最近碰到一个需求,要实现和微信公众号一样的阅读全文的功能。
然后找到了_window.speechSynthesis_这个API,在翻阅大量资料和网站后,发现在很多资料里,关于这个api的描述都不是很齐全,或是属性值的区间没有描述,或是浏览器的支持情况没有描述。好嘛,我自己总结一个嘛。
概念介绍 window.speechSynthesis
window.speechSynthesis_是_HTML5_推出的_Web API。在支持该API的浏览器环境中执行。它允许网页开发者通过JavaScript代码来访问和控制浏览器的语音合成功能,即将文本转换为语音输出。该API是需要配合同时HTML5推出的_SpeechSynthesisUtterance_(语音合成对象)一期使用的。
window.speechSynthesis 和 SpeechSynthesisUtterance 对于浏览器的支持度
window.speechSynthesis
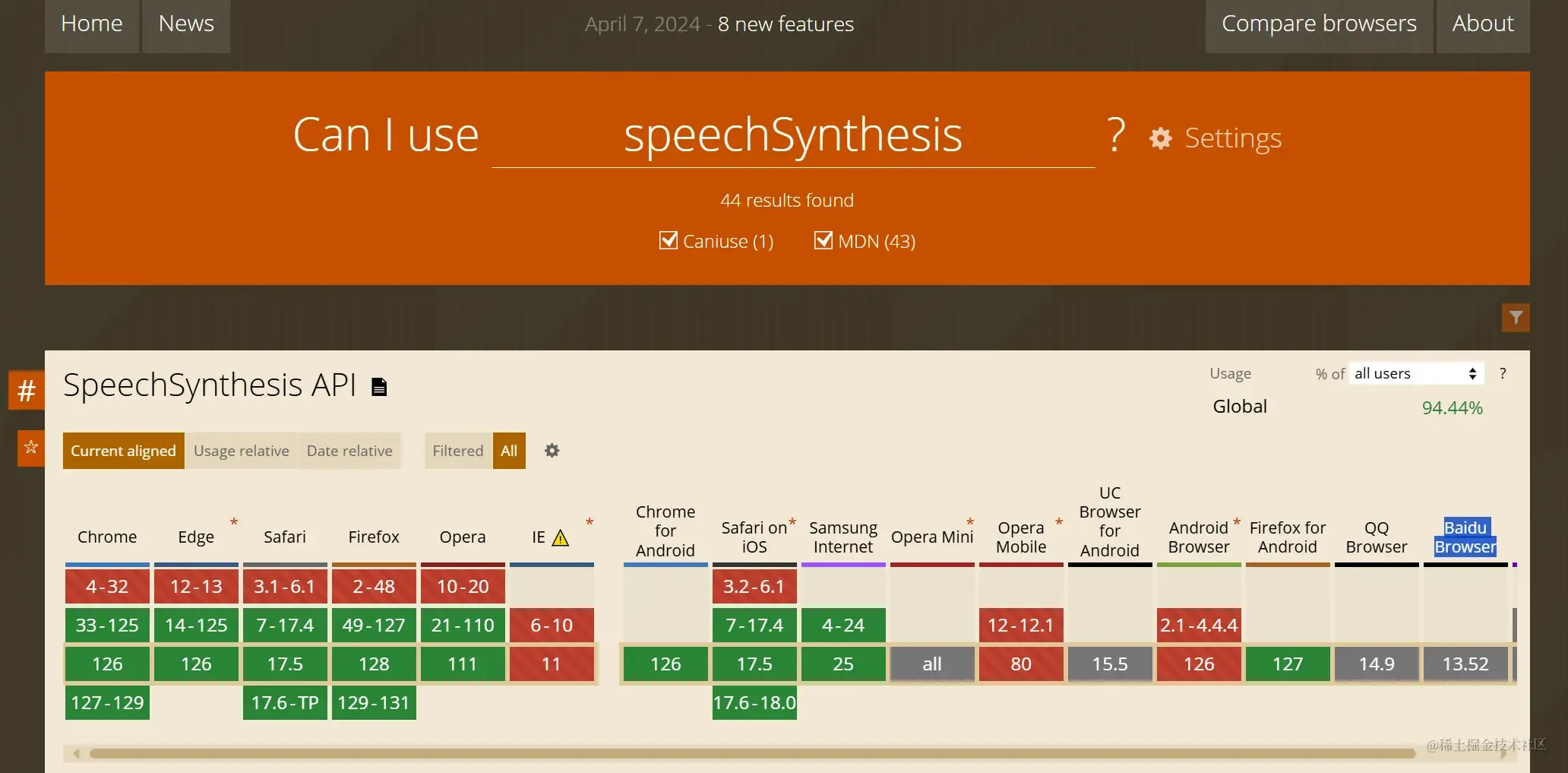
SpeechSynthesisUtterance
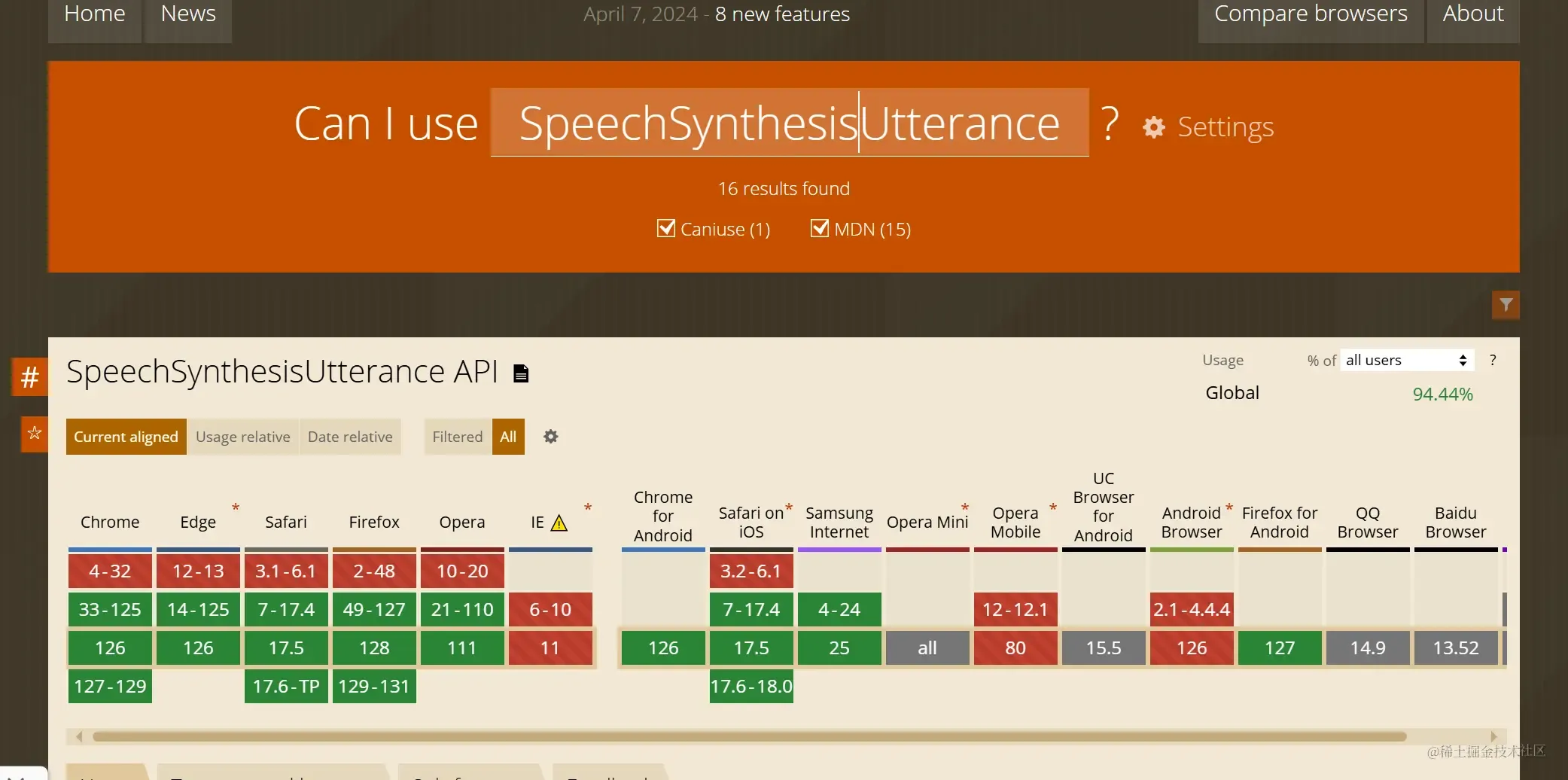
SpeechSynthesisUtterance 的属性和方法
属性
-
text:获取并设置要朗读的文本内容。
-
pitch:获取并设置话语的音调 (0-2) ,值越大音调越尖锐,越低则越低沉。
-
rate:获取并设置说话的速度 (0.1-10),值越大语速越快,越小语速越慢。
-
voice:获取并设置说话的声音。这通常是一个 SpeechSynthesisVoice 对象,表示可用的语音选项。
-
volume:获取并设置说话的音量 (0-1),值越大音量越大。
-
lang:获取并设置话语的语言。这会影响语音合成的发音和语言习惯。(这个取决于浏览器的支持度)
-
en-US:美国英语
-
zh-CN:简体中文(中国大陆)
-
zh-TW:繁体中文(台湾)
-
fr-FR:法国法语
-
de-DE:德国德语
-
es-ES:西班牙西班牙语
-
ja-JP:日本日语
-
方法
onboundary:当播放至一个词或句子结尾时触发的事件处理函数。
onend:语音播放结束时触发的事件处理函数。
onerror:语音播放错误时触发的事件处理函数。
onmark:当语音播放至 mark 标记时触发的事件处理函数(如果文本中包含了 mark 标签)。
onpause:暂停语音播放时触发的事件处理函数。
onresume:恢复语音播放时触发的事件处理函数。
onstart:开始语音播放时触发的事件处理函数。
window.speechSynthesis 的属性和方法
方法
speak(utterance):将指定的 SpeechSynthesisUtterance 对象添加到语音合成队列中,并开始播放(如果队列为空)。
cancel():取消当前正在播放的语音或队列中的所有语音。
pause():暂停当前正在播放的语音。
resume():恢复之前暂停的语音播放。
属性
voices:一个 SpeechSynthesisVoice 对象的数组,表示浏览器支持的语音。你可以查询这个数组来选择最适合你需求的语音。
onvoiceschanged:当支持的语音列表发生变化时触发的事件处理器。
pending:一个布尔值,表示是否有语音正在等待播放。
speaking:一个布尔值,表示当前是否有语音正在播放。
paused:一个布尔值,表示语音播放是否已暂停。
使用当前api需要注意的是
- 建议使用之前先判断当前浏览器是否支持该web api
1const isBrowserSupport = 'speechSynthesis' in window;
- 该API在刷新页面之后,语音播放并不会停止。所以需要在页面页面被卸载或者刷新的时候,手动清理和暂停相关状态和内容
1window.addEventListener('beforeunload', () => {
2
3 window.speechSynthesis?.cancel();
4 });
5
-
lang 属性没有自动翻译功能。如果你的内容是中文,但是设置了“en-US”(美国英语)。他就只能_用美国人说英语的口音给你把中文读出来_。如果需要根据lang来把内容自定义输出该语言,则需要先找第第三方插件把这文字翻译成改语言,然后再使用当前api去播放。 注意哦。要播放哪个国家的语言一定要尽量把lang设置为哪种类型。否则有概率出现无法读出的情况。 比如文本内容是日文,但是播放语言设置为 zh-CN。就会什么声音都播放不出来。
-
window.speechSynthesis 是唯一的。这意味着,如果在播报途中多次请求。是_不会出现语音重叠的情况。但是,多次的触发会等上一段语音结束后排队播放。_
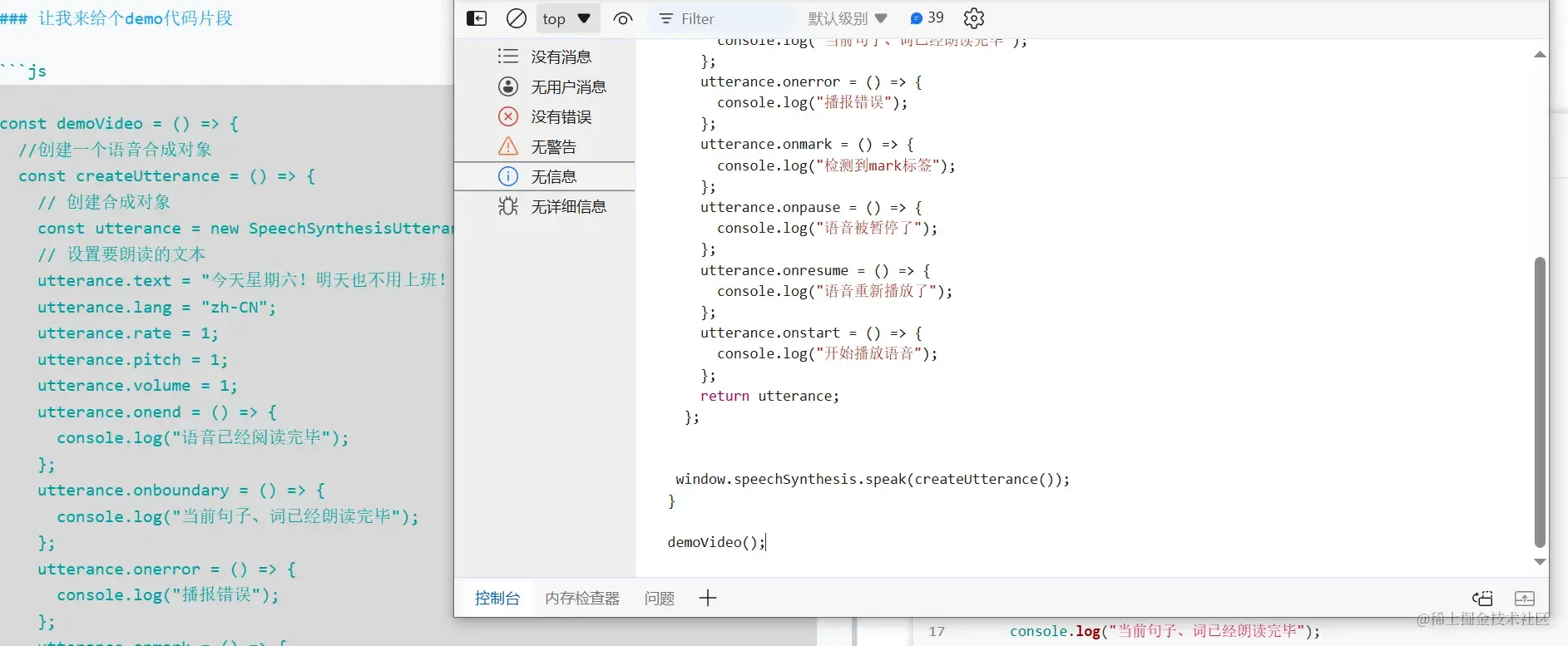
让我来给个demo代码片段
1const demoVideo = () => {
2
3 const createUtterance = () => {
4
5 const utterance = new SpeechSynthesisUtterance();
6
7 utterance.text = "今天星期六!明天也不用上班!";
8 utterance.lang = "zh-CN";
9 utterance.rate = 1;
10 utterance.pitch = 1;
11 utterance.volume = 1;
12 utterance.onend = () => {
13 console.log("语音已经阅读完毕");
14 };
15 utterance.onboundary = () => {
16 console.log("当前句子、词已经朗读完毕");
17 };
18 utterance.onerror = () => {
19 console.log("播报错误");
20 };
21 utterance.onmark = () => {
22 console.log("检测到mark标签");
23 };
24 utterance.onpause = () => {
25 console.log("语音被暂停了");
26 };
27 utterance.onresume = () => {
28 console.log("语音重新播放了");
29 };
30 utterance.onstart = () => {
31 console.log("开始播放语音");
32 };
33 return utterance;
34 };
35
36
37 window.speechSynthesis.speak(createUtterance());
38}
39
40demoVideo();
要测试效果的话,直接打开控制台,直接放在控制台跑一下就行。