本文将从vite-plugin-vue的源码带着大家一起分析我们在使用vite开发Vue项目的时候vite所处理的一些流程,本文不会讲解API的使用,因为本文的难度偏难,如果仅仅是想学习如何配置vite,本文可能不太适合您。
在阅读本文之前,请确保你对vite的基本原理有一定的了解(不一定是了解源码,但是至少要对vite的整体运行过程有一个较为清楚的认识)。众所周知,在webpack的的生态中,我们通过Vue提供的Loader,分别对Vue单文件组件的template、script、style部分分别进行编译,最终转成浏览器可以识别的文件,我们也会有惯性思维,根据这个经验,我们来看看vite是如何处理Vue单文件组件的。
1、虚拟模块技术
关于什么是vite的插件的内容,我就不赘述了,大家可以查看vite的官方文档。插件 API | Vite 官方中文文档 (vitejs.cn)
首先,我们在vite的官方文档上先看一下什么是虚拟模块。插件 API | Vite 官方中文文档 (vitejs.cn)
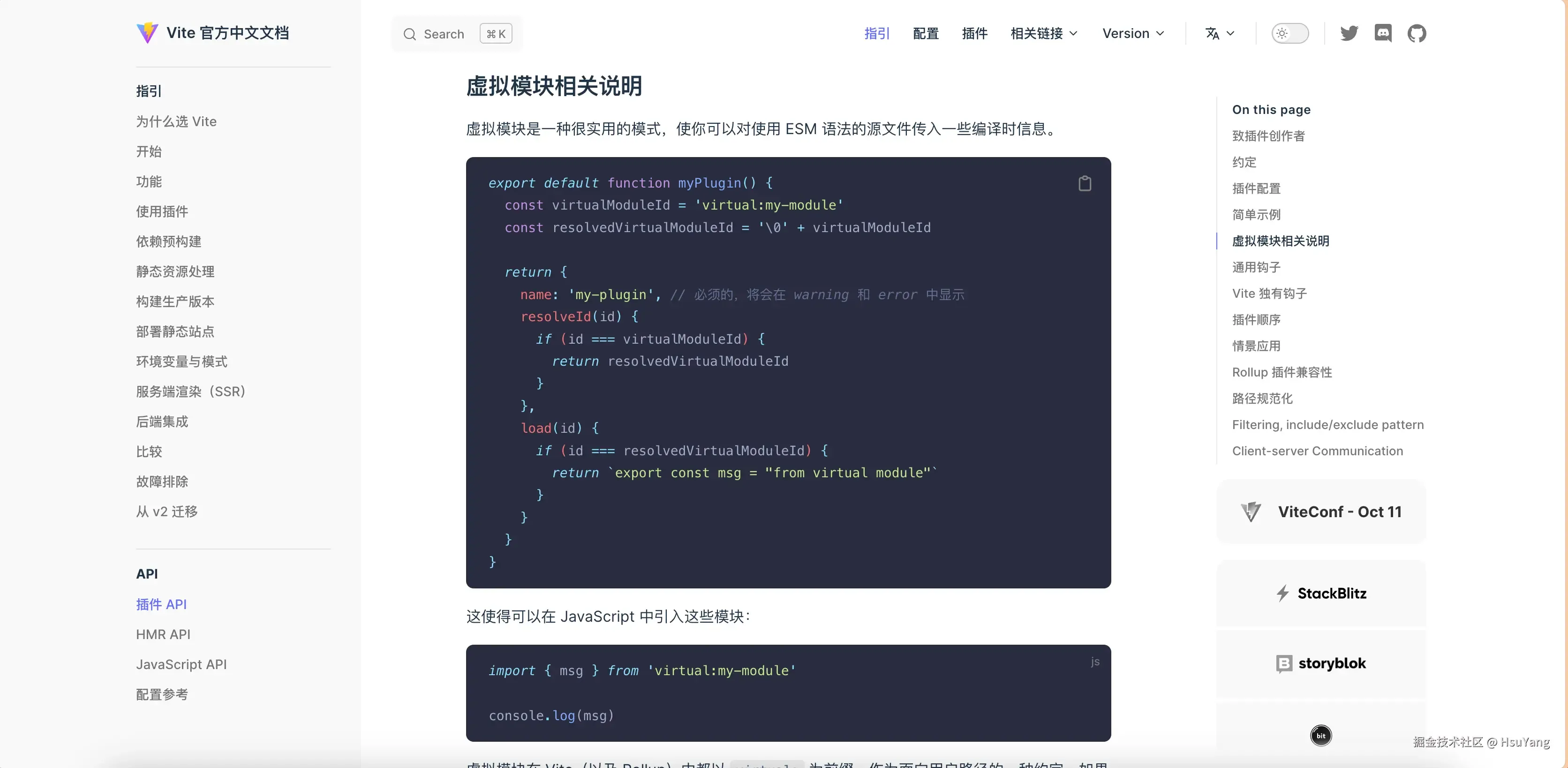
虚拟模块是Rollup所提供的能力,虚拟模块技术可以使得我们在加载文件的内容时,它的来源并不一定是磁盘,而可以是一个我们动态生成到内存中的内容。
在Rollup的文档插件开发的开头就有所提及。插件开发 | Rollup 中文文档 (rollupjs.org)
2、Rollup的几个常用的生命周期
Rollup的生命周期,是设计模式职责链模式的一个实践,关于职责链模式,如果有不清楚的同学,可以查阅我之前的文章。设计模式在前端开发中的实践(八)——职责链模式职责链模式
在学习vite-vue-plugin这个插件中,我们主要关心3个生命周期,分别是resolveId,load,transform。
Rollup的文档写的真的有点儿晦涩难懂,所以,对于这3个生命周期,我是选择直接问的Chatgpt。
resolveId生命周期:用于在模块解析过程中自定义模块的解析逻辑。这个钩子可以帮助你控制模块的解析方式,比如解析别名、处理虚拟模块、或者从自定义位置加载模块。当这个函数的返回值为null或者undefined的时候,让Rollup执行默认的解析逻辑,我们返回其它的内容的话,则可以改变这个逻辑。
转换成大白话就是,对于当前的内容,如果你感兴趣,你就处理,如果你不感兴趣,你就返回null或者undefined,别的对这个内容感兴趣的插件会知道处理的。
1export default {
2 input: 'src/main.js',
3 output: {
4 file: 'bundle.js',
5 format: 'es'
6 },
7 plugins: [
8 {
9 name: 'example-plugin',
10 resolveId(source, importer) {
11
12 if (source === '@alias/my-module') {
13 return 'actual/module/path.js';
14 }
15
16
17 if (source === 'some-module') {
18 return source;
19 }
20
21
22 return null;
23 },
24 load(id) {
25
26 if (id === 'some-module') {
27 return 'export default "This is virtual!"';
28 }
29 return null;
30 }
31 }
32 ]
33};
比如上面这个Demo里面,假设我们在写代码的过程中用到了路径别名,当我们读取某个路径别名的内容的时候,我们可以给它指定到某个特定的路径下;当我们引入一个虚拟模块的时候,返回特定的标识,这样可以在后面的生命周期load执行的过程中读取虚拟模块而不是从磁盘加载。总而言之,在这个过程中,就是把我们源代码里面的路径通过编程的方式转变成最终真实的路径的过程(虚拟模块也可以把它视为一个特殊的真实路径)
load生命周期:用于在 Rollup 打包过程中加载特定模块的内容。它允许你在模块加载过程中插入自定义逻辑,比如修改模块内容、读取文件内容,或者根据特定条件返回不同的模块内容。所以,我们可以在load钩子里面读取磁盘的内容并返回,也可以直接返回内容(虚拟模块)。如果不返回的话,则认为当前插件不对这个传入的路径做处理(毕竟每个插件只完全自己感兴趣的事儿,又不是老黄牛什么事儿都做,哈哈哈)
以下是一个Demo:
1import fs from 'fs';
2
3export default {
4 input: 'src/main.js',
5 output: {
6 file: 'bundle.js',
7 format: 'es'
8 },
9 plugins: [
10 {
11 name: 'example-plugin',
12 load(id) {
13
14 if (id === 'virtual-module') {
15 return 'export default "This is virtual!"';
16 }
17
18
19 if (id.endsWith('.txt')) {
20 const content = fs.readFileSync(id, 'utf-8');
21 return `export default ${JSON.stringify(content)}`;
22 }
23
24
25 return null;
26 }
27 }
28 ]
29};
到这儿,不知道各位同学是不是看的有点儿云里雾里的?反正我刚开始学习的时候理解了很久。resolveId就是在确定加载路径,而load就是在加载内容。
这儿,我们就引出来了一个新的疑问,对于虚拟模块,我可不可以在resolveId这个周期里面什么都不做呢?然后我在load方法里面发现这个ID是我认为的虚拟模块的ID,然后我返回内容。Chatgpt是这样解释的:有模块构建失败的风险、缓存和性能问题,resolveId 钩子明确地将模块标记为虚拟模块,有助于 Rollup 缓存和优化构建过程。如果返回 null,Rollup 可能会进行不必要的额外解析步骤,影响构建性能。通过 resolveId 钩子标记虚拟模块,确保了模块路径的一致性和正确性。直接在load钩子中处理可能导致路径混淆或不一致。
因此,我们必须要遵守Rollup插件的开发规范。
transform生命周期:用于在模块被加载后、打包前对模块的内容进行转换。它允许你在构建过程中插入自定义的转换逻辑,比如编译代码、替换内容、或者添加额外的代码。transform 钩子非常强大,可以用来实现各种自定义的代码处理需求。
这个生命周期非常好理解,我们可以在这个生命周期中进行编译,例如从 TypeScript 编译为 JavaScript,或者将 JSX 编译为 JavaScript。可以在模块代码中替换特定的字符串或者注入额外的代码。可以为模块添加 Source Maps,注入等元数据,以便在调试时提供更好的信息。后面说的2个操作也是有一定的实际意义,比如vite的插件注入vconsole(用于移动端调试的插件)就是这样做的。
1export function viteVConsole(opt: viteVConsoleOptions): Plugin {
2 const {
3 entry,
4 enabled = true,
5 config = {},
6 plugin,
7 customHide = false,
8 dynamicConfig = {},
9 eventListener = ''
10 } = opt;
11
12
13 let entryPath = Array.isArray(entry) ? entry : [entry];
14 if (process.platform === 'win32')
15 entryPath = entryPath.map((item) => item.replace(/\\/g, '/'));
16
17
18 const enabledTruly = enabled;
19 return {
20 name: 'vite:vconsole',
21 enforce: 'pre',
22 transform(_source: string, id: string) {
23 if (entryPath.includes(id) && enabledTruly) {
24 const code = `/* eslint-disable */;
25 import VConsole from 'vconsole';
26 // config
27 const vConsole = new VConsole({${parseVConsoleOptions(
28 config as Record<string, unknown>
29 )}});
30 window.vConsole = vConsole;
31 // 省略其它内容
32 /* eslint-enable */${_source}`;
33
34 return {
35 code,
36 map: null
37 };
38 }
39 return {
40 code: _source,
41 map: null
42 };
43 }
44 };
45}
上述Demo就是在原内容的基础上追加了内容,从而实现注入了调试工具。
好了,在搞明白这些生命周期的用途之后,我们开始分析vite-plugin-vue的源码了。
在这节中主要向大家解释我对其源码的理解,如有纰漏敬请谅解,欢迎大家指出纠正。
1、加载编译器
首先,在插件构建开始的时候,插件尝试读取编译器,若读取不到则抛出错误。
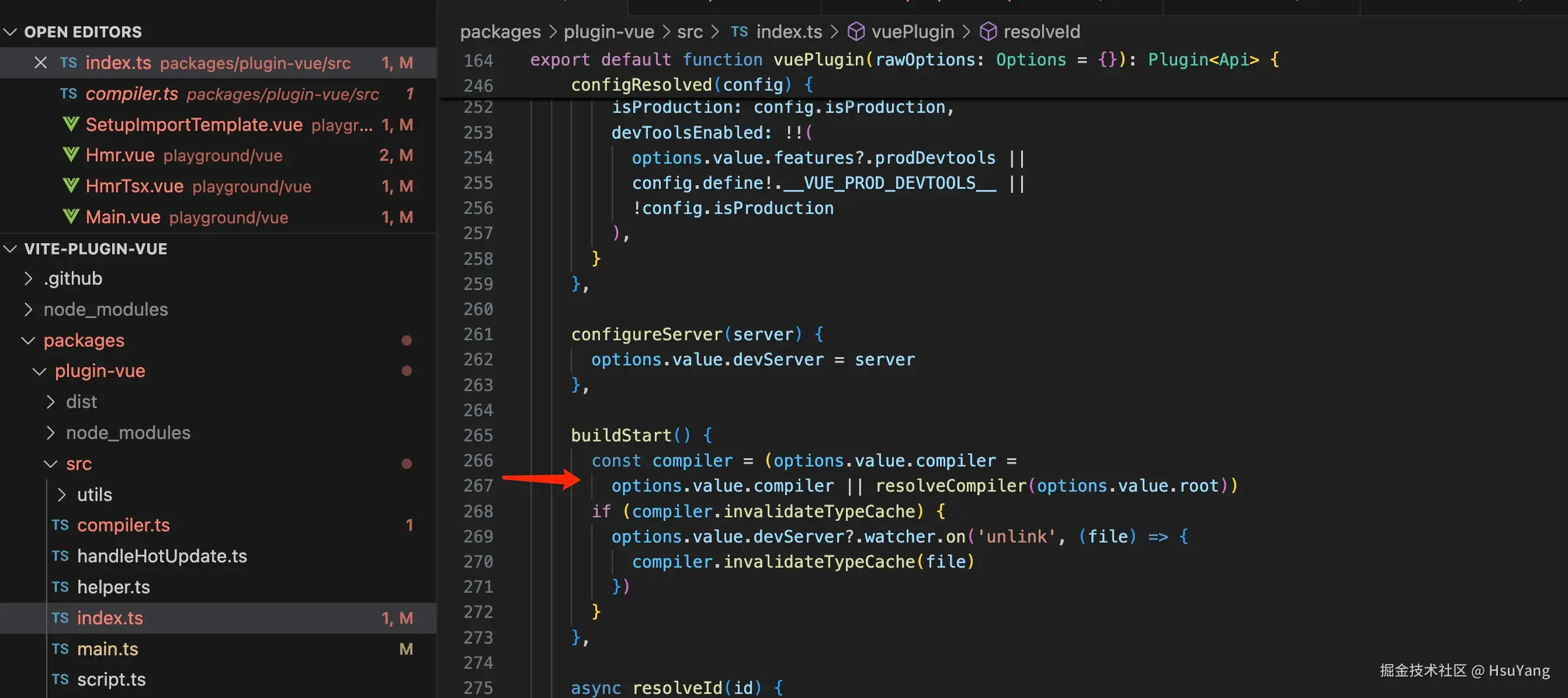 可以看到,我们其实是可以自定义编译器的哦。
可以看到,我们其实是可以自定义编译器的哦。 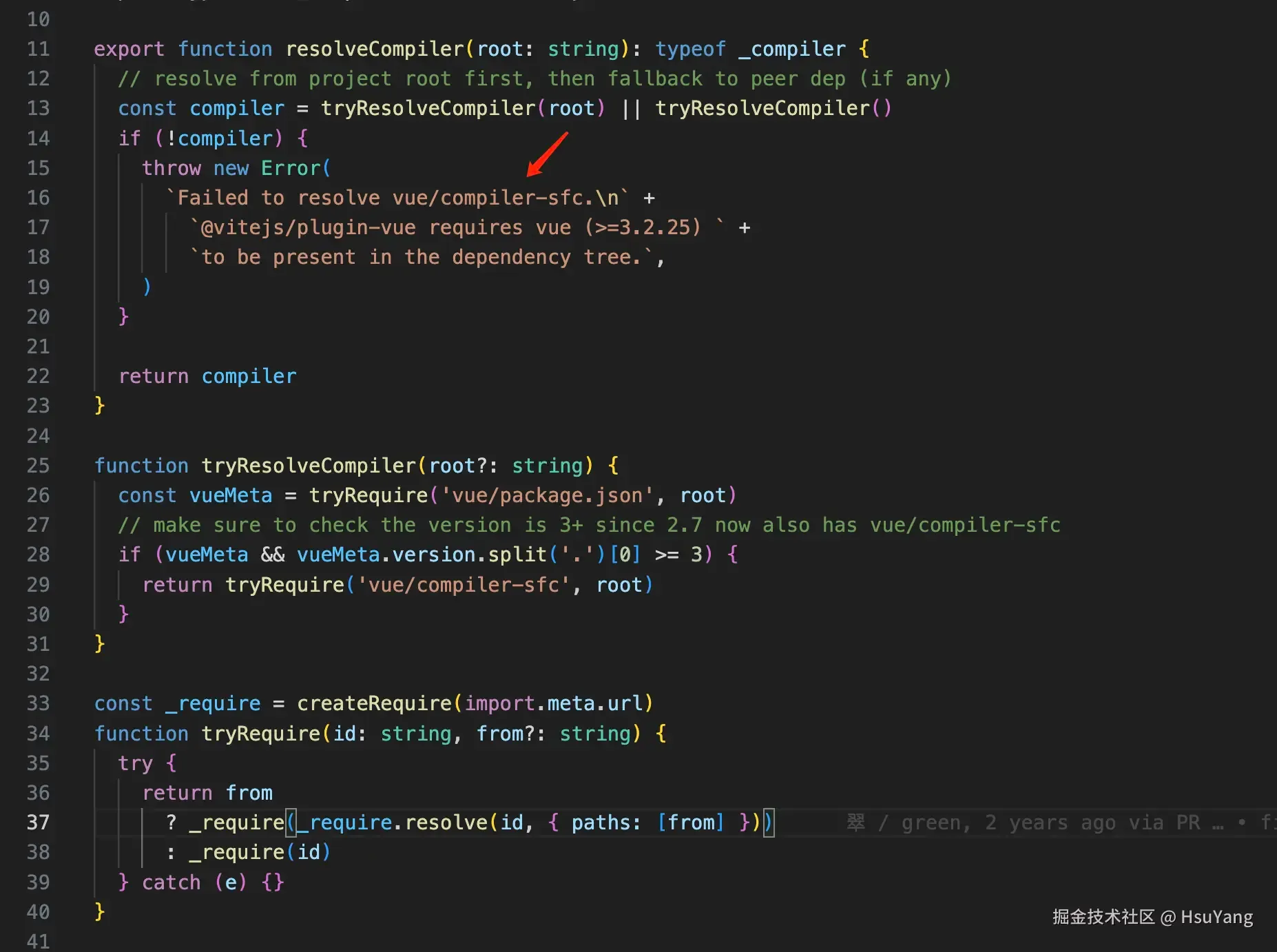 然后加载编译器之后,就可以编译了,我们接着看。
然后加载编译器之后,就可以编译了,我们接着看。
2、处理虚拟模块
在这个部分,主要是vite自己内部的一个工具模块的处理,以及把.vue这种单文件组件视为一个虚拟模块(因为一会儿,template、script、style是要被拆成对应的模块的,磁盘上肯定是没有这样的文件的) 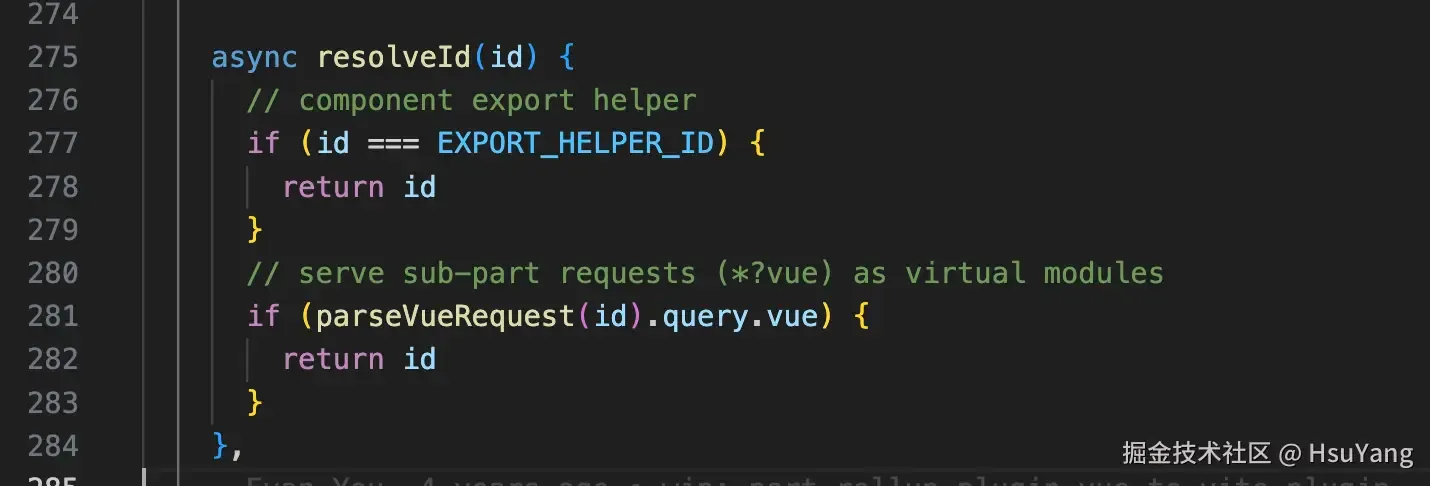 这个工具模块在哪儿呢,我们随便点开网络请求中的一个文件,可以看到。
这个工具模块在哪儿呢,我们随便点开网络请求中的一个文件,可以看到。 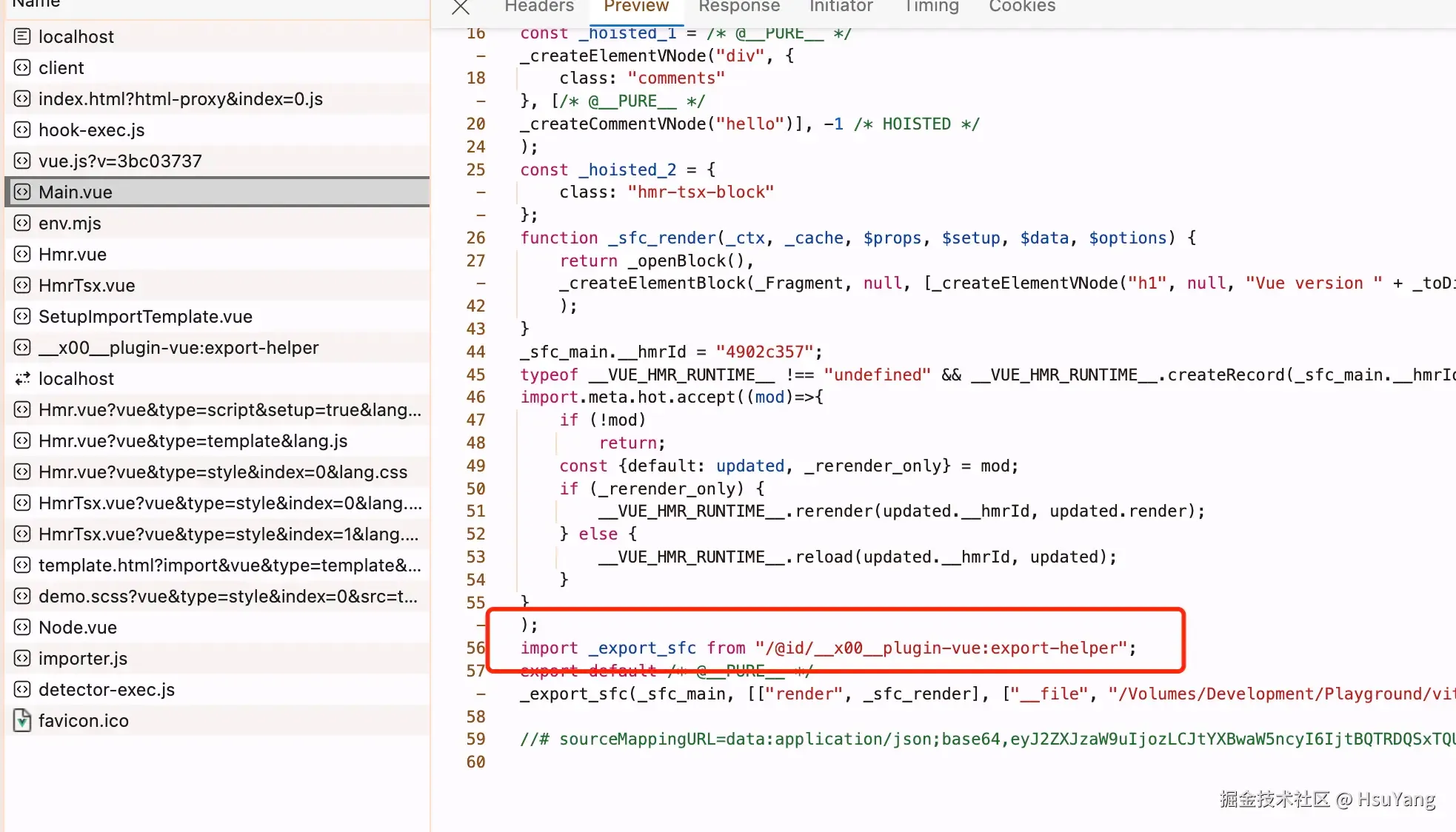 关于这个工具方法的内容,我们在源码里面可以看到:
关于这个工具方法的内容,我们在源码里面可以看到:  其实就是用它可以把script标签里的内容和template编译的内容合并,形成最终的组件。
其实就是用它可以把script标签里的内容和template编译的内容合并,形成最终的组件。
3、加载文件内容
在这儿,先插播题外话,给大家补充一些基础知识,就是平时在开发的过程中,我们实际上并没有留意过在开发过程中,浏览器的请求资源面板的细节,这些请求上实际上是有重要线索的。
加载主文件的请求: 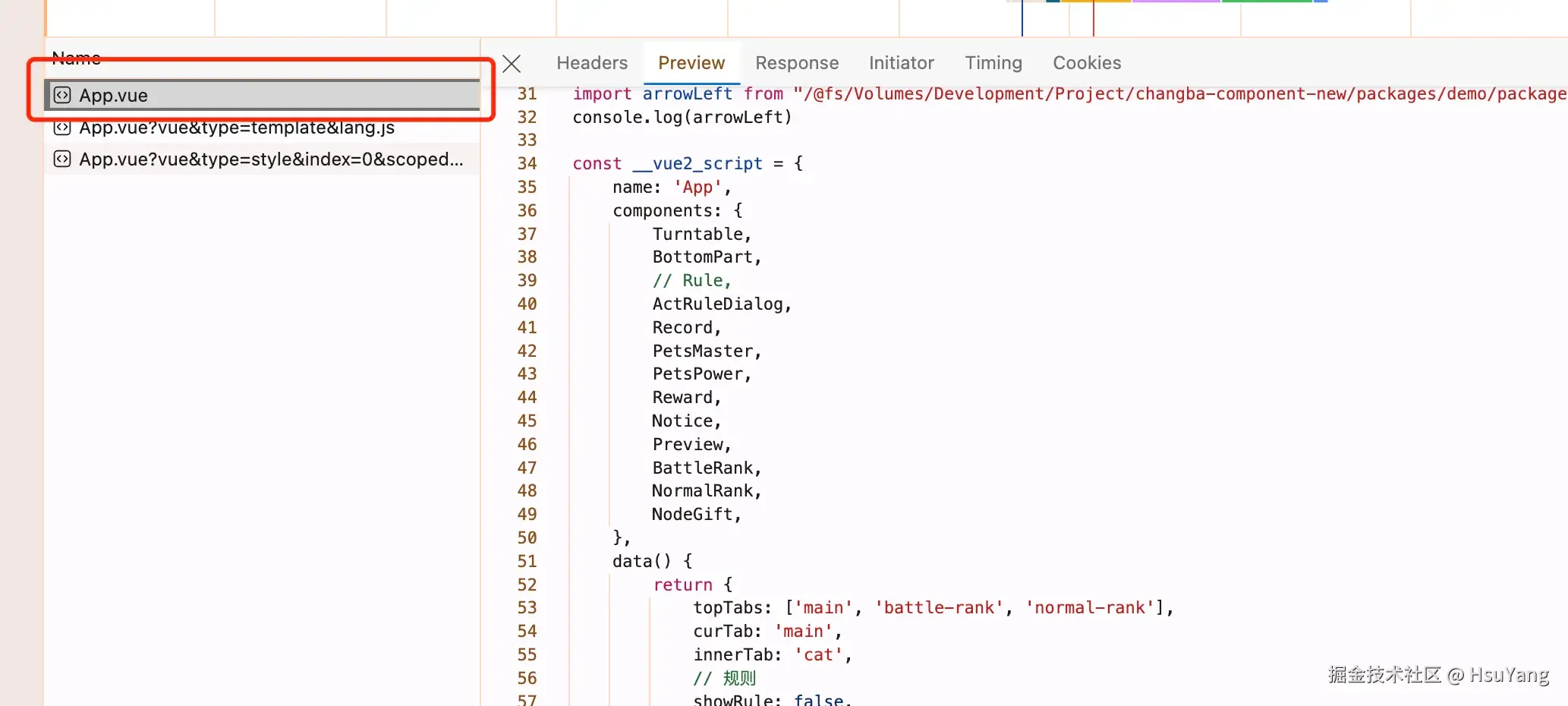 加载template的请求:
加载template的请求: 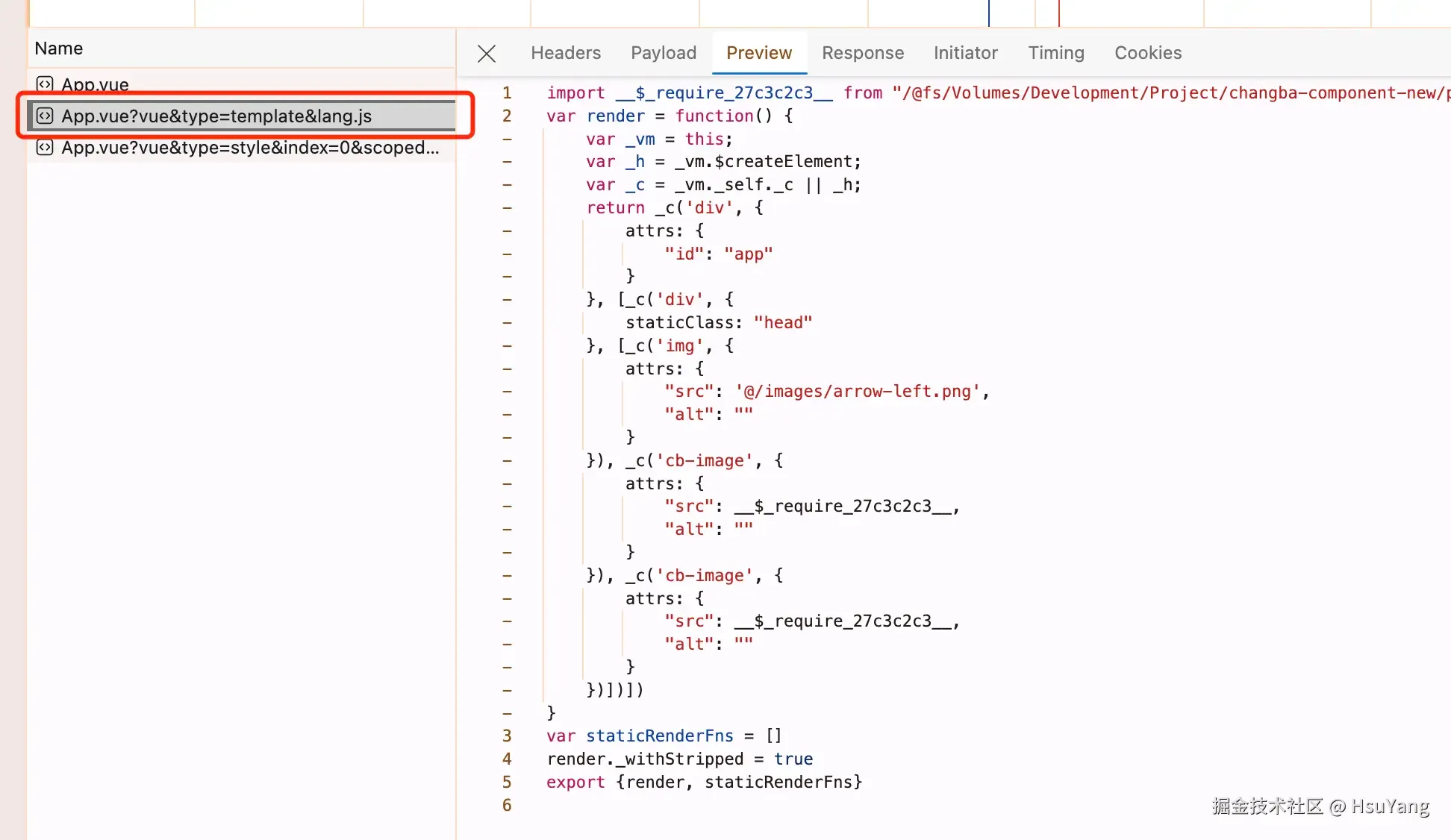 可以看到,请求的结果其实是一个render函数。
可以看到,请求的结果其实是一个render函数。
加载样式的请求: 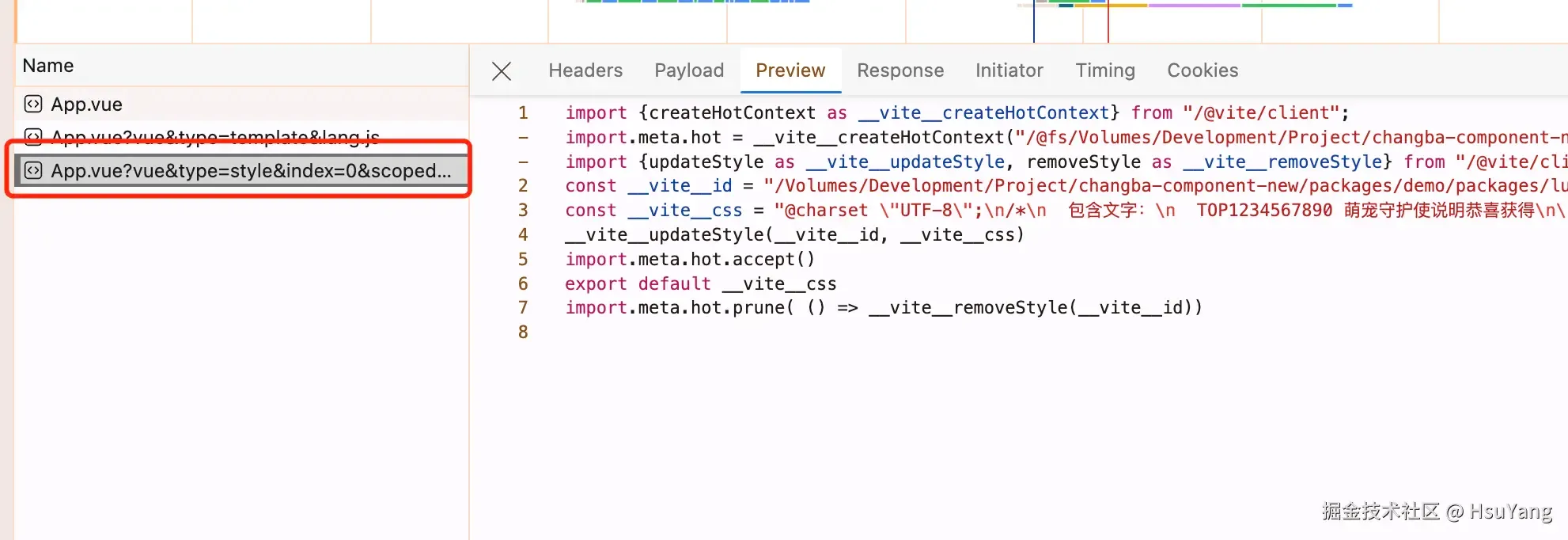 style的样式是在vite提供的客户端的能力里面插入的(Webpack实现不同,如果我没有记错的话,Webpack是利用的
style的样式是在vite提供的客户端的能力里面插入的(Webpack实现不同,如果我没有记错的话,Webpack是利用的StyleLoader完成的插入)
上述代码,我已经把资源地址标红圈起来了,请大家仔细看看里面有什么区别,其实vite-vue-plugin通过把这些请求标记上特定的查询字符串,然后插件就知道浏览器真正需要的是哪部分的内容。(我们实际开发插件的时候,就可以根据这些内容,来挑选我们感兴趣的内容进行转换)
好了,这会儿我们已经知道文件的对应关系了(即Rollup知道怎么去加载文件)。接下来看load生命周期的内容: 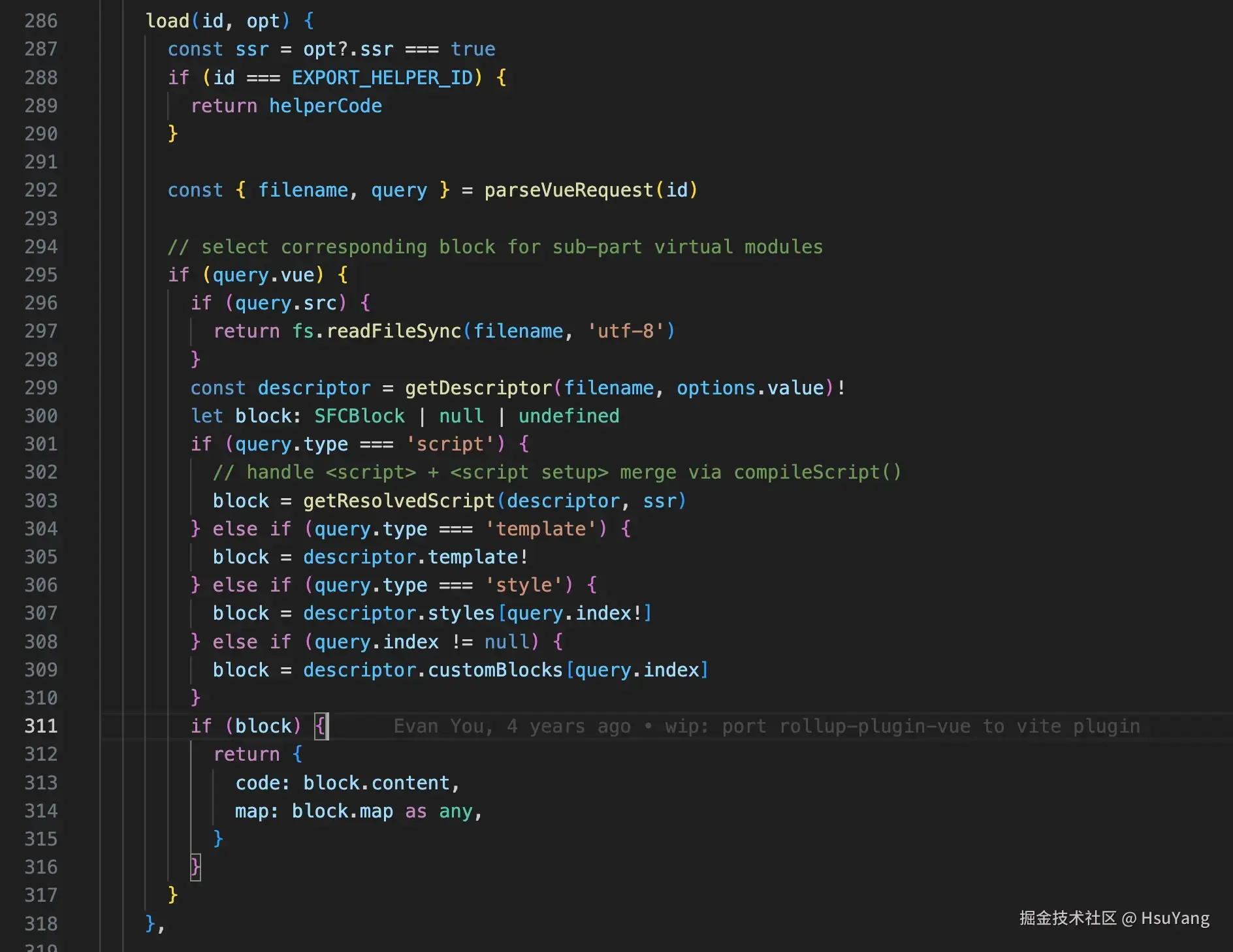 我们除了关心那个虚拟模块的内容以及.vue文件,其它插件肯定是一律不管的。
我们除了关心那个虚拟模块的内容以及.vue文件,其它插件肯定是一律不管的。
我们先来喵一眼这个代码干了什么逻辑,对于vue主文件,这个很简单,直接从磁盘里面读,也很好理解。但是后面的逻辑是什么呢?
因为,我们从vue的主文件编译之后,这个文件就会引入script,引入style这些内容。 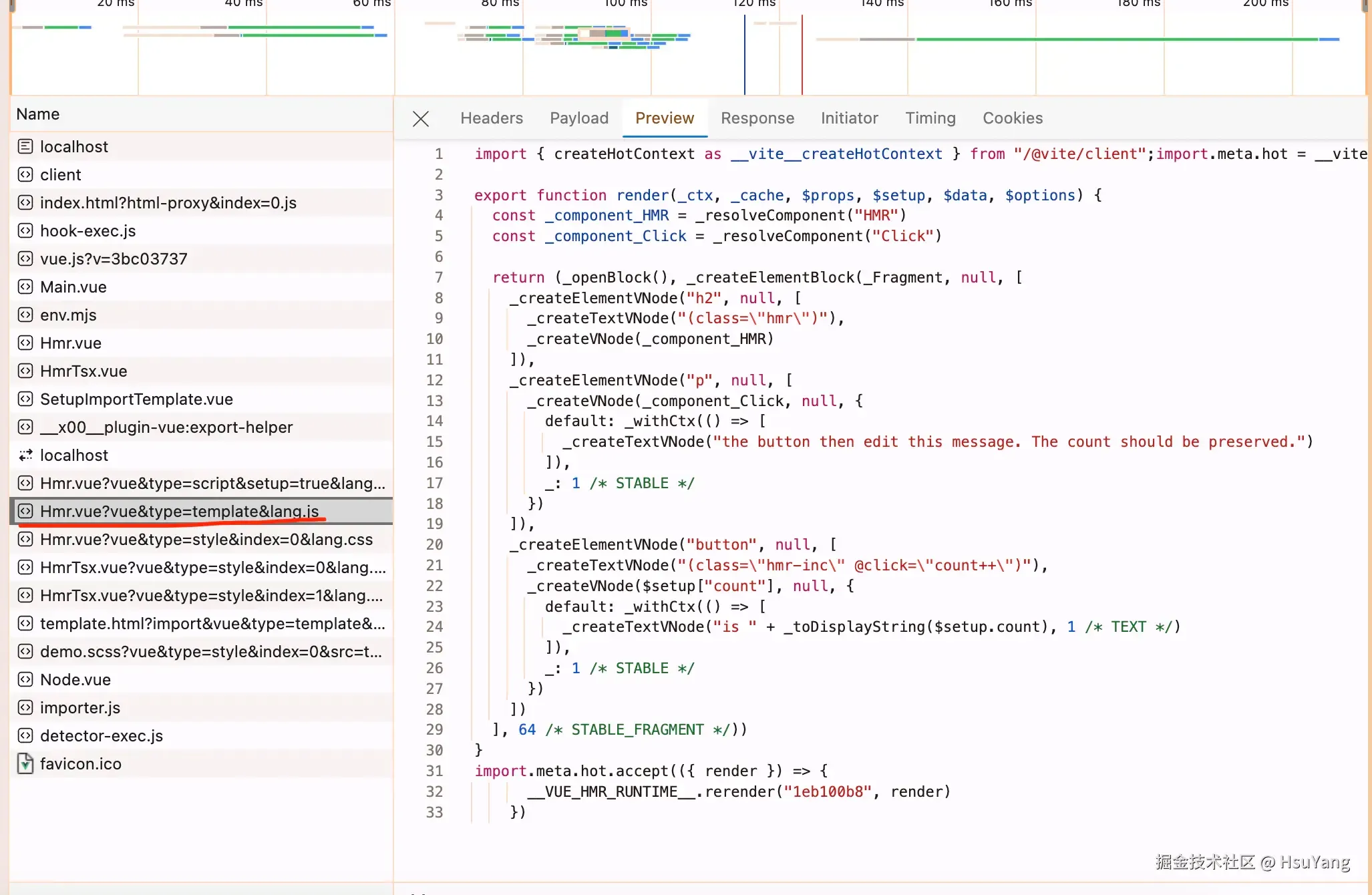
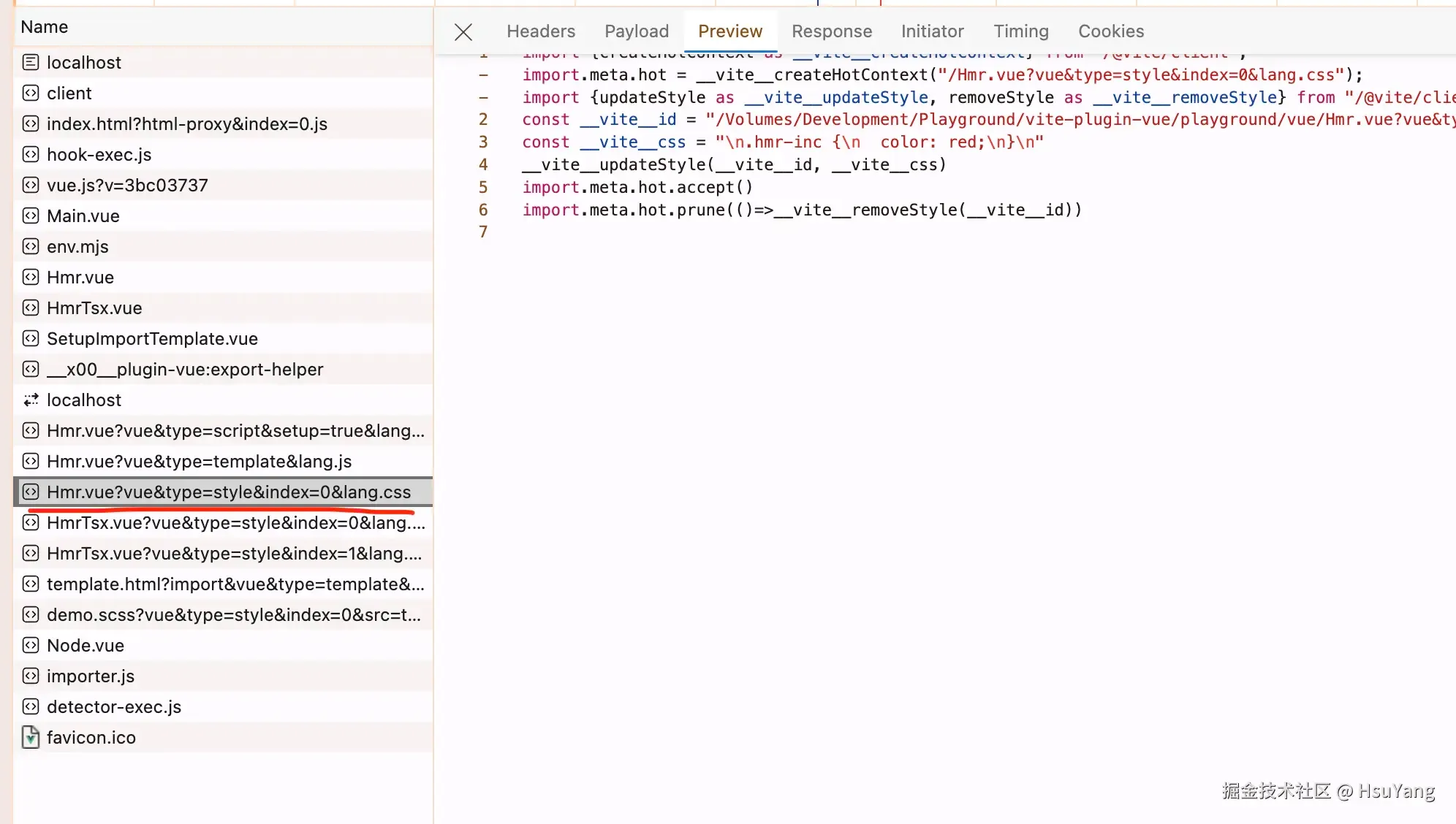 可以看到,对于style,vite是处理了index的,这就意味着我们在单文件组件里面可以编写多个
可以看到,对于style,vite是处理了index的,这就意味着我们在单文件组件里面可以编写多个style标签。
比如这样: 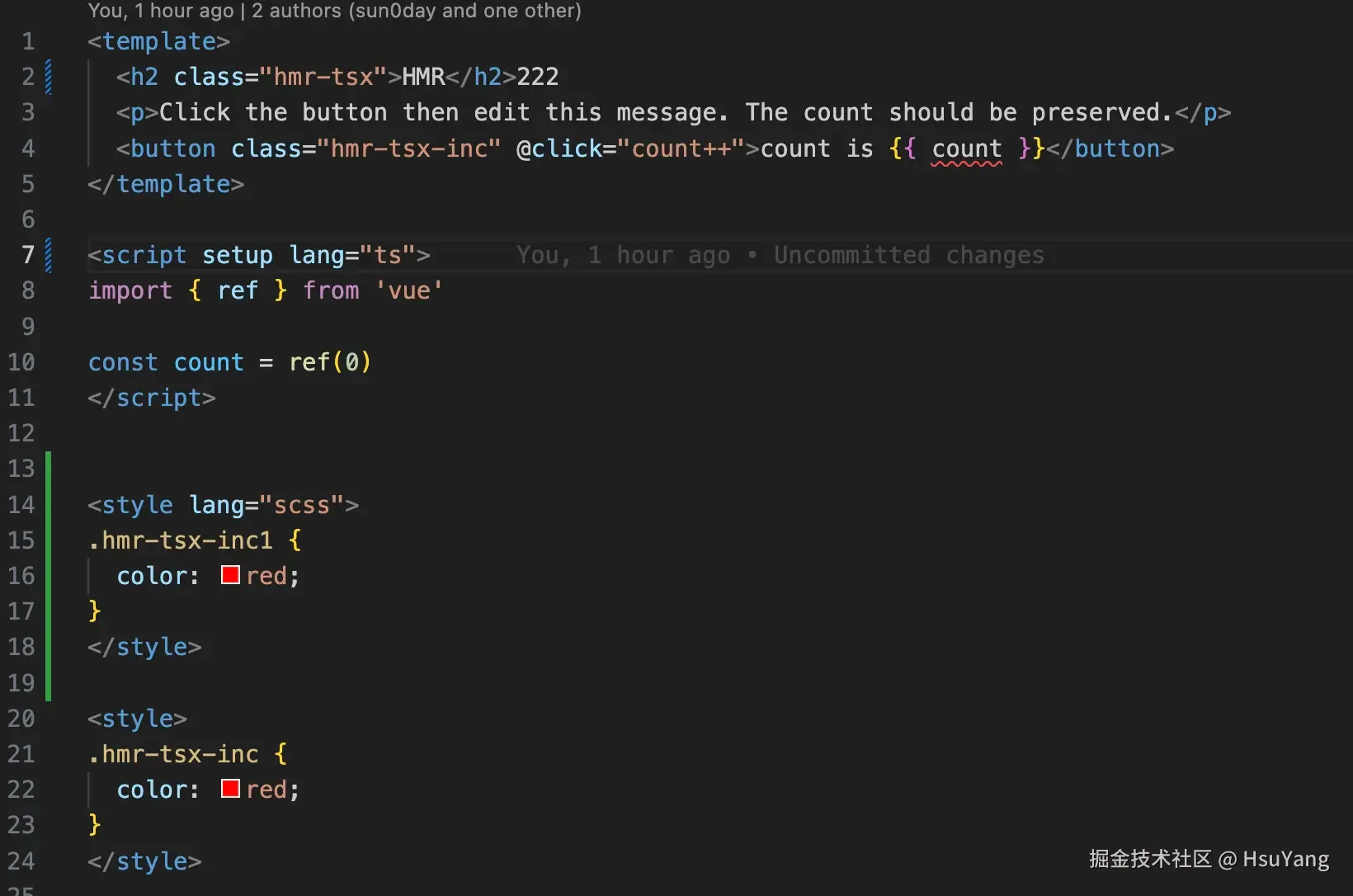 看到这儿,很多同学就会跟我一样发出感叹,妙啊🐱,哈哈哈。
看到这儿,很多同学就会跟我一样发出感叹,妙啊🐱,哈哈哈。
4、编译出浏览器可识别的内容
1{
2 transform(code, id, opt) {
3 const ssr = opt?.ssr === true
4 const { filename, query } = parseVueRequest(id)
5
6 if (query.raw || query.url) {
7 return
8 }
9
10 if (!filter.value(filename) && !query.vue) {
11 return
12 }
13
14 if (!query.vue) {
15
16 return transformMain(
17 code,
18 filename,
19 options.value,
20 this,
21 ssr,
22 customElementFilter.value(filename),
23 )
24 } else {
25
26 const descriptor = query.src
27 ? getSrcDescriptor(filename, query) ||
28 getTempSrcDescriptor(filename, query)
29 : getDescriptor(filename, options.value)!
30
31 if (query.type === 'template') {
32 return transformTemplateAsModule(
33 code,
34 descriptor,
35 options.value,
36 this,
37 ssr,
38 customElementFilter.value(filename),
39 )
40 } else if (query.type === 'style') {
41 return transformStyle(
42 code,
43 descriptor,
44 Number(query.index || 0),
45 options.value,
46 this,
47 filename,
48 )
49 }
50 }
51 },
52}
这个生命周期内完成的事儿比较多,所以截图一屏放不下,所以就给大家贴了一下插件的源码。
对于主文件,即真正的.vue文件,插件调用了一个重量级的编译方法,transformMain。我们接着看一下这个方法做了什么?
(关于热更新部分,本文暂时先不做分析。)
首先是解析script标签内部的内容:
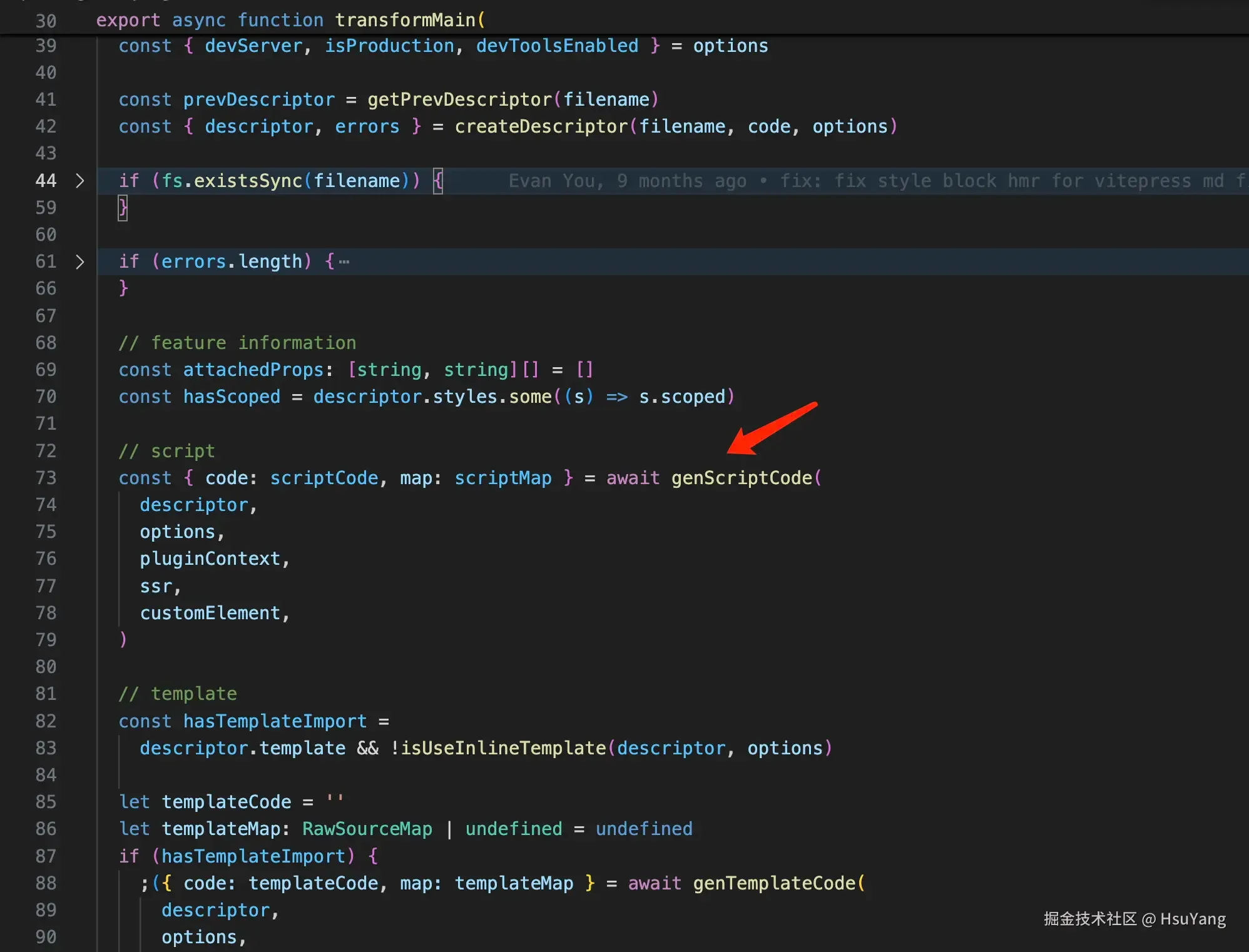 分两种情况,一种是我们直接写的script标签内的代码,一种是通过script标签的src引入的内容。 继续看:
分两种情况,一种是我们直接写的script标签内的代码,一种是通过script标签的src引入的内容。 继续看: 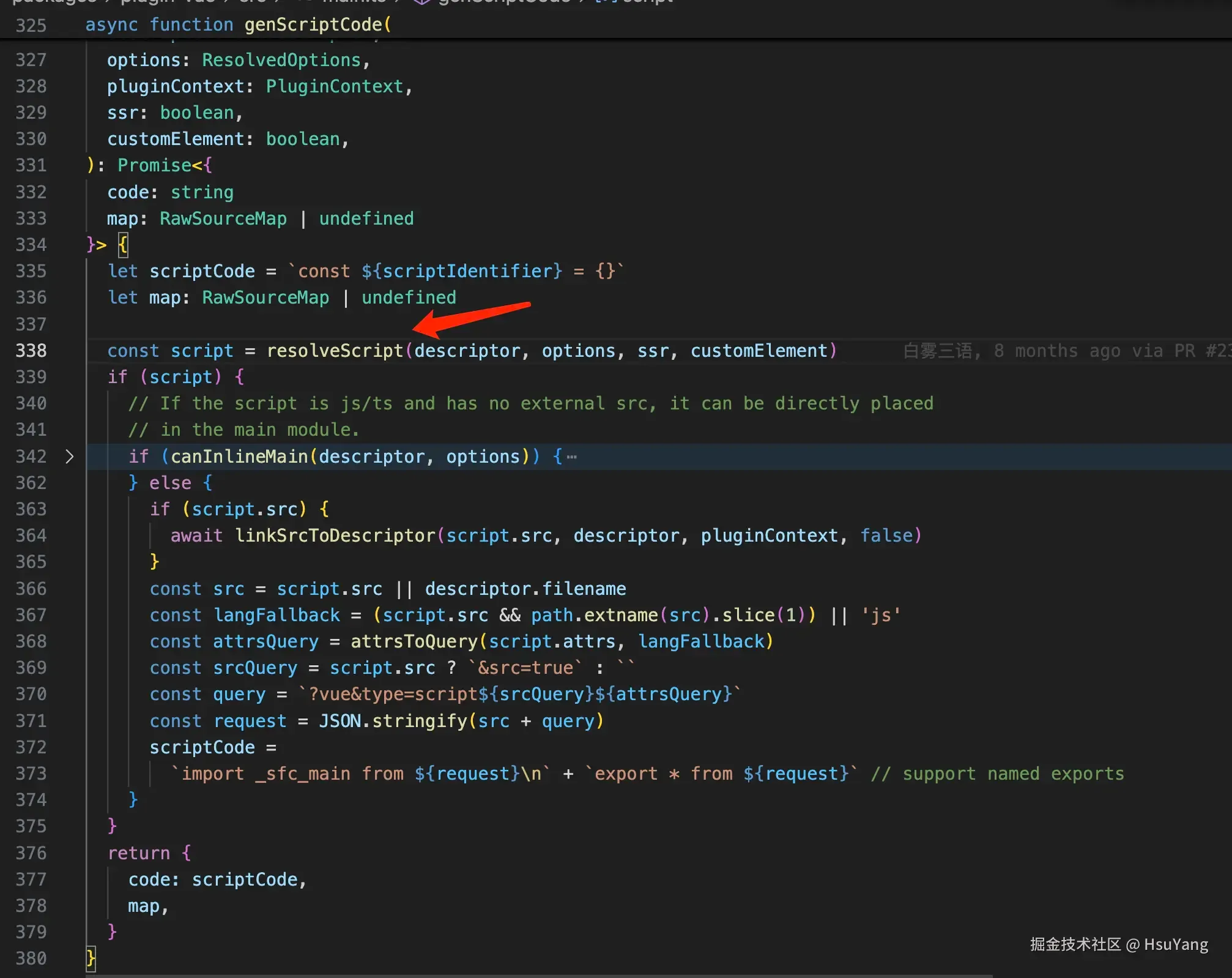
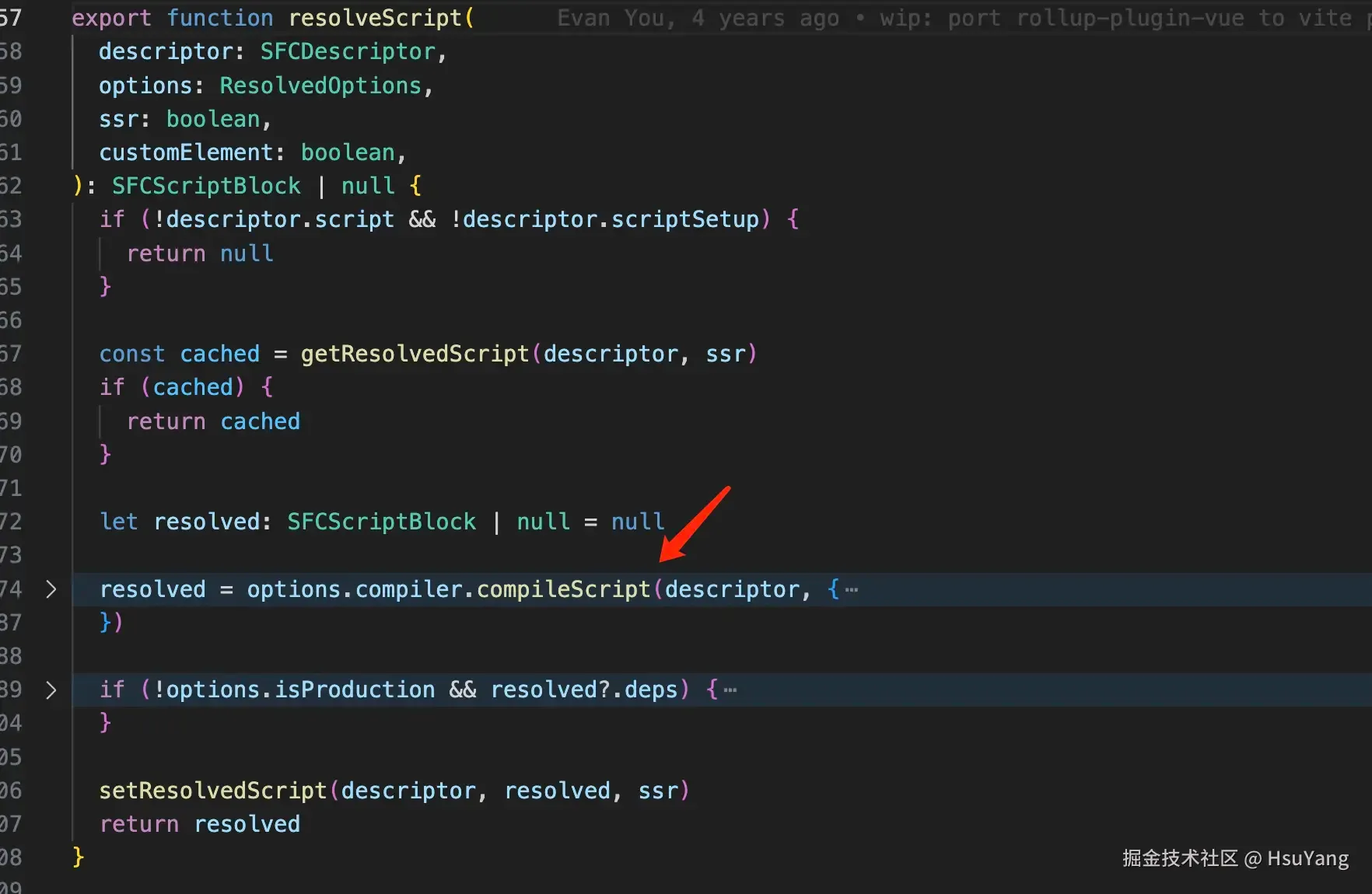 之前我们在最开头挂载的编译器,在这个位置就是真正在干活了。
之前我们在最开头挂载的编译器,在这个位置就是真正在干活了。
接着是编译template的内容: 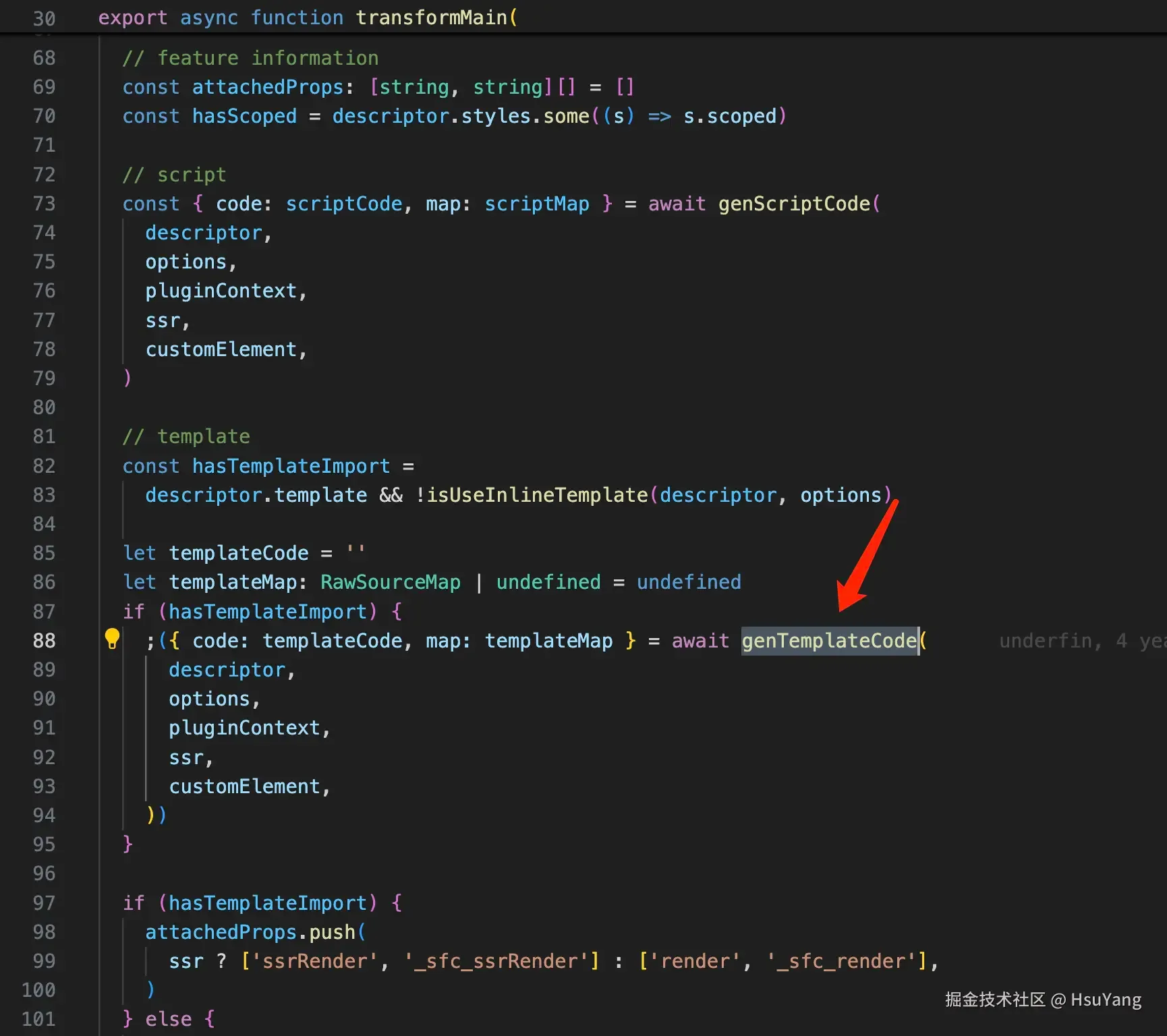 在最后,如果是通过src导入的脚本,会额外处理这个文件(后续浏览器会再次来请求这个虚拟文件)
在最后,如果是通过src导入的脚本,会额外处理这个文件(后续浏览器会再次来请求这个虚拟文件) 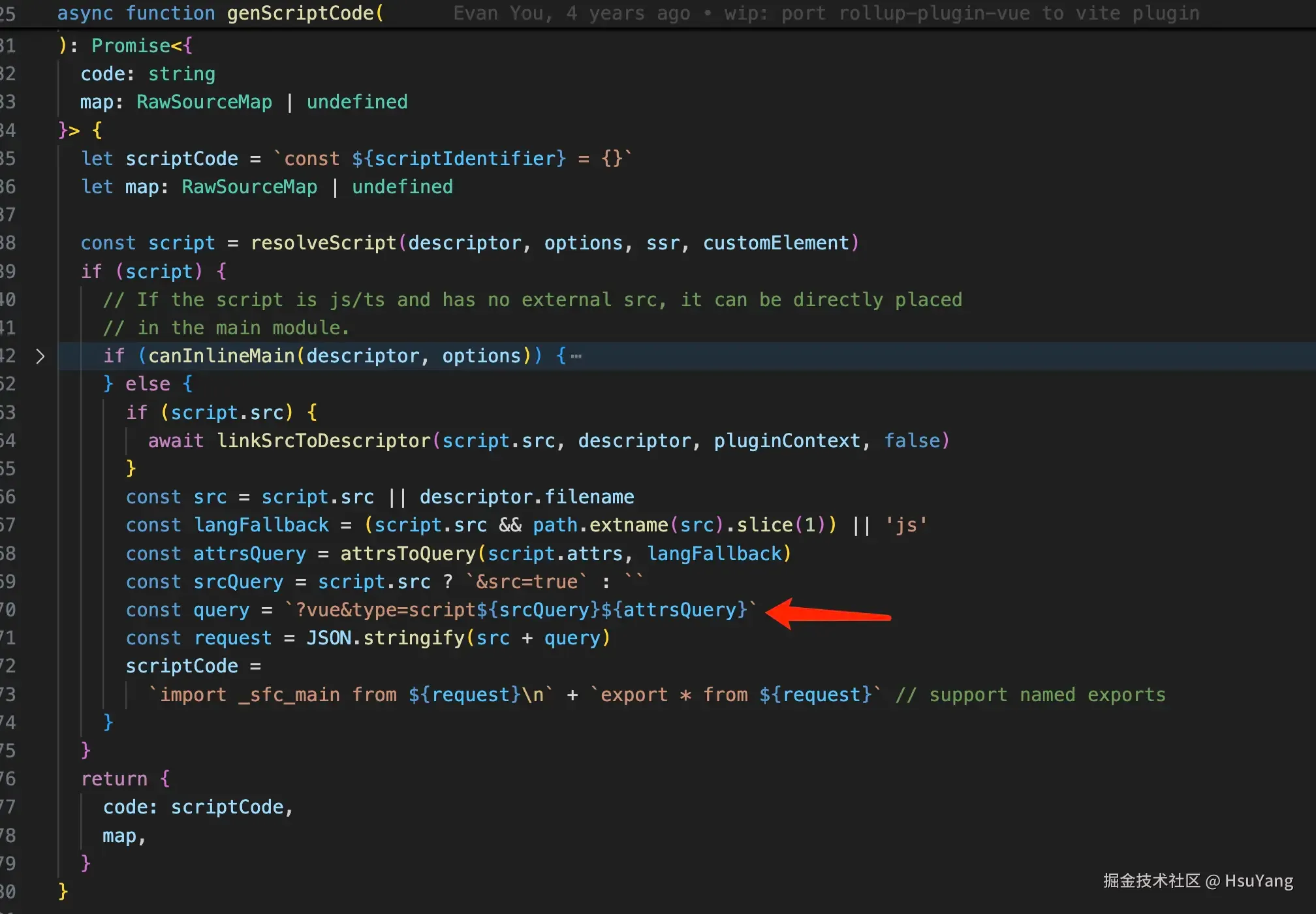
我们拿一个例子来举例: 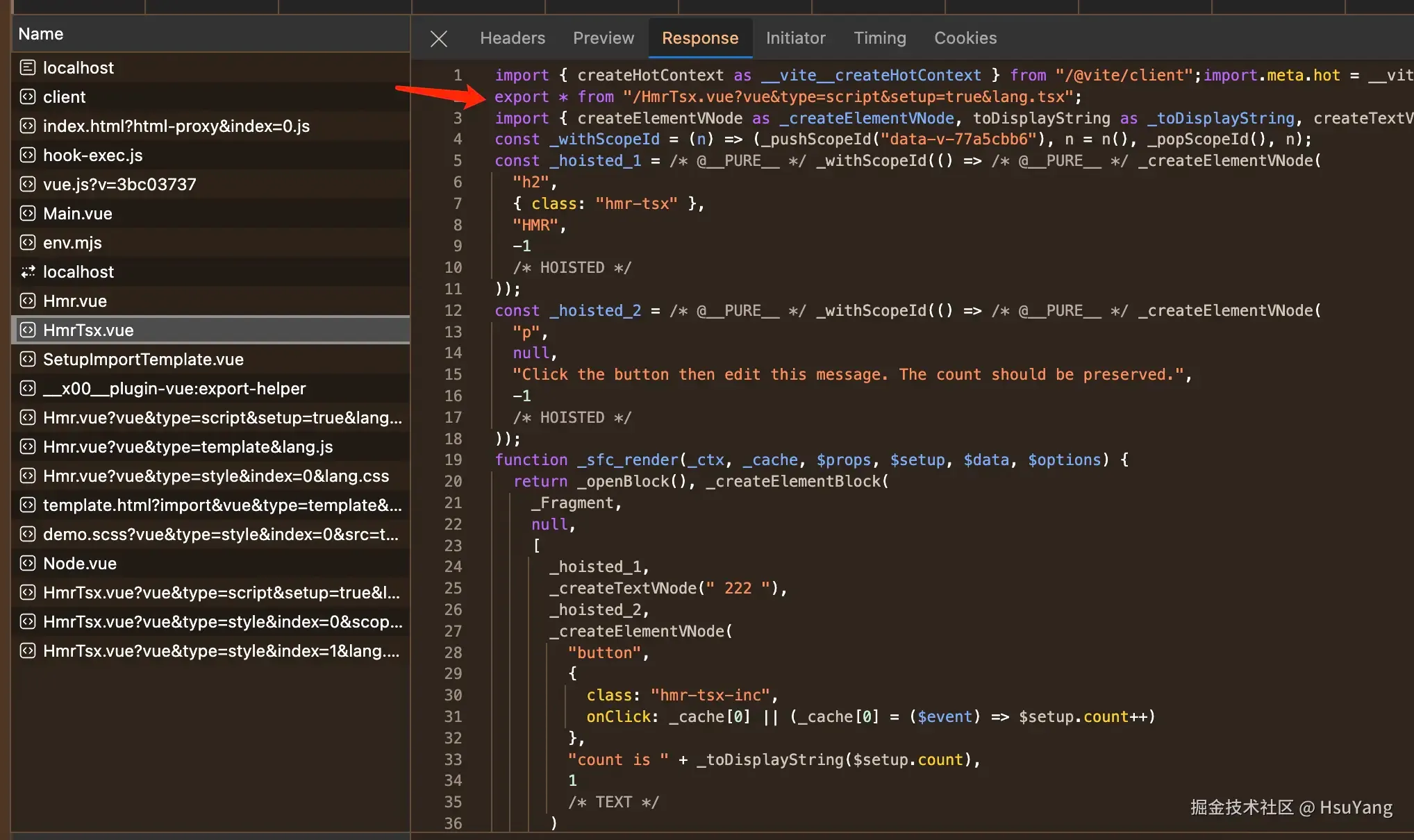 只有J(T)SX才会处理成这样对外导出的形式,如果不是J(T)SX的话,直接是内联的脚本,这个可能是跟热更新的实现有关系。
只有J(T)SX才会处理成这样对外导出的形式,如果不是J(T)SX的话,直接是内联的脚本,这个可能是跟热更新的实现有关系。
template的内容也支持直接编写或者通过src引入的形式。 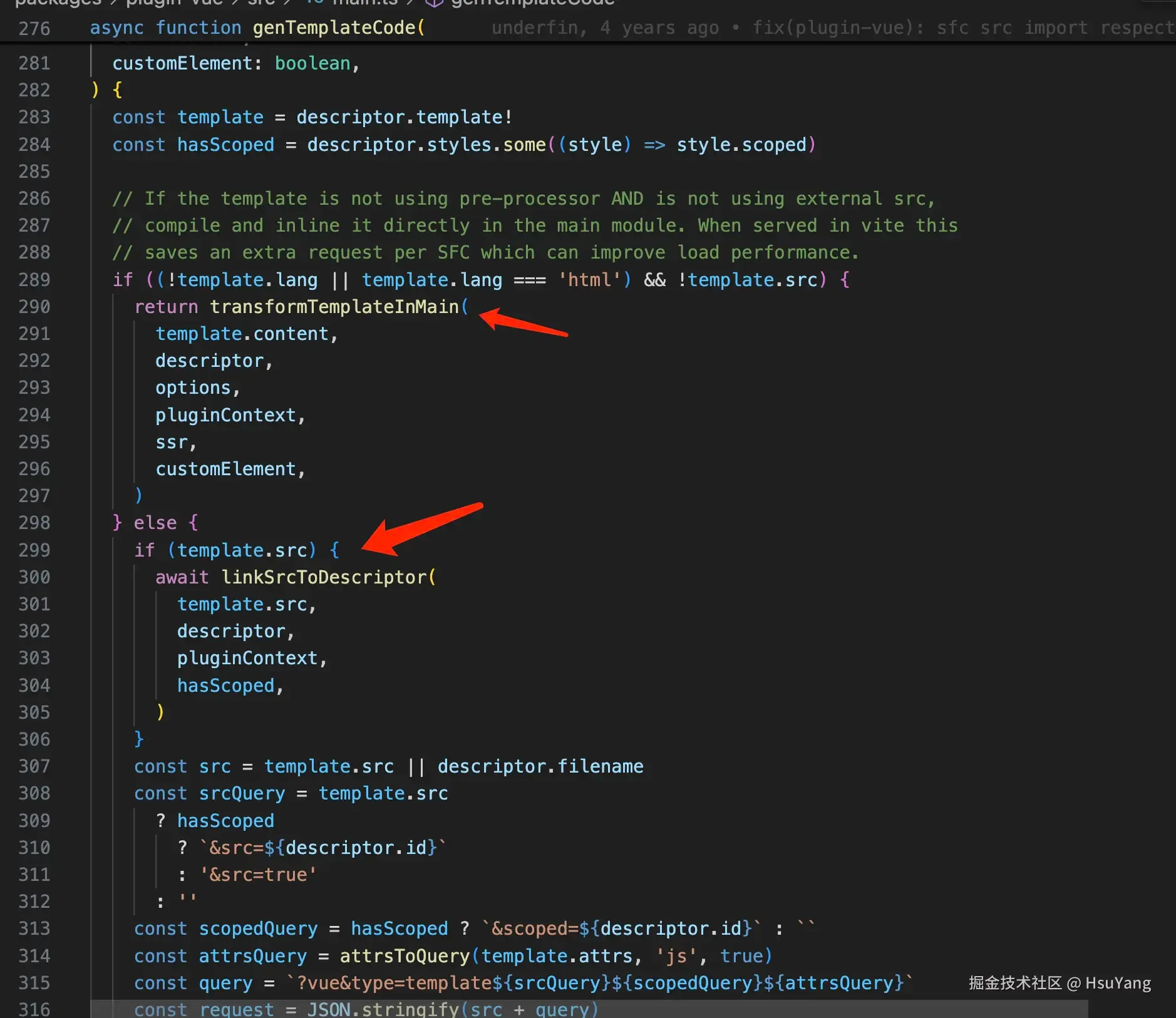 处理的流程跟之前提到的脚本的处理有点儿类似,也会创造出虚拟文件,然后引入,体现在效果上就是浏览器后续再来请求。
处理的流程跟之前提到的脚本的处理有点儿类似,也会创造出虚拟文件,然后引入,体现在效果上就是浏览器后续再来请求。
所以,到这个位置,我们稍微总结一下,在vite-vue-plugin里面,解析到一个.vue文件的时候,首先会尝试编译主文件,即我们写在script标签里面的文件,然后会解析出template中的内容,template的内容会被编译成render函数,并且和主文件的的sript标签中的内容进行拼合,形成一个可执行的Vue组件。这个过程中,同时还需要解析,style标签里面写的样式,从而完成对一个Vue文件的解析。
为什么vite能够让浏览器识别.vue文件呢,是因为vite插件利用了虚拟模块的技术,vite把一个vue的主文件,拆分成多个子文件,比如主script文件,template转成render函数的js文件,样式js文件,这些子文件的路径上被拼接成了预期的查询字符串,vite的插件可以根据感兴趣的内容做相应的处理。
vite-vue-plugin插件利用vite的生命周期,把我们写在script标签内的脚本,编译成浏览器可以识别的ESM规格的脚本,然后把template编译成render函数,和写在script标签的脚本进行合并,得到组件的最终内容。同时在这个过程中,样式文件也被处理成了一个js文件,vite提供了开发环境的浏览器端能力的扩展,使得可以把这些js文件的内容提取出来,生成style标签,插入到浏览器中,然后我们的运行时Vuejs创建前期已经准备好的组件内容,最终完成渲染。
以上内容是我通过阅读vite-vue-plugin项目的源码的解读,由于本人水平有限,撰文过程中可能有纰漏,各位读者若觉得有问题,可以和我联系。
在搞清楚vite插件可以做什么之后,后续的文章我将会向大家介绍如何编写插件来操作代码编译转换的过程,从而更高效的完成自己的业务。