❀ 本文讲解使用 JavaScript 读取解析不同文件的实际使用案例展示。展示的内容有:
① JavaScript 读取 DOCX 文档;② JavaScript 解析 CSV 文件内容按照 json 格式输出;
③ JavaScript 解析渲染 PDF 文档;④ JavaScript 提取 PDF 文档的内容;
⑤ JavaScript 提取 PPTX 文件内容案例;
❀ 温馨提示:如果想深入了解每一个JS库,可以看附录中对应的官网或开源地址哈,或许对你很有帮助。
一、解析不同文本的方式
(1)【DOCX】mammoth.js 解析 docx 文本信息
【1】mammoth.js 介绍
Mammoth.js 是一个用于将 Word 文档转换为 HTML 的 JavaScript 库。它特别适合于从 Word 文档中提取内容并以网页格式呈现。以下是一个简单的示例,演示如何使用 Mammoth.js 将 Word 文档转换为 HTML。
【2】使用注意事项和说明
说明
- 文件上传:用户可以通过
<input type="file">上传一个.docx文件。 - 文件读取:使用
FileReaderAPI 读取文件内容。 - Mammoth.js 转换:使用
mammoth.convertToHtml方法将 Word 文档转换为 HTML。 - 结果展示:将转换后的 HTML 插入到网页中的一个
<div>元素中。
注意事项
-
确保你的 Word 文档是
.docx格式。 -
Mammoth.js 主要关注文档的结构和文本内容,可能无法完美保留所有 Word 文档的格式和样式。
【3】完整演示代码
1<!DOCTYPE html>
2<html lang="zh">
3 <head>
4 <meta charset="UTF-8">
5 <meta name="viewport" content="width=device-width, initial-scale=1.0">
6 <title>Mammoth.js 示例</title>
7
8 <script src="https://cdnjs.cloudflare.com/ajax/libs/mammoth/1.4.2/mammoth.browser.min.js"></script>
9 </head>
10 <body>
11 <input type="file" id="upload" accept=".docx"/>
12 <div id="output"></div>
13
14 <script>
15 document.getElementById('upload').addEventListener('change', function(event) {
16 var reader = new FileReader();
17 reader.onload = function(event) {
18 mammoth.convertToHtml({arrayBuffer: event.target.result})
19 .then(displayResult)
20 .catch(handleError);
21 };
22 reader.readAsArrayBuffer(this.files[0]);
23 });
24
25 function displayResult(result) {
26 document.getElementById('output').innerHTML = result.value;
27 console.log(result.messages);
28 }
29
30 function handleError(err) {
31 console.error(err);
32 }
33 </script>
34 </body>
35</html>
测试结果如下:
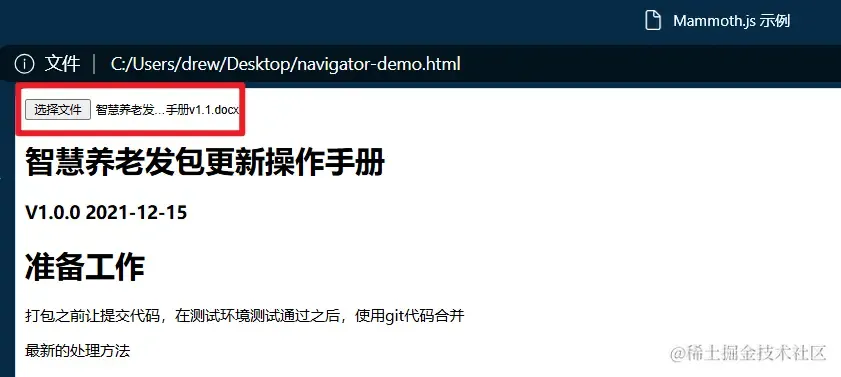
(2)【CSV】Papa Parse 解析 CSV 文件
温馨提示:简单点理解 CSV 文件就是 类似 excel 表格文件数据格式,是高效率数据传输的文本格式。
【1】Papa Parse 简介
Papa Parse 是一个强大的 JavaScript 库,用于解析 CSV(逗号分隔值)文件。它可以在前端轻松地将 CSV 数据转换为 JavaScript 对象。以下是一个简单的示例,展示如何在前端使用 Papa Parse 解析 CSV 文本。
【2】使用注意和说明
1. 说明:
-
文件上传:用户可以通过**** ****
<input type="file">****上传一个.csv文件。 -
Papa Parse 解析:使用
Papa.parse****方法解析上传的 CSV 文件。delimiter: ",":指定分隔符为逗号(可根据需要更改)。header: true: 将第一行视为表头。dynamicTyping: true: 自动将数字和布尔值转换为相应的 JavaScript 类型。skipEmptyLines: true: 跳过空行。transform: 在解析每一行数据时,将每个值转换为小写并去除前后空格。
-
结果展示:将解析后的数据以 JSON 格式插入到网页中的一个
<pre>元素中,便于查看。
2. 注意事项
-
根据 CSV 文件的实际情况,适当配置解析选项。
-
Papa Parse 处理大文件时性能良好,适合用于大数据集的解析。
【3】完整演示代码
准备一份 csv-demo.csv 测试演示文件,输入如下(新建一个 .txt 文件,放入下方数据,再改文件后缀为 .csv 即可,当然,csv文件是可以被office / WPS 软件按照表格的数据格式打开,可别直接将 xlsx文件改为 csv,这样会包含一些xlsx格式存在,而 csv 文件只是高效率的文件传输格式文本类型哈):
1StudentID,Name,Age,Gender,FavoriteCourse
21,Alice,20,Female,Mathematics
32,Bob,22,Male,Computer Science
43,Charlie,21,Male,Physics
54,Diana,20,Female,Biology
65,Evan,23,Male,Chemistry
76,诸葛亮,25,男,历史
注意以下几点:
① 是否支持中文解析,如果不行是否修改文件的编码方式为 UTF-8或者统一编码方式;
② 如果 CSV 文件内容最后多了一空行,会出现什么情况?有点你的自己探索哦;
1<!DOCTYPE html>
2<html lang="zh">
3 <head>
4 <meta charset="UTF-8">
5 <meta name="viewport" content="width=device-width, initial-scale=1.0">
6 <title>Papa Parse 示例</title>
7 <script src="https://cdnjs.cloudflare.com/ajax/libs/PapaParse/5.3.0/papaparse.min.js"></script>
8 </head>
9 <body>
10 <h1>CSV 文件解析示例</h1>
11 <input type="file" id="upload" accept=".csv"/>
12 <p id="output"></p>
13
14
15
16 <script>
17 document.getElementById('upload').addEventListener('change', function(event) {
18 const file = this.files[0];
19 if (file) {
20 Papa.parse(file, {
21 header: true,
22 dynamicTyping: true,
23 complete: function(results) {
24 displayResults(results.data);
25 },
26 error: function(error) {
27 console.error("解析错误:", error);
28 }
29 });
30 }
31 });
32
33 function displayResults(data) {
34
35 document.getElementById('output').textContent = JSON.stringify(data);
36 }
37 </script>
38 </body>
39</html>
测试结果:
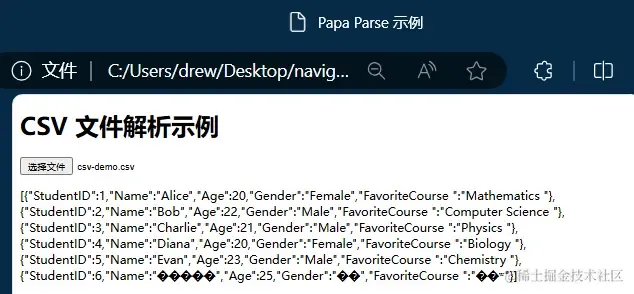
(3)【PDF】PDF.js 解析 PDF 文件
【1】PDF.js 简介
PDF.js 是一个流行的 JavaScript 库,用于在网页中解析和显示 PDF 文件。以下是一个简单的使用案例,展示如何使用 PDF.js 解析和显示 PDF 文件。GitHub - mozilla/pdf.js: PDF Reader in JavaScript
【主要功能】 :
- PDF文件加载:从URL,本地 或者 Blob 对象加载 PDF 文件;
- 页面渲染:将 PDF 渲染成 H5 的 元素,支持高质量的图形输出;
- 文本提取:能够从PDF文件中提取文本内容,支持文本搜索和选择;
- 缩放和旋转:提供页面缩放功能,允许用户调整页面显示大小;支持旋转,一边用户可以查看不同方向的页面;
- 支持多种PDF特性:包括书签、注释、链接、表单等。
- 自定义UI:自定义用户界面,提供灵活的页面导航和控制
- 打印功能: 提供打印 PDF 文件的功能,用户可以直接从浏览器打印当前查看的页面。
- 支持大文件:能够处理大的 PDF文件,支持流式加载,提高性能;
- 多语言支持:支持多语言文本渲染和显示。
【使用场景】:
-
在线文档查看器:可以嵌入在网站中,允许用户直接查看 PDF 文件。
-
电子书阅读器:支持电子书格式的 PDF 文件阅读。
-
表单填充:可以与表单功能结合,支持在线填写和提交 PDF 表单。
-
文档管理系统:在企业或组织中,作为文档管理解决方案的一部分。
【使用步骤】:
- 引入 PDF.js 库:可以直接从 CDN 引入 PDF.js;
- 创建 HTML 代码结构:设置一个显示用于显示读取PDF的 元素;
- 编写 JavaScript 代码:使用 PDF.js 加载和渲染 PDF文件页面(当然PDF.js 可以读取指定页码)。
【2】使用注意和说明
-
确保浏览器支持 File API 和 Canvas。
-
PDF.js 需要在 HTTPS 环境下运行,或者在本地使用时需要使用本地服务器(如 http-server、live-server 等)。
-
可以根据需要调整
scale参数,以改变渲染的页面大小。
【3】完整演示代码
注意:这一部分只是演示 PDF.js 读取 指定的 PDF 页码 显示,如果需要全面显示则需要 获取 PDF 的全部页码 情况,请继续接下来看。
1 <!DOCTYPE html>
2<html lang="zh">
3 <head>
4 <meta charset="UTF-8">
5 <meta name="viewport" content="width=device-width, initial-scale=1.0">
6 <title>PDF.js 示例</title>
7 <script src="https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.10.377/pdf.min.js"></script>
8 <style>
9 #pdf-canvas {
10 border: 1px solid black;
11 width: 100%;
12 height: auto;
13 }
14 </style>
15 </head>
16 <body>
17 <h1>PDF.js 示例</h1>
18 <input type="file" id="file-input" accept="application/pdf" />
19 <canvas id="pdf-canvas"></canvas>
20
21 <script>
22 const fileInput = document.getElementById('file-input');
23 const canvas = document.getElementById('pdf-canvas');
24 const context = canvas.getContext('2d');
25
26 fileInput.addEventListener('change', function(event) {
27 const file = event.target.files[0];
28 if (file) {
29 const fileReader = new FileReader();
30
31 fileReader.onload = function() {
32 const typedArray = new Uint8Array(this.result);
33
34 pdfjsLib.getDocument(typedArray).promise.then(function(pdf) {
35
36 pdf.getPage(1).then(function(page) {
37 const viewport = page.getViewport({ scale: 1.5 });
38 canvas.width = viewport.width;
39 canvas.height = viewport.height;
40
41 const renderContext = {
42 canvasContext: context,
43 viewport: viewport
44 };
45
46 page.render(renderContext);
47 });
48 });
49 };
50
51 fileReader.readAsArrayBuffer(file);
52 }
53 });
54 </script>
55 </body>
56</html>
PDF.js 全部显示 PDF 源码演示
- 全部PDF页面显示注意事项:
-
- 渲染所有的页面可能会消耗较多的内存和处理的时间,所以如果是特别大的PDF需要显示,请尽量使用懒加载模式处理。
- 懒加载模式:通过实现分页和用户滚动滑动的时候一页一页的下载,以提高用户的体验和系统的性能。
- 渲染所有的页面可能会消耗较多的内存和处理的时间,所以如果是特别大的PDF需要显示,请尽量使用懒加载模式处理。
- 全部显示 PK 指定页显示:
- 关键在于获取 PDF 总页码:获取 PDF 的总页数,通过
pdf.numPages。 - 然后使用循环或者懒加载的方式一页一页依次读取输出。
- 关键在于获取 PDF 总页码:获取 PDF 的总页数,通过
1 <!DOCTYPE html>
2<html lang="zh">
3<head>
4 <meta charset="UTF-8">
5 <meta name="viewport" content="width=device-width, initial-scale=1.0">
6 <title>PDF.js 全部页面示例</title>
7 <script src="https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.10.377/pdf.min.js"></script>
8 <style>
9 .pdf-canvas {
10 border: 1px solid black;
11 margin: 10px 0;
12 width: 100%;
13 height: auto;
14 }
15 </style>
16</head>
17<body>
18 <h1>PDF.js 全部页面示例</h1>
19 <input type="file" id="file-input" accept="application/pdf" />
20
21 <div id="pdf-container"></div>
22
23 <script>
24 const fileInput = document.getElementById('file-input');
25 const pdfContainer = document.getElementById('pdf-container');
26
27 fileInput.addEventListener('change', function(event) {
28 const file = event.target.files[0];
29 if (file) {
30 const fileReader = new FileReader();
31
32 fileReader.onload = function() {
33 const typedArray = new Uint8Array(this.result);
34
35 pdfjsLib.getDocument(typedArray).promise.then(function(pdf) {
36 const numPages = pdf.numPages;
37 console.log('总页数:', numPages);
38
39
40 for (let pageNum = 1; pageNum <= numPages; pageNum++) {
41 pdf.getPage(pageNum).then(function(page) {
42 const viewport = page.getViewport({ scale: 1.5 });
43 const canvas = document.createElement('canvas');
44 canvas.className = 'pdf-canvas';
45 pdfContainer.appendChild(canvas);
46 const context = canvas.getContext('2d');
47 canvas.width = viewport.width;
48 canvas.height = viewport.height;
49
50 const renderContext = {
51 canvasContext: context,
52 viewport: viewport
53 };
54
55 page.render(renderContext);
56 });
57 }
58 });
59 };
60
61 fileReader.readAsArrayBuffer(file);
62 }
63 });
64 </script>
65</body>
66</html>
实例演示结果:
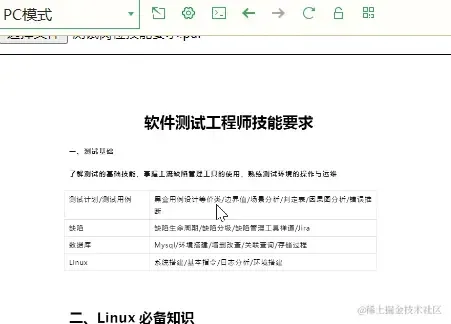
【4】PDF.js 提取 PDF 中的所有文本
(1)说明和注意事项
说明:
- 要使用 PDF.js 提取 PDF 文件中的所有文本信息,可以通过加载 PDF 文件并遍历每一页,使用 getTextContent 方法获取文本内容。
注意事项:
- 提取的文本可能会受到 PDF 文件格式的影响,某些 PDF 文件中的文本可能以图像形式存在,无法提取。
- 如果 PDF 文件包含复杂的布局或多列文本,提取的文本可能不会完全保留原始格式。
- 可以根据需要对提取的文本进行进一步处理,如保存到文件、搜索等。(说到这里,你是不是知道了如何利用 PDF.js 对 PDF 文件中内容进行搜索判断指定目标文本是否存在呢?)
(2)完整代码演示
实现思路:① 引入PDF文件将其转换为 Unit8Array;
② 使用 pdfjslib.getDocument 加载PDF文件;
③ 获取PDF的总页数,如果需要指定页码获取可以自行改动;
④ 对每一面进行调用 getTextContent 方法,提供文本内容,注意是文本内容哈(再次提醒:图像中的内容文本无法提取);
④ 接着就是按照每一页提取的内容进行组合显示再页面上。
1 <!DOCTYPE html>
2<html lang="zh">
3<head>
4 <meta charset="UTF-8">
5 <meta name="viewport" content="width=device-width, initial-scale=1.0">
6 <title>PDF.js 文本提取示例</title>
7 <script src="https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.10.377/pdf.min.js"></script>
8</head>
9<body>
10 <h1>PDF.js 文本提取示例</h1>
11 <input type="file" id="file-input" accept="application/pdf" />
12 <pre id="text-output"></pre>
13
14 <script>
15 const fileInput = document.getElementById('file-input');
16 const textOutput = document.getElementById('text-output');
17
18 fileInput.addEventListener('change', function(event) {
19 const file = event.target.files[0];
20 if (file) {
21 const fileReader = new FileReader();
22
23 fileReader.onload = function() {
24 const typedArray = new Uint8Array(this.result);
25
26 pdfjsLib.getDocument(typedArray).promise.then(function(pdf) {
27 const numPages = pdf.numPages;
28 let allText = '';
29
30
31 const textPromises = [];
32 for (let pageNum = 1; pageNum <= numPages; pageNum++) {
33 textPromises.push(pdf.getPage(pageNum).then(function(page) {
34 return page.getTextContent().then(function(textContent) {
35 let pageText = '';
36 textContent.items.forEach(function(item) {
37 pageText += item.str + ' ';
38 });
39 return pageText;
40 });
41 }));
42 }
43
44
45 Promise.all(textPromises).then(function(pagesText) {
46 allText = pagesText.join('\n\n');
47 textOutput.textContent = allText;
48 });
49 });
50 };
51
52 fileReader.readAsArrayBuffer(file);
53 }
54 });
55 </script>
56</body>
57</html>
测试结果:
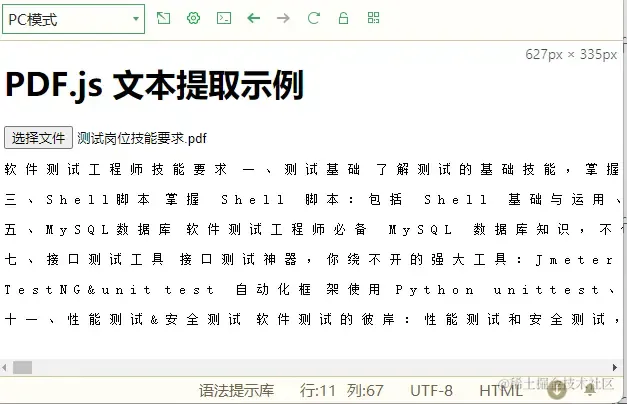
(4)【PPT】解析 PPTX 文件内容
实现思路:利用第三方插件 PptxGenJS 和 Officegen 以及 jszip 来处理 生成 PPT 和读取PPT 文本;
① PptxGenJS ;② Officegen ; ③ jszip;
注意事项:
- 提取文本的内容可能会由于 PPT 里面的内容,如存在 图片化中的文字是不可提取到的。
- 另外,PPT 的文件格式要求为 pptx ,否则无法提取呢;
【1】读取 PPTX 内容
1 <!DOCTYPE html>
2<html lang="zh">
3<head>
4 <meta charset="UTF-8">
5 <meta name="viewport" content="width=device-width, initial-scale=1.0">
6 <title>PPT 内容提取示例</title>
7 <script src="https://cdnjs.cloudflare.com/ajax/libs/jszip/3.10.1/jszip.min.js"></script>
8 <script src="https://cdnjs.cloudflare.com/ajax/libs/officegen/0.4.0/officegen.min.js"></script>
9</head>
10<body>
11 <h1>PPT 内容提取示例</h1>
12 <input type="file" id="file-input" accept=".pptx" />
13 <pre id="text-output"></pre>
14
15 <script>
16 const fileInput = document.getElementById('file-input');
17 const textOutput = document.getElementById('text-output');
18
19 fileInput.addEventListener('change', function(event) {
20 const file = event.target.files[0];
21 if (file) {
22 const fileReader = new FileReader();
23
24 fileReader.onload = function() {
25 const data = new Uint8Array(this.result);
26 const zip = new JSZip();
27
28 zip.loadAsync(data).then(function(zipContent) {
29 let textContent = '';
30
31
32 const promises = [];
33 Object.keys(zipContent.files).forEach(function(filename) {
34 if (filename.endsWith('.xml')) {
35 promises.push(zipContent.files[filename].async('string').then(function(content) {
36
37 const parser = new DOMParser();
38 const xmlDoc = parser.parseFromString(content, 'application/xml');
39 const texts = xmlDoc.getElementsByTagName('a:t');
40 for (let i = 0; i < texts.length; i++) {
41 textContent += texts[i].textContent + '\n';
42 }
43 }));
44 }
45 });
46
47
48 Promise.all(promises).then(function() {
49 textOutput.textContent = textContent;
50 });
51 });
52 };
53
54 fileReader.readAsArrayBuffer(file);
55 }
56 });
57 </script>
58</body>
59</html>
扩展内容:(officegen)
Officegen 功能概述:
-
生成Microsoft PowerPoint 文档(.pptx 文件):
- 创建包含一张或多张幻灯片的 PowerPoint 文档。
- 支持PPT和PPS。
- 可以创建原生图表。
- 添加文本块。
- 添加图像。
- 可以声明字体、对齐方式、颜色和背景。
- 可以旋转对象。
- 支持形状:椭圆、矩形、线条、箭头等。
- 支持隐藏幻灯片。
- 支持日期、时间和当前幻灯片编号等自动字段。
- 支持演讲者笔记。
- 支持幻灯片布局。
-
生成Microsoft Word 文档(.docx 文件):
- 创建Word文档。
- 可以向文档添加一个或多个段落,并且可以设置字体、颜色、对齐方式等。
- 可以添加图像。
- 支持页眉和页脚。
- 支持书签和超链接。
-
生成Microsoft Excel 文档(.xlsx 文件):
- 使用一张或多张工作表创建 Excel 文档。支持带有数字或字符串的单元格。
附录
-
mammoth.js 的其他 CDN:cdnjs.cloudflare.com/ajax/libs/m…
-
mammoth.js 开源地址:github.com/mwilliamson…
-
Papa Parse 解析 CSV 文件框架:www.papaparse.com/
-
PDF.js 开源地址:GitHub - mozilla/pdf.js: PDF Reader in JavaScript
-
officegen NPM 地址文档使用说明:OfficeGen - NPM (npmjs.com)