一行是状态行,包含了 HTTP 版本、状态码(如 200、404)和原因短语(如 OK、Not Found)。
-
头部(Headers):
- 请求和响应报文都包含头部(Headers),但具体的头部字段会有所不同。请求头部含有客户端环境信息、请求主体的类型等,而响应头部含有服务器信息、响应主体的类型等。
-
消息主体(Body):
- 请求报文的消息主体(如果有)包含了发送给服务器的数据,比如 POST 请求提交的表单数据。
- 响应报文的消息主体包含了返回给客户端的数据,比如请求的 HTML 页面或是 API 调用的 JSON 数据。
-
请求报文的目的在于告诉服务器客户端想要执行什么操作(比如获取、提交、删除数据等),以及传递必要的数据给服务器(如表单数据)。
-
响应报文的目的在于告诉客户端请求的结果(请求成功、失败、需要进一步操作等),并且可以返回请求的数据(如网页内容)。
-
请求报文由客户端(如浏览器、API 客户端)发起,直接指向服务器,请求特定的资源或操作。
-
响应报文由服务器发起,作为对请求的直接回复,返回数据到客户端。
-
请求报文头部可能包括
User-Agent(客户端信息)、Accept(可接受的响应内容类型)、Content-Type(请求体的类型)等。 -
响应报文头部可能包含
Server(服务器信息)、Content-Type(响应体的类型)、Set-Cookie(设置 Cookie)、Content-Length(响应体长度)等。
尽管 HTTP 请求和响应报文在结构上有很多相似之处,但它们在报文开始行的内容、头部字段以及携带数据的目的方面都存在明显区别。通过了解这些区别,开发者可以更好地理解 HTTP 协议的工作原理,从而更有效地设计和调试 Web 应用。
895. http 的 请求和 响 应报文分 别是什么样的【网络】【出题公司: TOP100 互联网】
HTTP(HyperText Transfer Protocol,超文本传输协议)的请求和响应报文都遵循特定的格式。理解这些格式对于开发 Web 应用和 API 非常重要。以下是 HTTP 请求和响应报文的一般结构:
HTTP 请求报文由三个主要部分组成:请求行、请求头部(Headers)、消息主体(Body)。
-
请求行:
- 包括方法(如 GET、POST)、请求的资源(如 URL)、HTTP 版本(如 HTTP/1.1)。
- 例:
GET /index.html HTTP/1.1
-
请求头部:
-
包括关于客户端环境和请求主体的详细信息,如
Host、User-Agent、Accept、Content-Type等。 -
例:
1Host: www.example.com 2User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) ... 3Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
-
-
消息主体:
-
不是所有的请求都有消息主体,比如 GET 请求通常没有。对于 POST 或 PUT 请求,消息主体包含了发送给服务器的数据。
-
例(表单数据):
1username=john&password=123456
-
HTTP 响应报文也由三个主要部分组成:状态行、响应头部(Headers)、消息主体(Body)。
-
状态行:
- 包括 HTTP 版本、状态码(如 200、404)、状态消息(如 OK、Not Found)。
- 例:
HTTP/1.1 200 OK
-
响应头部:
-
包含了服务器的信息及进一步的操作指示,如
Content-Type、Content-Length、Set-Cookie等。 -
例:
1Content-Type: text/html; charset=UTF-8 2Content-Length: 438
-
-
消息主体:
-
包含了返回给客户端的数据,可能是网页的 HTML,或者是 API 调用的 JSON 数据。
-
例(HTML 内容):
1<html> 2 <head><title>Example</title></head> 3 <body> 4 <h1>Hello, world!</h1> 5 </body> 6</html>
-
1GET /hello.txt HTTP/1.1
2User-Agent: curl/7.58.0
3Accept: */*
4Host: www.example.com 1HTTP/1.1 200 OK
2Date: Wed, 21 Oct 2020 07:28:00 GMT
3Server: Apache/2.4.1 (Unix)
4Content-Type: text/plain
5Content-Length: 13
6
7Hello, world! HTTP 请求和响应报文的结构相对简单,遵循标准的格式,容易解析。了解这些基本的组成部分有助于进行 Web 开发和调试网络通信问题。
876. eslint 如何设置只校验本次 MR 变更的文件内容【热度: 200】【web 应用场景】【出题公司: 小米】
关键词:eslint 和 git 结合校验
要让 ESLint 只校验在 Merge Request (MR)、Pull Request (PR)或代码提交中变更的文件,可以采用几种方法。下面是几个可能的方案:
通过组合git命令和eslint命令来实现。首先,使用git diff获取变更的文件列表,然后将这些文件传递给eslint进行校验。
1# 获取master分支与当前分支变更的文件列表,然后对这些文件执行eslint校验
2git diff --name-only --diff-filter=d master | grep '\.js$' | xargs eslint这里的命令解释:
git diff --name-only --diff-filter=d master:获取相对于master分支变更的文件列表,--diff-filter=d表示排除已删除的文件。grep '\.js$':过滤出.js结尾的文件。xargs eslint:将过滤后的文件列表作为参数传递给eslint命令。
注意:这个命令以master分支作为对比对象,如果你需要对比其他分支,请将master替换为相应的分支名。
2. 使用 lint-staged 运行 ESLint
lint-staged 是一个在 git 暂存文件上运行 linters 的工具,它非常适合与 pre-commit 钩子结合使用,确保只有符合代码规范的代码才能被提交。
首先,安装lint-staged和husky(用于管理 git 钩子的工具):
1npm install lint-staged husky --save-dev然后,你可以在项目的package.json文件中配置lint-staged:
1{
2 "husky": {
3 "hooks": {
4 "pre-commit": "lint-staged"
5 }
6 },
7 "lint-staged": {
8 "*.js": ["eslint --fix", "git add"]
9 }
10}这样配置后,每次执行git commit操作时,husky会触发pre-commit钩子,运行lint-staged,再由lint-staged运行 ESLint 检查所有暂存的.js文件。通过这种方式,只有变更的并且被 git track 的文件会被 ESLint 校验。
在持续集成/持续部署 (CI/CD) 流程中,你也可以配置脚本使用类似于第一个方案的命令,只校验在 MR/PR 中变更的文件。具体实现方式会依赖于你使用的 CI/CD 工具(如 GitLab CI、GitHub Actions、Jenkins 等)。
通过在 CI/CD 流程中加入这一步,可以确保只有通过 ESLint 校验的代码变更才能合并到主分支。
880. 需要详细记录多个操作链路的性能耗时,进行结构化场景分析,该如何做【热度: 378】【web 应用场景】【出题公司: 美团】
关键词:操作链路耗时分析
作者笔记 该问题, 主要是考察两个问题, 怎么定操作节点指标, 怎么去捕获每个阶段时间的耗时
首先对一个操作链路切片:比如一个操作流程, 分拆为第一步, 第二步, 第三步…
然后对每一步一个事件点。
然后统计每一个时间点之间的时间差, 就可以得出用户早操作每一步操作停留的时间。
甚至可以统计一个串行流程, 实际上是一样的。
推荐: performance.mark()
performance.mark() 是 Web Performance API 的一部分,它允许你在浏览器的性能条目缓冲区中创建一个具有特定名称的时间戳(也就是一个”标记”)。这些标记可用于精确测量页面或应用中的特定流程、操作、或某段代码的执行时间。通过使用performance.mark()来标记关键的代码执行点,你可以准确地测量出这些点之间的耗时,从而评估性能和识别瓶颈。
创建标记
要使用performance.mark(),直接调用此函数并传入一个字符串作为标记的名称即可:
1performance.mark("startLoad");
2// 执行一些操作
3performance.mark("endLoad");在上述示例中,startLoad和endLoad是两个标记点,分别表示加载操作的开始和结束。
测量两个标记间的耗时
创建标记后,你可以使用performance.measure()方法来测量这两个标记点之间的耗时。performance.measure()方法同样需要一个名称,并且可以接受两个额外的参数:起始标记和结束标记的名称。
1performance.measure("loadDuration", "startLoad", "endLoad");在上面的代码中,loadDuration是测量的名称,表示从startLoad到endLoad之间的耗时。
获取和分析测量结果
通过performance.getEntriesByName()或其他类似的 API,你可以获取到性能条目并分析结果:
1const measure = performance.getEntriesByName("loadDuration")[0];
2console.log(`加载耗时:${measure.duration}毫秒`);performance.getEntriesByName('loadDuration')会返回一个数组,其中包含所有名为loadDuration的性能条目。在这个例子中,我们取数组的第一个元素,并通过duration属性获取实际的测量时间。
为了避免性能条目缓冲区满了或是数据混乱,你可以在完成测量和分析后,使用performance.clearMarks()和performance.clearMeasures()来清除标记和测量结果。
1performance.clearMarks("startLoad");
2performance.clearMarks("endLoad");
3performance.clearMeasures("loadDuration");performance.mark()非常适合用于测量页面加载、脚本执行、用户交互处理或任何自定义流程的性能。通过准确地标记和测量这些操作的起始和结束时间,开发者可以识别出性能瓶颈和潜在的优化点,从而改进应用的性能表现。
- 并非所有浏览器都支持 Web Performance API 的全部特性。使用这些 API 之前,建议检查兼容性。
- 对于高频率的性能标记和测量,要注意性能条目缓冲区可能会被快速填满,从而影响数据的收集和分析。确保适时清理不再需要的性能条目。
882. websocket 断联之后如何重连,且保证断链期间数据不丢失【热度: 200】【web 应用场景】【出题公司: 腾讯】
关键词:websocket 断联数据不丢失
实现 WebSocket 的自动重连并保证断连期间数据不丢失,通常需要在客户端实现一些机制来管理连接状态、定时重试以及缓存未成功发送的消息。以下是一个简单的步骤和策略指南:
首先,你需要监听 WebSocket 连接的各种事件,以便知道何时发生了断连,并根据这些事件来触发重连逻辑。
-
onclose: 当 WebSocket 连接关闭时,触发重连逻辑。 -
onerror: 出现错误时,也可视为一个触发重连的信号。 -
onopen: 连接成功时,清除重试计数器和缓存的数据(如果之前成功发送了)。 -
使用指数退避算法来延迟重连尝试,避免短时间内频繁重连。
- 例如,第一次重连延迟 1 秒,第二次 2 秒,然后 4 秒,最大延迟设置为 1 分钟。
-
在每次重连时,重置 WebSocket 对象并重新发起连接。
-
发送数据前检查连接状态:如果 WebSocket 处于非开放状态,将数据缓存起来,待连接恢复后再发送。
-
使用队列存储待发送数据:便于按顺序发送,保证数据的完整性和顺序。
-
在连接成功的回调(
onopen事件)中,检查是否有缓存的数据,如果有,则遍历队列发送。
下面是一个示范代码片段:
1var ws;
2var retryInterval = 1000; // 初始重连间隔为 1 秒
3const maxInterval = 60000; // 最大间隔为 1 分钟
4var messageQueue = []; // 数据缓存队列
5
6function connect() {
7 ws = new WebSocket("wss://your-websocket-url");
8
9 ws.onopen = function () {
10 console.log("WebSocket connected");
11 retryInterval = 1000; // 重置重连间隔
12 sendMessageQueue(); // 尝试发送缓存中的数据
13 };
14
15 ws.onclose = function () {
16 console.log("WebSocket disconnected, attempting to reconnect...");
17 setTimeout(connect, retryInterval);
18 retryInterval = Math.min(retryInterval * 2, maxInterval); // 指数退避
19 };
20
21 ws.onerror = function (error) {
22 console.error("WebSocket error:", error);
23 ws.close(); // 确保触发 onclose 事件
24 };
25
26 ws.onmessage = function (message) {
27 // 处理接收到的数据
28 };
29}
30
31function sendMessage(data) {
32 if (ws.readyState === WebSocket.OPEN) {
33 ws.send(data);
34 } else {
35 console.log("WebSocket is not open. Queuing message.");
36 messageQueue.push(data); // 缓存待发送数据
37 }
38}
39
40function sendMessageQueue() {
41 while (messageQueue.length > 0) {
42 const data = messageQueue.shift(); // 获取并移除队列中的第一个元素
43 sendMessage(data); // 尝试再次发送
44 }
45}
46
47connect(); // 初始化连接这个示例实现了基本的重连逻辑和数据缓存策略。在实际应用中,根据实际需求对这些逻辑进行扩展和定制化是很有必要的,尤其是数据缓存和发送逻辑,可能需要结合业务特点进行更复杂的处理。
特别是数据缓存这个场景, 如果有多个 webscoket 数据, 建议使用 indexedDB 做一个系统级别的数据管理。
885. 如何做静态资源预加载【热度: 696】【web 应用场景】【出题公司: 腾讯】
关键词:资源预加载
预加载是指在用户需要数据或资源之前,提前加载这些数据或资源的过程。
这个过程可以提高应用程序或网站的响应速度和用户体验
- 提升加载速度:通过提前加载资源,用户在访问页面时可以更快地看到完整内容。
- 提高用户体验:减少页面加载时的延迟,使用户感到更流畅。
- 优化资源使用:合理安排资源加载顺序,提高网络利用率。
下面的示例将展示如何使用 Web Worker 来预加载静态资源。我们将创建一个简单的 Web Worker 脚本,用于在后台预加载一些指定的静态资源(例如图片、CSS、JavaScript 文件等)。这个过程不会阻塞主线程,使得主线程可以继续处理其他任务,如用户交互,从而提升页面的响应性能。
###3 步骤 1:创建 Web Worker 脚本
首先,创建一个 JS 文件作为 Web Worker 的脚本。我们把这个文件命名为 preloadWorker.js。
1// preloadWorker.js
2
3self.addEventListener("message", (e) => {
4 const urls = e.data;
5 urls.forEach((url) => {
6 fetch(url)
7 .then((response) => {
8 // 一个简单的操作,标识资源已被预加载
9 if (response.status === 200) {
10 postMessage(`Resource preloaded: ${url}`);
11 } else {
12 postMessage(`Resource failed: ${url}`);
13 }
14 })
15 .catch((error) => {
16 postMessage(`Resource fetch error: ${url}`);
17 });
18 });
19});这个脚本监听来自主线程的消息,该消息包含了要预加载的资源的 URL 列表。对于每个 URL,它使用 fetch 请求该资源。根据请求的结果,它会通过 postMessage 向主线程发送一条消息,表明该资源已被预加载,或者载入失败。
接下来,在 HTML 页面中使用这个 Web Worker。
首先,确保在你的 HTML 中引入一个脚本,初始化并使用这个 Web Worker。
1<!DOCTYPE html>
2<html lang="en">
3 <head>
4 <meta charset="UTF-8" />
5 <title>Web Worker Preload Demo</title>
6 </head>
7 <body>
8 <script src="main.js"></script>
9 </body>
10</html>然后,创建主线程脚本 main.js 用于启动和与 Web Worker 交互。
1// main.js
2
3if (window.Worker) {
4 const worker = new Worker("preloadWorker.js");
5
6 const resources = [
7 "image.png", // 示例资源,确保替换为实际的 URL
8 "style.css",
9 "script.js",
10 ];
11
12 worker.postMessage(resources);
13
14 worker.onmessage = (e) => {
15 console.log(e.data);
16 };
17} else {
18 console.log("Your browser doesn't support web workers.");
19}这段脚本首先检查浏览器是否支持 Web Worker。如果支持,它会创建一个指向 preloadWorker.js 的新 Worker 实例,然后将要预加载的资源列表发送给这个 Worker。最后,它设置一个事件监听器来接收并处理 Worker 发出的消息。
886. [webpack] 代码分割中,让所有的外部依赖打成一个包,源码 source 打成一个包,该如何配置【热度: 352】【工程化】【出题公司: 阿里巴巴】
关键词:webpack 代码分割
为了实现你的需求,即将所有外部依赖(node_modules 中的依赖)打包成一个单独的包,而你自己的源码打包成另一个包,可以通过配置 Webpack 的 optimization.splitChunks 选项来实现。下面是具体的实施方案:
在你的 webpack.config.js 配置文件中,找到或添加 optimization 部分,并在 splitChunks 中配置如下:
1module.exports = {
2 // ...其他配置
3
4 optimization: {
5 runtimeChunk: "single", // 为 webpack 运行时代码创建一个额外的包
6 splitChunks: {
7 cacheGroups: {
8 vendor: {
9 // 定义一个缓存组用以分离外部依赖
10 test: /[\\/]node_modules[\\/]/, // 检索 node_modules 目录下的模块
11 name: "vendors", // 分离后的包名称
12 chunks: "all", // 对所有模块生效
13 },
14 source: {
15 // 我们可以通过添加另一个缓存组来实现源码的分离(如果需要)
16 test: /[\\/]src[\\/]/, // 检索 src 目录
17 name: "source",
18 chunks: "all",
19 },
20 },
21 },
22 },
23};runtimeChunk: 'single'创建一个运行时文件,管理模块化交互,比如加载和解析模块。- 在
splitChunks.cacheGroups中定义了两个缓存组:vendor:这个缓存组的目标是将来自node_modules目录的所有代码移动到命名为vendors的包中。它通过test属性来匹配node_modules目录下的模块。source:这个部分是为了演示如何单独将src目录下的源代码打包成一个文件。这不是必须的,因为默认情况下,Webpack 会将未被上述规则匹配到的模块(即你的源代码)打包到主包中。
887. [webpack] 如何优化产物大小【热度: 521】【工程化】【出题公司: 阿里巴巴】
关键词:webpack 产物大小优化
在使用 Webpack 进行项目构建时,减少包体积是提升加载速度、改善用户体验的关键措施之一。以下是一些通用的方法和技巧来减小构建结果的包体积:
Tree Shaking 是一个通过清除未引用代码(dead-code)的过程,可以有效减少最终包的大小。确保你的代码使用 ES6 模块语法(import 和 export),因为这允许 Webpack 更容易地识别并删除未被使用的代码。
在 webpack.config.js 中设置 mode 为 production 可自动启用 Tree Shaking。
Webpack 通过压缩输出文件来减小包大小,如删除未使用的代码、缩短变量名等。确保在生产环境中启用了 UglifyJS 插件或 TerserPlugin。
1const TerserPlugin = require("terser-webpack-plugin");
2
3module.exports = {
4 optimization: {
5 minimize: true,
6 minimizer: [
7 new TerserPlugin({
8 /* 附加选项 */
9 }),
10 ],
11 },
12};通过代码分割,你可以把代码分成多个 bundle,然后按需加载,从而减少初始加载时间。Webpack 提供了多种分割代码的方式,最常见的是动态导入(Dynamic Imports)。
1import(/* webpackChunkName: "my-chunk-name" */ "path/to/myModule").then((module) => {
2 // 使用module
3});通过配置 externals 选项,可以阻止 Webpack 将某些 import 的包打包到 bundle 中,而是在运行时(runtime)再去从外部获取这些扩展依赖。
1module.exports = {
2 externals: {
3 jquery: "jQuery",
4 },
5};使用 [contenthash] 替换 [hash] 或 [chunkhash] 来为输出文件命名,这确保了只有当文件内容改变时,文件名称才会改变,可以更好地利用浏览器缓存。
1output: {
2 filename: '[name].[contenthash].js',
3}使用 PurgeCSS 或purify-css等工具检查你的 CSS 文件,自动去除未使用的 CSS,可以极大地压缩 CSS 的体积。
1const PurgecssPlugin = require("purgecss-webpack-plugin");使用image-webpack-loader等图片压缩插件,可以减小图片文件的体积。
1module: {
2 rules: [
3 {
4 test: /\.(png|svg|jpg|jpeg|gif)$/i,
5 use: [
6 'file-loader',
7 {
8 loader: 'image-webpack-loader',
9 options: {
10 // 配置选项
11 },
12 },
13 ],
14 },
15 ],
16}只为那些实际需要它们的浏览器提供 polyfills,而不是所有浏览器都提供。
以上方法和技巧可以根据项目的具体需求和情况灵活使用,有的方法可能会对构建和重构现有代码产生较大影响,因此在采用前应评估其必要性和影响。
将代码编译(或者说不编译)为 ES6(ECMAScript 2015)或更高版本的 JavaScript 代码,确实可以减少产物体积。
891. 发送请求的时候, method = OPTIONS 是什么请求【热度: 717】【网络】【出题公司: 小米】
关键词:预检请求
当看到 method 为 OPTIONS 的请求时,这是一个 HTTP OPTIONS 请求。OPTIONS 请求是 HTTP/1.1 协议中定义的一种方法,用于获取目的资源(服务器)支持的通信选项。这种请求主要被用于 CORS(Cross-Origin Resource Sharing,跨域资源共享)预检请求,在真正的跨域请求被发送之前执行。
- 确定服务器的支持性:客户端通过发送一个 OPTIONS 请求来确定服务器支持的 HTTP 方法(如 GET、POST、DELETE 等)。
- CORS 预检请求:在发送实际的跨域请求前,浏览器会自动发出一个 OPTIONS 预检请求,询问目标资源的服务器是否允许该跨域请求。这个步骤用来确保安全,避免非法站点调用敏感资源。
在 CORS 上下文中,OPTIONS 请求会包含一些 HTTP 头,指明了实际请求将会使用哪些 HTTP 方法和头部。服务器响应该请求时会指明允许的方法、头部和是否允许带有凭证的请求(如 Cookies)。重要的 HTTP 头包括:
-
Access-Control-Request-Method:在预检请求中,这个头部告诉服务器实际请求将使用的 HTTP 方法是什么。 -
Access-Control-Request-Headers:当实际请求中需要携带额外的头部时,这个字段会列出它们。 -
Access-Control-Allow-Methods:在响应中,这个头部告诉客户端服务器允许的方法。 -
Access-Control-Allow-Headers:在响应中,这个头部告诉客户端服务器允许的头部。 -
Access-Control-Allow-Origin:这个头部指明了哪些源可以访问该资源。如果服务器支持请求的源,则会在响应中包含这个头部。
当您的 Web 应用尝试从另一个域名(源)的服务器获取资源时,浏览器会首先发起一个 OPTIONS 请求。例如,如果您的前端应用运行在 http://example.com 并尝试通过 AJAX 请求 http://api.example.com/data,浏览器会先发送 OPTIONS 请求到 http://api.example.com/data。服务器响应该请求后,如果允许此类请求,则浏览器会继续发起实际的 GET/POST/等请求;如果不允许,则停止请求。
总的来说,OPTIONS 请求是 HTTP 规范的一部分,它是 CORS 预检机制中非常重要的一步,用于在实际跨域请求发出之前确定通信的可能性和条件。
875. 请求数量过多,该如何治理【热度: 418】【网络】【出题公司: 阿里巴巴】
关键词:治理请求数量
作者备注
很多同学我有 http2 , 可以多路复用, 所以请求再多都不会影响页面性能。 实际上是错误的。 在作者知道的很多超大型项目(千万行级别的项目)里面, 太多的网络并发(首屏可能就有好大几百的请求发出去), 会因为 IO 问题到时吃掉很多的 CPU 与网络带宽, 用户依然会觉得非常的卡顿。 所以这个话题是非常有意义的。 但是实际中遇到请求过多的问题, 场景是非常少的。 目前作者暂定 该问题级别为 「资深」 而且该问题没有一个准确的答案, 作者在这里知识提供干一些思路。
1. 常量请求做本地内存存储
不是使用 https 缓存, 而是直接存一个 promise 在浏览器内存里面。 保证整个系统里面, 请求只调用一次。
对于一些数据不经常变化的请求,例如用户信息、配置数据等,可以将请求的结果缓存起来。下一次请求相同的资源时,先从缓存中读取数据,如果缓存有效,则无需再发起新的网络请求。
思路类似于下面这张图 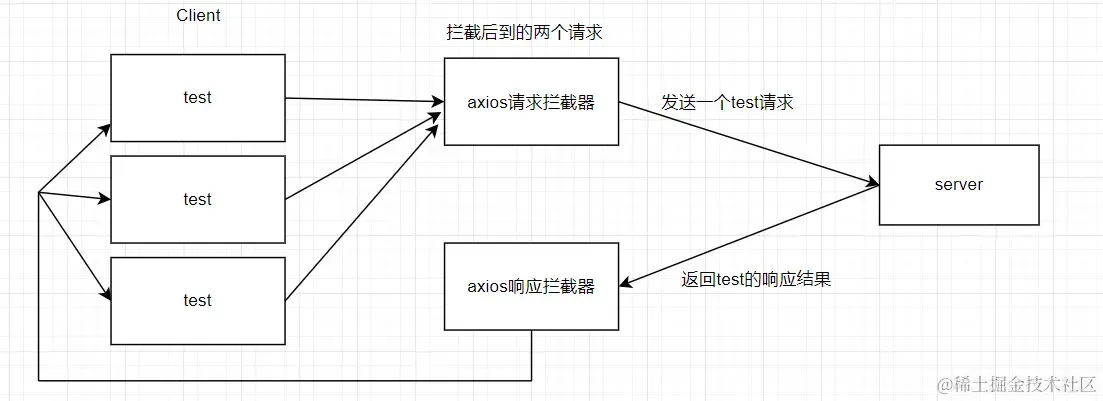
要达到这样的效果,可以设计一个请求缓存管理器,来管理并发的请求。如果有相同的请求(URL、参数、方法相同)时,只发起一次网络调用,然后将结果分发给所有等待的请求。这种模式通常可以通过一个简单的缓存对象来实现,该对象将请求的唯一标识作为键,对应的 Promise 作为值。
以下是一个基本实现的示例:
1class RequestCache {
2 constructor() {
3 this.cache = new Map();
4 }
5
6 // 生成请求的唯一标识符,这里仅以 URL 和 Method 为例,实际可能需要包括请求体等
7 generateKey(url, method) {
8 return `${method}:${url}`;
9 }
10
11 // 执行请求的方法,接受 fetch 的所有参数
12 request(url, options = {}) {
13 const { method = "GET" } = options;
14 const key = this.generateKey(url, method);
15
16 // 检查缓存中是否有相同的请求
17 if (this.cache.has(key)) {
18 return this.cache.get(key);
19 }
20
21 // 没有相同的请求,发起新的请求
22 const requestPromise = fetch(url, options)
23 .then((response) => response.json())
24 .then((data) => {
25 // 请求成功后,将其从缓存中移除
26 this.cache.delete(key);
27 return data;
28 })
29 .catch((error) => {
30 // 请求失败也应该从缓存中移除
31 this.cache.delete(key);
32 throw error;
33 });
34
35 // 将新的请求 Promise 保存在缓存中
36 this.cache.set(key, requestPromise);
37
38 return requestPromise;
39 }
40}
41
42// 使用示例
43const cache = new RequestCache();
44const URL = "https://api.example.com/data";
45
46// 假设这三个请求几乎同时发起
47cache.request(URL).then((data) => console.log("请求1:", data));
48cache.request(URL).then((data) => console.log("请求2:", data));
49cache.request(URL).then((data) => console.log("请求3:", data));这个简单的 RequestCache 类通过一个内部的 Map 对象管理缓存的请求。当一个新的请求发起时,它会首先检查是否已经有相同的请求存在。如果已存在,那么它只返回先前请求的 Promise;如果不存在,它会发起一个新的网络请求,并将请求的 Promise 存储在缓存中,直到请求完成(无论是成功还是失败)之后,再将其从缓存中移除。
请注意,这里的示例非常基础,且主要用于说明如何缓存并复用请求的结果。在实际应用中,你可能还需要考虑更多细节,比如如何更精细地处理 POST 请求的请求体内容、如何设置缓存的过期时间、错误处理策略、缓存大小限制等。
推荐参考文档: https://juejin.cn/post/7341840038964363283
2. 合并请求
对于多个小请求,特别是对同一个服务器或 API 的调用,考虑将它们合并为一个较大的请求。例如,如果有多个 API 分别获取用户信息、用户订单、用户地址等,可以考虑后端提供一个合并接口,一次性返回所有所需数据。
3. 使用 Web 缓存
- 浏览器缓存:利用 HTTP 缓存头控制静态资源(CSS、JS、图片)的缓存策略,减少重复请求。
- 数据缓存:对于 AJAX 请求的响应,可以在前端进行数据缓存,避免短时间内对相同资源的重复请求。
4. 延迟加载(懒加载)
对于非首屏必须的资源(如图片、视频、长列表等),可以采用延迟加载或懒加载的方式,只有当用户滚动到相应位置时才加载这些内容,减少初次加载时的请求数量。
5. 使用服务工作线程(Service Workers)
通过 Service Workers 可以拦截和缓存网络请求,实现离线体验,减少对服务器的请求。此外,Service Workers 还可以用于请求合并、请求失败的重试策略等。
6. 避免重复请求
在某些情况下,为了保证数据的实时性,前端可能会频繁地轮询服务器。可以通过设置合理的轮询间隔或采用基于 WebSocket 的实时数据推送方案,以减少请求次数。
7. 使用 GraphQL
对于 REST API 可能导致的过度取数据(over-fetching)或取少数据(under-fetching)问题,可以考虑使用 GraphQL。GraphQL 允许客户端准确指定所需数据的结构,一次请求准确获取所需信息,减少无效数据的传输。
8. 防抖和节流
在处理连续的事件触发对后端的请求(如输入框实时搜索、窗口大小调整等)时,使用防抖(debouncing)和节流(throttling)技术可以限制触发请求的频率,减少不必要的请求量。
888. monorepo 工程有哪些工具架构, 该如何选型【热度: 450】【工程化】【出题公司: 阿里巴巴】
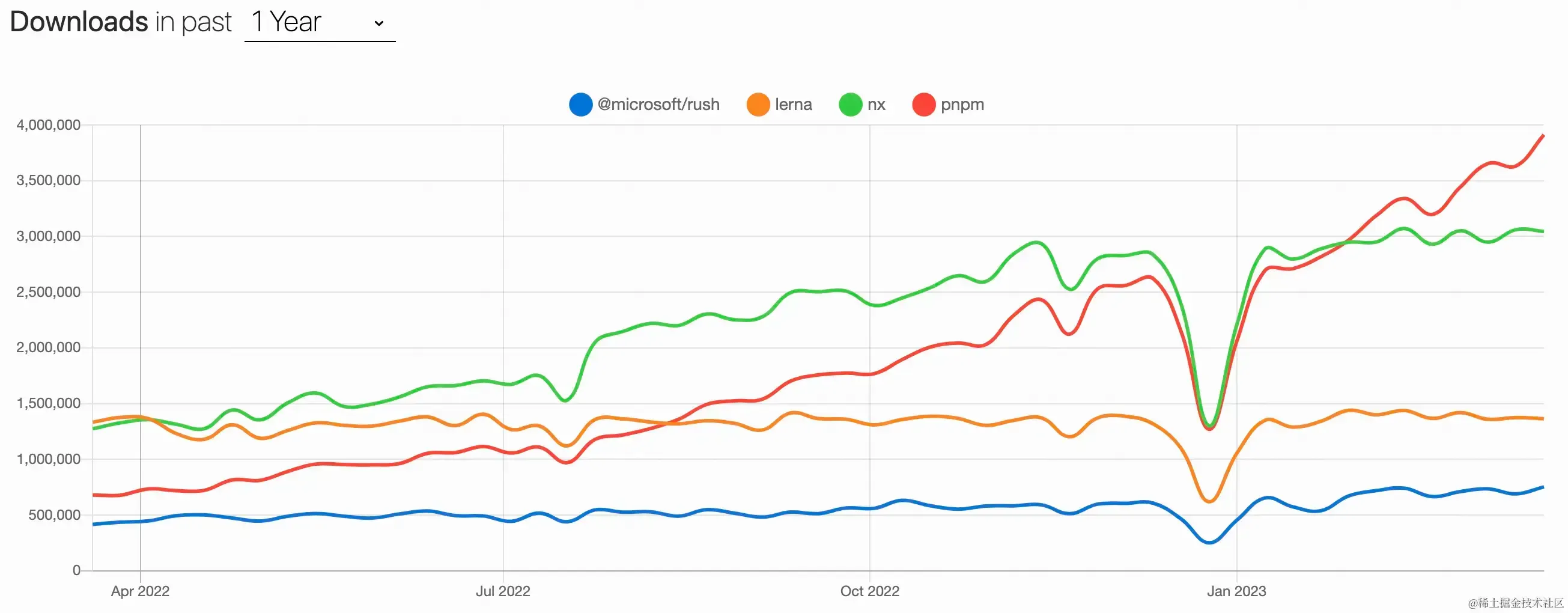
关键词:monorepo 技术选项
| 工具 | Turborepo | Rush | Nx | Lerna | Pnpm Workspace |
|---|---|---|---|---|---|
| 依赖管理 | ❌ | ✅ | ❌ | ❌ | ✅ |
| 版本管理 | ❌ | ✅ | ❌ | ✅ | ❌ |
| 增量构建 | ✅ | ✅ | ✅ | ❌ | ❌ |
| 插件扩展 | ✅ | ✅ | ✅ | ❌ | ❌ |
| 云端缓存 | ✅ | ✅ | ✅ | ❌ | ❌ |
| Stars | 20.4K | 4.9K | 17K | 34.3K | 22.7K |
选择合适的 Monorepo 管理工具对于确保项目的顺利进行是至关重要的。Monorepo 管理工具可以帮助你高效地��理项目依赖、统一代码风格、简化开发流程等。在进行 Monorepo 工具选型时,需要考虑几个重要的因素:
-
Lerna:与任何技术栈兼容性都很好,特别是与前端项目协同工作时。它对 NPM 和 Yarn 都有良好支持,适用于需要独立版本管理或频繁发布的项目。
-
Yarn Workspaces:特别适合使用 Yarn 作为包管理器的 JavaScript 或 TypeScript 项目。它非常适合团队中包之间有很多交叉依赖的情形。
-
Nx:支持多种前端和后端框架,如 Angular、React、NestJS 等。如果项目采用多技术栈,Nx 提供了一套完整的解决方案,包含了构建、测试和 linting 等一站式服务。
-
Rush:同样适用于大型项目,兼容任何 NPM 包管理器,如 NPM、Yarn、pnpm。Rush 提供了灵活的版本控制策略,非常适合需要精细控制包版本策略的场景。
-
pnpm Workspaces:具有高效的节点模块解析机制,非常注重节省磁盘空间及速度优化。如果磁盘空间和安装速度是关键考虑因素,pnpm 会是一个不错的选择。
-
对于大型或复杂项目,Nx 和 Rush 提供了更多的高级特性,比如增量构建、依赖图可视化等,可以有效提升大团队的开发效率。
-
对于中小型项目,Lerna、Yarn Workspaces 或 pnpm Workspaces 可能更易上手,配置和管理也较为简单。
-
如果项目需要复杂的构建、测试流程,Nx 提供了一些很好的工具来优化这一过程。Nx 可以智能地只重新构建受影响的项目,节省 CI/CD 的时间和资源。
-
Rush 强调在大型仓库中提供稳定而灵活的版本策略和发布管理,对于需要精细控制不同环境部署的项目非常有用。
-
所有这些工具都支持代码共享和重用,但是Nx 和 Rush 在支持大型团队和多项目协作方面有一些额外的优势,如更智能的依赖管理和版本控制。
-
Nx 拥有强大的社区支持和丰富的文档、教程,非常适合于新技术栈的团队。
-
Lerna 和 Yarn Workspaces 受众广泛,网上有很多资源和案例,学习曲线相对平缓。
如果你的项目非常关注于构建效率和对多种技术栈的支持,Nx 是非常好的选择。如果你更关心包的独立发布和版本管理,Lerna 和 Rush 可以满足你的需求。而对于那些偏好 Yarn 并且注重依赖管理的项目来说,Yarn Workspaces 提供了一套简单直接的解决方案。如果磁盘空间和安装速度是你的主要考虑,不妨试试 pnpm Workspaces。