2023.11.25 - 2024.01.02 更新前端面试问题总结(15道题)
获取更多面试相关问题可以访问
github 地址: https://github.com/pro-collection/interview-question/issues
gitee 地址: https://gitee.com/yanleweb/interview-question/issues
目录:
-
中级开发者相关问题【共计 1 道题】
- 660.请求 Header 的 Content-Type 常见的有哪几种?【热度: 617】【网络】【出题公司: TOP100互联网】
-
高级开发者相关问题【共计 14 道题】
- 644.封装一个请求超时, 发起重试的代码【热度: 789】【代码实现/算法】【出题公司: Shopee】
- 646.css加载会造成阻塞吗【热度: 373】【CSS】【出题公司: TOP100互联网】
- 648.vite 涉及到了哪些底层原理?【热度: 510】【工程化】【出题公司: TOP100互联网】
- 649.vite 编译器的组成部分【热度: 335】【工程化】【出题公司: TOP100互联网】
- 650.vite 编译器有啥特点?【热度: 237】【工程化】【出题公司: TOP100互联网】
- 651.esbuild 和 rollup 都是 vite 的基础依赖, 那么他们有啥不同?【热度: 129】【工程化】【出题公司: TOP100互联网】
- 652.vite 和 webpack 在热更新上有啥区别?【热度: 530】【工程化】【出题公司: 网易】
- 653.需要在跨域请求中携带另外一个域名下的 Cookie 该如何操作?【热度: 254】【网络】【出题公司: Shopee】
- 654.[webpack] webpack-dev-server 作用是啥?【热度: 387】【工程化】【出题公司: PDD】
- 655.[webpack] webpack-dev-server 为何不适用于线上环境?【热度: 88】【工程化】【出题公司: TOP100互联网】
- 656.常见的登录鉴权方式有哪些?【热度: 557】【web应用场景】【出题公司: TOP100互联网】
- 658.单点登录是如何实现的?【热度: 647】【web应用场景】【出题公司: TOP100互联网】
- 659.OAuth2.0 是什么登录方式【热度: 210】【web应用场景】【出题公司: TOP100互联网】
- 661.web 系统里面, 如何对图片进行优化?【热度: 789】【工程化】【出题公司: TOP100互联网】
660.请求 Header 的 Content-Type 常见的有哪几种?【热度: 617】【网络】【出题公司: TOP100互联网】
关键词:请求 header Content-Type、header Content-Type 参数类型
常见的请求Content-Type有以下几种:
-
application/x-www-form-urlencoded:用于URL编码的表单数据,数据以键值对的形式发送。
-
multipart/form-data:用于发送带有文件上传的表单数据,可以包含文本字段和文件字段。
-
application/json:用于发送JSON格式的数据。
-
text/plain:用于发送纯文本数据。
-
application/xml:用于发送XML格式的数据。
-
text/xml:用于发送XML格式的数据,与application/xml类似,但将数据视为纯文本。
-
application/octet-stream:用于发送任意的二进制数据。
这些Content-Type用于指定请求中的主体数据的类型。根据你要发送的数据类型,选择合适的Content-Type。在Fetch API中,你可以通过设置请求头部中的Content-Type字段来指定Content-Type。
追问:application/xml 和 text/xml 有啥区别?
虽然application/xml和text/xml都用于发送XML格式的数据,但它们在处理数据时有一些细微的区别。
application/xml是一种通用的媒体类型,用于表示XML数据。它指示接收方将数据视为XML,并根据XML的语法进行解析和处理。这意味着接收方应该期望接收到的是一个符合XML规范的文档,而不是纯文本。
text/xml是将XML数据表示为纯文本的媒体类型。它指示接收方将数据视为普通文本,并将其视为XML文档进行解析和处理。这意味着接收方会将接收到的数据解析为XML,并进行相应的处理。
因此,主要区别在于接收方对待数据的方式。application/xml更加严格,要求数据符合XML规范,而text/xml则更灵活,将数据视为普通文本进行处理。
644.封装一个请求超时, 发起重试的代码【热度: 789】【代码实现/算法】【出题公司: Shopee】
关键词:请求重试
看过很多请求超时重试的样例, 很多都是基于 axios interceptors 实现的。 但是有没有牛逼的原生方式实现呢?
最近在看 fbjs 库里面的代码, 发现里面有一个超时重试的代码, 只有一百多行代码, 封装的极其牛逼。
不过这里的代码是 Flow 类型检测的代码, 而且有一些外部小依赖, 之后要翻译成 ts 代码。
这里简单介绍一下 fbjs 这个库
fbjs(Facebook JavaScript)是一个由 Facebook 开发和维护的 JavaScript 工具库。它提供了一组通用的 JavaScript 功能和实用工具,用于辅助开发大型、高性能的 JavaScript 应用程序。
说到这儿了, 直接上完整代码
1interface InitWithRetries extends RequestInit {
2 fetchTimeout?: number | null;
3 retryDelays?: number[] | null;
4}
5
6const DEFAULT_TIMEOUT = 1000 * 1.5;
7const DEFAULT_RETRIES = [0, 0];
8
9const fetchWithRetries = (url: string, initWithRetries?: InitWithRetries): Promise<any> => {
10 // fetchTimeout 请求超时时间
11 // 请求
12 const { fetchTimeout, retryDelays, ...init } = initWithRetries || {};
13
14 // 超时时间
15 const _fetchTimeout = fetchTimeout != null ? fetchTimeout : DEFAULT_TIMEOUT;
16
17 // 重复时间数组
18 const _retryDelays = retryDelays != null ? retryDelays : DEFAULT_RETRIES;
19
20 // 开始时间
21 let requestStartTime = 0;
22
23 // 重试请求索引
24 let requestsAttempted = 0;
25
26 return new Promise((resolve, reject) => {
27 // 申明发送请求方法
28 const sendTimedRequest = (): void => {
29 // 自增索引与请求次数
30 requestsAttempted++;
31
32 // 发起请求时间
33 requestStartTime = Date.now();
34
35 // 是否需要处理后续请求
36 let isRequestAlive = true;
37
38 // 发起请求
39 const request = fetch(url, init);
40
41 // 请求超时情况
42 const requestTimeout = setTimeout(() => {
43 // 需要阻断正常的请求返回
44 isRequestAlive = false;
45
46 // 需要重新发起请求
47 if (shouldRetry(requestsAttempted)) {
48 console.warn("fetchWithRetries: HTTP timeout, retrying.");
49 retryRequest();
50 } else {
51 reject(new Error(
52 `fetchWithRetries(): Failed to get response from server, tried ${requestsAttempted} times.`,
53 ));
54 }
55 }, _fetchTimeout);
56
57 // 正常请求发起
58 request.then(response => {
59 // 正常请求返回的场景, 清空定时器
60 clearTimeout(requestTimeout);
61
62 // 如果进入了超时流程, 那么正常返回的逻辑, 就直接阻断
63 if (isRequestAlive) {
64 if (response.status >= 200 && response.status < 300) {
65 resolve(response);
66 } else if (shouldRetry(requestsAttempted)) {
67 console.warn("fetchWithRetries: HTTP error, retrying.");
68 retryRequest();
69 } else {
70 const error: any = new Error(`response error.`);
71 error.response = response;
72 reject(error);
73 }
74 }
75 }).catch(error => {
76 clearTimeout(requestTimeout);
77 if (shouldRetry(requestsAttempted)) {
78 retryRequest();
79 } else {
80 reject(error);
81 }
82 });
83 };
84
85 // 发起重复请求
86 const retryRequest = (): void => {
87 // 重复请求 delay 时间
88 const retryDelay = _retryDelays[requestsAttempted - 1];
89
90 // 重复请求开始时间
91 const retryStartTime = requestStartTime + retryDelay;
92
93 // 延迟时间
94 const timeout = retryStartTime - Date.now() > 0 ? retryStartTime - Date.now() : 0;
95
96 // 重复请求
97 setTimeout(sendTimedRequest, timeout);
98 };
99
100 // 是否可以发起重复请求
101 const shouldRetry = (attempt: number): boolean => attempt <= _retryDelays.length;
102
103 sendTimedRequest();
104 });
105};
106
107fetchWithRetries("http://127.0.0.1:3000/user/")646.css加载会造成阻塞吗【热度: 373】【CSS】【出题公司: TOP100互联网】
关键词:css 加载阻塞渲染
js执行会阻塞DOM树的解析和渲染,那么css加载会阻塞DOM树的解析和渲染吗?
为了完成本次测试,先来科普一下,如何利用chrome来设置下载速度
打开chrome控制台(按下F12),可以看到下图,重点在我画红圈的地方
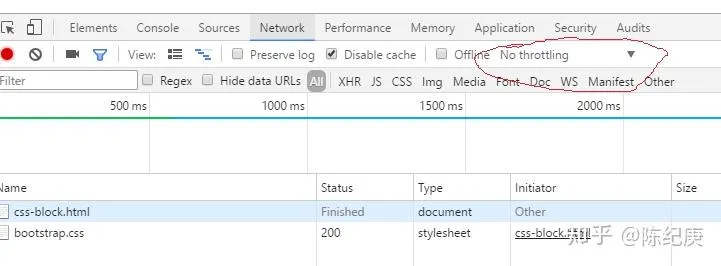
-
点击我画红圈的地方(No throttling),会看到下图,我们选择GPRS这个选项
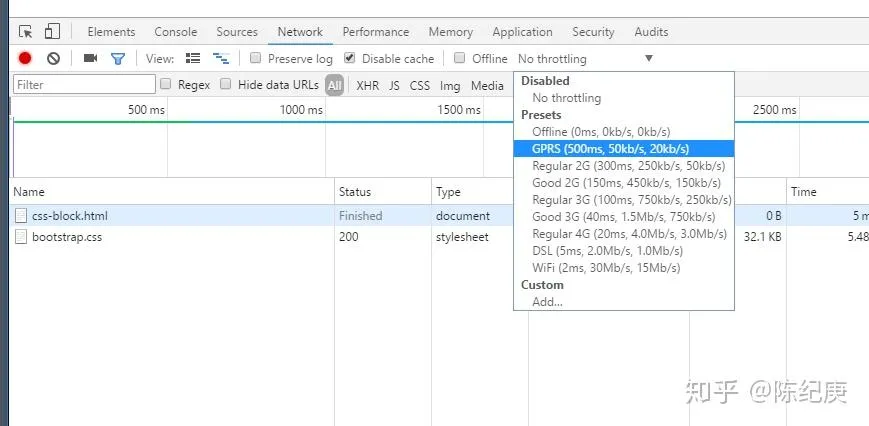
-
这样,我们对资源的下载速度上限就会被限制成20kb/s,好,那接下来就进入我们的正题
1<!DOCTYPE html>
2<html lang="en">
3<head>
4 <title>css阻塞</title>
5 <meta charset="UTF-8">
6 <meta name="viewport" content="width=device-width, initial-scale=1">
7 <style>
8 h1 {
9 color: red !important
10 }
11 </style>
12 <script>
13 function h() {
14 console.log(document.querySelectorAll('h1'))
15 }
16
17 setTimeout(h, 0)
18 </script>
19 <link href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css" rel="stylesheet">
20</head>
21<body>
22<h1>这是红色的</h1>
23</body>
24</html>假设: css加载会阻塞DOM树解析和渲染
假设下的结果: 在bootstrap.css还没加载完之前,下面的内容不会被解析渲染。那么我们一开始看到的应该是白屏,h1不会显示出来。 并且此时console.log的结果应该是一个空数组。
实际结果:如下图
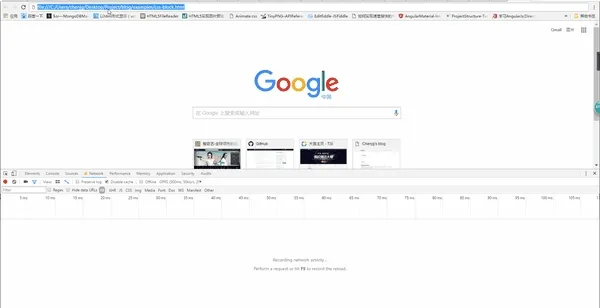
由上图我们可以看到,当bootstrap.css还没加载完成的时候,h1并没有显示,但是此时控制台输出如下

可以得知,此时DOM树至少已经解析完成到了h1那里,而此时css还没加载完成,也就说明,css并不会阻塞DOM树的解析。
由上图,我们也可以看到,当css还没加载出来的时候,页面显示白屏,直到css加载完成之后,红色字体才显示出来,也就是说, 下面的内容虽然解析了,但是并没有被渲染出来。所以,css加载会阻塞DOM树渲染。
其实我觉得,这可能也是浏览器的一种优化机制。因为你加载css的时候, 可能会修改下面DOM节点的样式,如果css加载不阻塞DOM树渲染的话,那么当css加载完之后, DOM树可能又得重新重绘或者回流了,这就造成了一些没有必要的损耗。所以干脆就先把DOM树的结构先解析完,把可以做的工作做完, 然后等你css加载完之后,在根据最终的样式来渲染DOM树,这种做法性能方面确实会比较好一点。
由上面的推论,我们可以得出,css加载不会阻塞DOM树解析,但是会阻塞DOM树渲染。那么,css加载会不会阻塞js执行呢?
1<!DOCTYPE html>
2<html lang="en">
3<head>
4 <title>css阻塞</title>
5 <meta charset="UTF-8">
6 <meta name="viewport" content="width=device-width, initial-scale=1">
7 <script>
8 console.log('before css')
9 var startDate = new Date()
10 </script>
11 <link href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css" rel="stylesheet">
12</head>
13<body>
14<h1>这是红色的</h1>
15<script>
16 var endDate = new Date()
17 console.log('after css')
18 console.log('经过了' + (endDate - startDate) + 'ms')
19</script>
20</body>
21</html>假设: css加载会阻塞后面的js运行
预期结果: 在link后面的js代码,应该要在css加载完成后才会运行
实际结果:
由上图我们可以看出,位于css加载语句前的那个js代码先执行了, 但是位于css加载语句后面的代码迟迟没有执行,直到css加载完成后,它才执行。 这也就说明了,css加载会阻塞后面的js语句的执行。详细结果看下图( css加载用了5600+ms):
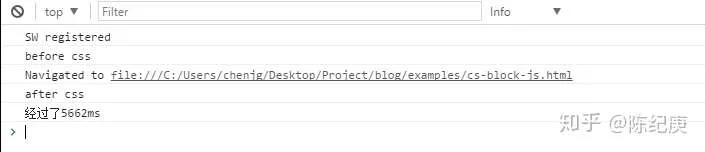
由上所述,我们可以得出以下结论:
- css加载不会阻塞DOM树的解析
- css加载会阻塞DOM树的渲染
- css加载会阻塞后面js语句的执行
因此,为了避免让用户看到长时间的白屏时间,我们应该尽可能的提高css加载速度,比如可以使用以下几种方法:
- 使用CDN(因为CDN会根据你的网络状况,替你挑选最近的一个具有缓存内容的节点为你提供资源,因此可以减少加载时间)
- 对css进行压缩(可以用很多打包工具,比如webpack,gulp等,也可以通过开启gzip压缩)
- 合理的使用缓存(设置cache-control,expires,以及E-tag都是不错的,不过要注意一个问题,就是文件更新后,你要避免缓存而带来的影响。其中一个解决防范是在文件名字后面加一个版本号)
- 减少http请求数,将多个css文件合并,或者是干脆直接写成内联样式(内联样式的一个缺点就是不能缓存)
浏览器渲染是合并dom和cssom的过程,和js完全不一样。 浏览器实现是,尽量等待dom和cssom解析完成,再开始合并渲染。 如果dom解析完成但是css文件超时,或者css太慢,浏览器也会先渲染dom,等css下载完成再另一次渲染。 而为什么会阻塞js,大部分原因都是因为js一般是在页面load完成之后才执行。 如果css都没加载完成js自然不会执行。以上属个人见解,实际情况自行测试。
浏览器对CSS阻塞渲染有两种处理方式,要么等css解析完一起渲染,chrome就是这么做的,但是会造成白屏; 要么先把无样式的dom渲染出来等css解析好了再渲染一次,Firefox就是这么做的,但是会造成无样式内容闪烁。
参考文章
648.vite 涉及到了哪些底层原理?【热度: 510】【工程化】【出题公司: TOP100互联网】
关键词:vite 原理
Vite 涉及到以下几个底层原理:
-
ES 模块:Vite 使用了 ES 模块来管理和加载模块。ES 模块是 JavaScript 的标准模块系统,相比于传统的 CommonJS 或 AMD,ES 模块具有更好的静态分析能力和更高的性能。Vite 通过使用浏览器原生的 ES 模块加载器,可以实现按需加载和快速构建。
-
HTTP/2:Vite 借助于现代浏览器的 HTTP/2 支持来实现更高效的资源加载。HTTP/2 支持多路复用,可以同时请求多个资源,避免了传统的 HTTP/1 中的队头阻塞问题,加快了资源加载速度。
-
编译器:Vite 使用了自定义的编译器来处理开发时的模块解析和转换。它能够识别模块的依赖关系,并将模块转换为浏览器可直接执行的代码。Vite 的编译器支持热模块替换(HMR),可以在代码修改时自动更新浏览器中的页面,提高开发效率。
-
中间件:Vite 使用了基于 Koa 框架的中间件来处理开发服务器。通过中间件,Vite 可以拦截和处理开发时的 HTTP 请求,并根据请求的路径返回相应的模块文件。中间件还可以处理各种开发时的特殊需求,如代理 API 请求、路由转发等。
Vite 基于 ES 模块、HTTP/2、自定义编译器和中间件等底层原理,实现了快速的模块加载和开发体验。 这些原理的运用使得 Vite 在开发环境下能够提供更快的构建速度和更好的开发体验。
649.vite 编译器的组成部分【热度: 335】【工程化】【出题公司: TOP100互联网】
关键词:vite 编译器组成部分
Vite 编译器的主要组成部分包括:
-
esbuild:一个快速的 JavaScript 打包器,用于在开发阶段进行实时编译。esbuild 提供了快速的冷启动和热模块替换功能,能够极大地加快开发环境的构建速度。
-
Rollup:一个强大的 JavaScript 模块打包器,在生产构建阶段使用。Rollup 能够将源代码打包为最终可发布的文件,支持代码分割、Tree Shaking 等优化技术,生成更小、更高效的代码包。
-
前端开发服务器:Vite 还提供了一个内置的开发服务器,用于提供开发环境下的静态文件服务和构建工具集成。这个服务器能够利用 esbuild 实现快速的编译和热模块替换,使开发者在开发过程中可以快速地预览和调试代码。
-
插件系统:Vite 通过插件系统来扩展其功能。开发者可以编写自定义的插件,用于处理特定的文件类型、引入额外的功能或者定制构建过程。插件系统使得 Vite 能够与各种前端框架和工具集成,并提供更灵活的开发体验。
650.vite 编译器有啥特点?【热度: 237】【工程化】【出题公司: TOP100互联网】
关键词:vite 编译器特点
Vite 是一个基于现代浏览器原生 ES 模块导入功能的开发工具和构建系统。与传统的打包工具相比,Vite 具有以下几个特点:
-
快速冷启动:Vite 采用了一种新的开发服务器,利用浏览器原生的 ES 模块导入功能,无需提前构建和打包,可以实现快速的冷启动,并在浏览器中按需编译和加载代码。这种特性使得开发时的重新加载速度非常快,提高了开发效率。
-
按需编译:Vite 通过解析导入的模块路径,只编译当前需要的模块,而不是像传统的打包工具一样对整个项目进行全量编译。这种按需编译的方式减少了不必要的重复编译和构建时间,提高了构建速度。
-
零配置:Vite 提供了一种零配置的开发体验,无需繁琐的配置文件,可以快速开始项目的开发。Vite 默认支持常见的前端开发场景,如 Vue、React、TypeScript 等,开发者可以通过简单的配置进行个性化定制。
-
原生 ES 模块支持:Vite 利用浏览器原生的 ES 模块导入功能,可以直接在浏览器中引入 ES 模块,无需经过任何编译和转换,提供了更好的开发体验和更高的性能。
-
插件化:Vite 的构建系统采用了插件化的架构,开发者可以根据需求选择和配置不同的插件来扩展 Vite 的功能。Vite 提供了丰富的插件生态系统,使得开发者可以定制化地满足项目需求。
651.esbuild 和 rollup 都是 vite 的基础依赖, 那么他们有啥不同?【热度: 129】【工程化】【出题公司: TOP100互联网】
关键词:esbuild 和 rollup 区别
esbuild 和 Rollup 都是 Vite 的基础依赖,但它们在 Vite 中担负着不同的角色和任务。
-
esbuild:esbuild 是一个快速、可扩展的 JavaScript 打包器,它被用作 Vite 的默认构建工具。esbuild 的主要任务是将源代码转换为浏览器可以理解的代码,同时还支持压缩、代码分割、按需加载等功能。esbuild 利用其高性能的构建能力,实现了快速的开发服务器和热模块替换。
-
Rollup:Rollup 是一个 JavaScript 模块打包工具,也是 Vite 的另一个基础依赖。在 Vite 中,Rollup 主要用于生产构建阶段。它通过静态分析模块依赖关系,将多个模块打包为一个或多个最终的输出文件。Rollup 支持多种输出格式,如 ES 模块、CommonJS、UMD 等,可以根据项目的需要进行配置。
尽管 esbuild 和 Rollup 都是 Vite 的基础依赖,但它们的分工是不同的。esbuild 用于开发服务器阶段,通过实时编译和提供模块来实现快速的冷启动和热模块替换。而 Rollup 用于生产构建阶段,将源代码打包为最终可发布的文件,以用于部署到生产环境。这样的分工使得 Vite 在开发过程中能够快速响应变化,并在构建过程中生成高效的最终输出文件。
652.vite 和 webpack 在热更新上有啥区别?【热度: 530】【工程化】【出题公司: 网易】
关键词:热更新区别
Vite 和 Webpack 在热更新上有一些区别:
-
模块级别的热更新:Vite 使用浏览器原生的 ES 模块系统,可以实现模块级别的热更新,即只更新修改的模块,而不需要刷新整个页面。这样可以提供更快的开发迭代速度。而在 Webpack 中,热更新是基于文件级别的,需要重新构建并刷新整个页面。
-
开发环境下的无构建:Vite 在开发环境下不会对代码进行打包构建,而是直接利用浏览器原生的模块导入功能,通过 HTTP 服务器提供模块的即时响应。这样可以避免了构建和重新编译的时间,更快地反映出代码的修改。而在 Webpack 中,每次修改代码都需要重新构建和编译,耗费一定的时间。
-
构建环境下的优化:尽管 Vite 在开发环境下不进行打包构建,但在生产环境下,它会通过预构建的方式生成高性能的静态资源,以提高页面加载速度。而 Webpack 则通过将所有模块打包成 bundle 文件,进行代码压缩和优化,以及使用各种插件和配置来优化构建结果。
总的来说,Vite 在热更新上比 Webpack 更加快速和精细化,能够在开发过程中提供更好的开发体验和更快的反馈速度。但是,Webpack 在构建环境下有更多的优化和功能,适用于更复杂的项目需求。
以下是 Vite 和 Webpack 在热更新方面的对比表格:
| 特点 | Vite | Webpack |
|---|---|---|
| 实时热更新 | 支持模块级别的热更新,即只更新修改的模块,无需刷新整个页面 | 支持文件级别的热更新,修改任何文件都会触发整个应用的重新构建和刷新 |
| 构建速度 | 在开发环境下,利用浏览器原生的模块导入功能,不需要进行打包构建,启动速度更快 | 需要进行打包构建,每次修改代码都需要重新构建和编译,相对较慢 |
| 开发体验 | 提供更好的开发体验,修改代码后快速反馈,无需等待全量构建 | 反馈速度较慢,需要等待每次构建和编译完成 |
| 适用场景 | 适用于中小型项目,追求开发效率的前端项目 | 适用于大型项目,有复杂需求和更多构建优化的前端项目 |
653.需要在跨域请求中携带另外一个域名下的 Cookie 该如何操作?【热度: 254】【网络】【出题公司: Shopee】
关键词:跨域 cookie
在跨域请求中携带另外一个域名下的 Cookie,需要通过设置响应头部的Access-Control-Allow-Credentials字段为true,并且请求头部中添加withCredentials字段为true。
在服务端需要设置响应头部的Access-Control-Allow-Origin字段为指定的域名,表示允许指定域名的跨域请求携带Cookie。
下面是一个示例代码(Node.js):
1const express = require('express');
2const app = express();
3
4app.use((req, res, next) => {
5 res.setHeader('Access-Control-Allow-Origin', 'http://example.com');
6 res.setHeader('Access-Control-Allow-Credentials', 'true');
7 next();
8});
9
10app.get('/api/data', (req, res) => {
11 // 处理请求
12 res.send('Response Data');
13});
14
15app.listen(3000, () => {
16 console.log('Server is running on port 3000');
17});在客户端发起跨域请求时,需要设置请求头部的withCredentials字段为true,示例代码(JavaScript):
1fetch('http://example.com/api/data', {
2 credentials: 'include',
3})
4 .then(response => response.text())
5 .then(data => {
6 console.log(data);
7 })
8 .catch(error => {
9 console.error('Error:', error);
10 });以上代码中,Access-Control-Allow-Origin设置为’http://example.com’,表示允许该域名的跨域请求携带Cookie。fetch请求的参数中,credentials设置为’include’ 表示请求中携带Cookie。
654.[webpack] webpack-dev-server 作用是啥?【热度: 387】【工程化】【出题公司: PDD】
关键词:webpack-dev-server 作用
webpack-dev-server 是一个开发服务器,它提供了一个快速开发的环境,并且配合Webpack使用。它的作用主要有以下几个方面:
-
自动编译和打包:webpack-dev-server 可以监听源文件的变化,当文件发生改动时,它会自动重新编译和打包,保证开发过程中始终使用最新的代码。
-
热模块替换(Hot Module Replacement):webpack-dev-server 支持热模块替换,即在开发过程中,当某个模块发生变化时,只会重新编译该模块,而不是整个应用,然后将变更的模块替换到浏览器中,从而实现实时更新,无需手动刷新页面。
-
代理和反向代理:webpack-dev-server 可以配置代理,用于解决前端开发中跨域请求的问题。可以将某些请求转发到其他服务器,或者改变请求的路径。
-
路由处理:webpack-dev-server 也支持将所有请求重定向到特定的 HTML 文件,用于前端单页应用的路由处理,可以通过配置实现 SPA(Single Page Application)的路由。
-
静态文件服务:webpack-dev-server 可以将打包后的文件提供给浏览器访问,可以通过配置指定静态文件的路径,并且通过指定的端口提供服务。
总结来说,webpack-dev-server 提供了一个方便的开发环境,可以实时编译和打包代码,并且支持热模块替换,代理和反向代理,路由处理等功能,提高了开发效率和开发体验。
webpack-dev-server 有编译和打包的能力?
webpack-dev-server本身并没有编译和打包的能力,它是使用Webpack来实现编译和打包的。 webpack-dev-server是基于Webpack的一个开发服务器,** 它通过监听源文件的变化,自动调用Webpack进行编译和打包,并将打包后的文件提供给浏览器访问**。 这样可以在开发过程中实时更新代码,无需手动进行编译和打包操作。 webpack-dev-server还支持热模块替换等功能,提供了一个方便的开发环境。 但是需要注意的是,webpack-dev-server只适用于开发阶段,它并不会生成最终的打包文件,而是将打包后的文件保存在内存中,提供给浏览器访问。 在真正发布项目时,还需要运行Webpack的打包命令生成最终的打包文件。
655.[webpack] webpack-dev-server 为何不适用于线上环境?【热度: 88】【工程化】【出题公司: TOP100互联网】
关键词:webpack-dev-server 作用
webpack-dev-server并不适用于线上环境的原因有以下几点:
性能问题:webpack-dev-server是一个开发服务器,它将编译后的文件保存在内存中,并提供给浏览器访问。这种方式在开发阶段可以提供快速的编译和热模块替换,但在线上环境中,内存中保存的文件无法持久化,每次启动服务器都需要重新编译和打包,这会影响性能,并且占用服务器资源。
-
安全问题:webpack-dev-server并不进行代码压缩和混淆,源代码是以明文形式传输给浏览器的。这将使得攻击者可以很容易地获取到项目的源代码,从而可能导致安全漏洞。
-
缺少文件输出:webpack-dev-server并没有生成最终的打包文件,它只是将打包后的文件保存在内存中,提供给浏览器访问。这样就无法进行资源的版本管理和持久化存储,无法做到长期的缓存和优化。
656.常见的登录鉴权方式有哪些?【热度: 557】【web应用场景】【出题公司: TOP100互联网】
关键词:登录鉴权方式
前端登录鉴权的方式主要有以下几种:
-
基于Session Cookie的鉴权:
- cookie: 用户在登录成功后,服务器会生成一个包含用户信息的Cookie,并返回给前端。前端在后续的请求中会自动携带这个Cookie,在服务器端进行验证和识别用户身份。
- Session: 用户登录成功后,服务器会在后端保存用户的登录状态信息,并生成一个唯一的Session ID,将这个Session ID 返回给前端。前端在后续的请求中需要携带这个Session ID,服务器通过Session ID 来验证用户身份。
-
单点登录(Single Sign-On,SSO):单点登录是一种将多个应用系统进行集成的认证方式。用户只需登录一次,即可在多个系统中完成认证,避免了重复登录的麻烦。常见的单点登录协议有CAS(Central Authentication Service)、SAML(Security Assertion Markup Language)等。
-
OpenID Connect(OIDC):OIDC是基于OAuth2.0的身份验证协议,通过在认证和授权过程中引入身份提供者,使得用户可以使用第三方身份提供者(如Google、Facebook等)进行登录和授权,从而实现用户身份验证和授权的功能。
-
OAuth2.0:OAuth2.0是一个授权框架,用于授权第三方应用访问用户的资源。它通过授权服务器颁发令牌(Token),使得第三方应用可以代表用户获取资源的权限,而无需知道用户的真实凭证。
-
LDAP(Lightweight Directory Access Protocol):LDAP是一种用于访问和维护分布式目录服务的协议。在登录鉴权中,LDAP常用于验证用户的身份信息,如用户名和密码,通过与LDAP服务器进行通信来进行用户身份验证。
-
2FA(Two-Factor Authentication):二次验证是一种提供额外安全层的身份验证方式。与传统的用户名和密码登录不同,2FA需要用户提供第二个验证因素,如手机验证码、指纹识别、硬件令牌等,以提高账户的安全性。
658.单点登录是如何实现的?【热度: 647】【web应用场景】【出题公司: TOP100互联网】
关键词:单点登录实现、单点登录流程
单点登录:Single Sign On,简称SSO。用户只要登录一次,就可以访问所有相关信任应用的资源。企业里面用的会比较多,有很多内网平台,但是只要在一个系统登录就可以。
- 单一域名:可以把 cookie 种在根域名下实现单点登录
- 多域名:常用 CAS来解决,新增一个认证中心的服务。CAS(Central Authentication Service)是实现SSO单点登录的框架
- 用户访问系统A,判断未登录,则直接跳到认证中心页面
- 在认证中心页面输入账号,密码,生成令牌,重定向到 系统A
- 在系统A拿到令牌到认证中心去认证,认证通过,则建立对话
- 用户访问系统B,发现没有有效会话,则重定向到认证中心
- 认证中心发现有全局会话,新建令牌,重定向到系统B
- 在系统B使用令牌去认证中心验证,验证成功后,建议系统B的局部会话。
- 参考流程图:
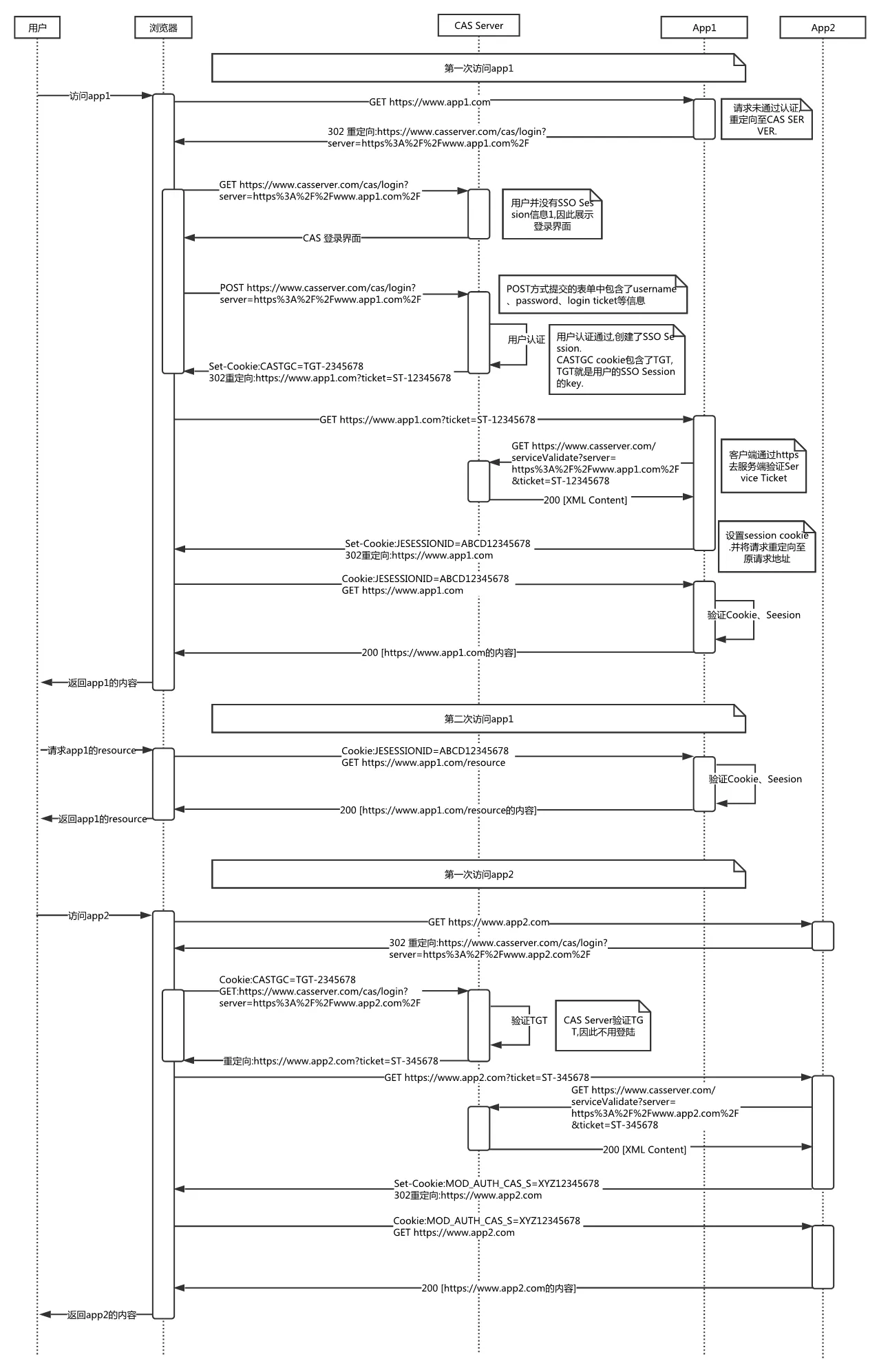

下面是举例来详细说明CAS实现单点登录的流程:
一、第一次访问系统A
-
用户访问系统A (www.app1.com),,/) 跳转认证中心 client(www.sso.com),,/) 然后输入用户名,密码登录,然后认证中心 serverSSO 把 cookieSSO 种在认证中心的域名下 (www.sso.com),,/) 重定向到系统A,并且带上生成的 ticket 参数 (www.app1.com?ticket =xxx)
-
系统A (www.app1.com?ticket =xxx)请求系统A的后端 serverA ,serverA 去 serverSSO 验证,通过后,将cookieA种在 www.app1.com下
二、第二次访问系统A 直接携带 cookieA 去访问后端,验证通过后,即登录成功。
三、第三次访问系统B
-
访问系统B (www.app2.com),,/) 跳转到认证中心 client(www.sso.com),,/) 这个时候会把认证中心的cookieSSO也携带上,发现用户已登录过,则直接重定向到系统B(www.app2.com),,/) 并且带上生成的ticket参数(www.app2.com?ticket =xxx)
-
系统B (www.app2.com?ticket =xxx)请求系统B的后端 serverB,serverB 去 serverSSO 验证,通过后,将cookieB种在www.app2.com下
注意cookie生成时机及种的位置。
- cookieSSO,SSO域名下的cookie
- cookieA,系统A域名下的cookie
- cookieB,系统B域名下的cookie
https://juejin.cn/post/7195588906809032764 https://juejin.cn/post/7044328327762411534
659.OAuth2.0 是什么登录方式【热度: 210】【web应用场景】【出题公司: TOP100互联网】
关键词:OAuth2.0 登录实现、OAuth2.0 鉴权
OAuth2.0并不是一种特定的登录方式,而是一种授权框架,用于授权第三方应用访问用户的资源。它被广泛应用于身份验证和授权的场景中。
OAuth2.0通过引入授权服务器、资源服务器和客户端等角色,实现了用户授权和资源访问的分离。具体流程如下:
- 用户向客户端发起请求,请求访问某个资源。
- 客户端将用户重定向到授权服务器,并携带自己的身份凭证(客户端ID)。
- 用户在授权服务器登录,并授权客户端访问特定的资源。
- 授权服务器验证用户身份,并生成访问令牌(Access Token)。
- 授权服务器将访问令牌发送给客户端。
- 客户端使用访问令牌向资源服务器请求访问资源。
- 资源服务器验证访问令牌的有效性,并根据权限决定是否允许访问资源。
- 资源服务器向客户端返回请求的资源。
在这个过程中,OAuth2.0通过访问令牌实现了用户和资源服务器之间的身份授权和资源访问分离。客户端无需知道或存储用户的凭证(如用户名和密码),而是使用访问令牌代表用户向资源服务器请求资源,提供了更安全和便捷的授权方式。
以下是使用Fetch API来发起请求的示例代码:
1// 1. 客户端应用程序发起授权请求,重定向用户到授权服务器的登录页面
2
3const authorizationEndpoint = 'https://example.com/oauth2/auth';
4const clientId = 'your_client_id';
5const redirectUri = 'https://yourapp.com/callback';
6const scope = 'read write';
7const state = 'random_state_value';
8
9const authorizationUrl = `${authorizationEndpoint}?client_id=${clientId}&redirect_uri=${redirectUri}&scope=${scope}&state=${state}`;
10
11// 重定向用户到授权页面
12window.location.href = authorizationUrl;
13
14// 2. 在回调URL中获取授权码
15
16const callbackUrl = window.location.href;
17const urlParams = new URLSearchParams(callbackUrl.split('?')[1]);
18const authorizationCode = urlParams.get('code');
19
20// 3. 客户端应用程序使用授权码向授权服务器请求访问令牌
21
22const tokenEndpoint = 'https://example.com/oauth2/token';
23const clientSecret = 'your_client_secret';
24
25const tokenData = {
26 grant_type: 'authorization_code',
27 code: authorizationCode,
28 redirect_uri: redirectUri,
29 client_id: clientId,
30 client_secret: clientSecret
31};
32
33// 使用Fetch API请求访问令牌
34fetch(tokenEndpoint, {
35 method: 'POST',
36 headers: {
37 'Content-Type': 'application/x-www-form-urlencoded'
38 },
39 body: new URLSearchParams(tokenData)
40})
41 .then(response => response.json())
42 .then(data => {
43 const accessToken = data.access_token;
44
45 // 4. 客户端应用程序使用访问令牌向资源服务器请求受保护的资源
46 const resourceEndpoint = 'https://example.com/api/resource';
47
48 // 使用Fetch API请求受保护的资源
49 fetch(resourceEndpoint, {
50 method: 'GET',
51 headers: {
52 Authorization: `Bearer ${accessToken}`
53 }
54 })
55 .then(response => response.json())
56 .then(resourceData => {
57 // 处理返回的资源数据
58 console.log(resourceData);
59 })
60 .catch(error => {
61 console.error('Failed to retrieve resource:', error);
62 });
63 })
64 .catch(error => {
65 console.error('Failed to retrieve access token:', error);
66 });请注意,上述代码使用了Fetch API来发送HTTP请求。它使用了fetch函数来发送POST请求以获取访问令牌,并使用了Authorization头部来发送访问令牌获取受保护的资源。确保你的浏览器支持Fetch API,或者在旧版浏览器中使用polyfill库来兼容。与之前的代码示例一样,你需要根据你的情况替换URL和参数值。
661.web 系统里面, 如何对图片进行优化?【热度: 789】【工程化】【出题公司: TOP100互联网】
关键词:图片优化
图片作为网页和移动应用中不可或缺的元素之一,对于用户体验和网站性能都有着重要的影响。
加载速度是用户体验的关键因素之一,而大尺寸的图片会增加网页加载时间,导致用户等待时间过长,从而影响用户的满意度和留存率。通过优化图片,我们可以显著减少页面加载时间,提供更快速流畅的使用体验。
图片优化是提升用户体验、提高网站性能、减少流量消耗和增加搜索引擎曝光度的关键因素。为了提供更出色的用户体验,同时也提升网站的性能。总结了一下通用的图片优化首手段。
以下是对常用的图片格式jpg、png和webp进行深度对比的表格:
| 特性 | JPG | PNG | WebP |
|---|---|---|---|
| 压缩算法 | 有损压缩 | 无损压缩 | 有损压缩 |
| 透明度 | 不支持透明度 | 支持透明度 | 支持透明度 |
| 图片质量 | 可调整质量 | 无法调整质量 | 可调整质量 |
| 文件大小 | 相对较小 | 相对较大 | 相对较小 |
| 浏览器支持 | 支持在所有主流浏览器上显示 | 支持在所有主流浏览器上显示 | 部分浏览器支持 |
| 动画支持 | 不支持动画 | 不支持动画 | 支持动画 |
| 兼容性 | 兼容性较好 | 兼容性较好 | 兼容性较差 |
请注意,这个表格只是对这些格式的一般特征进行了总结,并不代表所有情况。实际情况可能因图像内容、压缩设置和浏览器支持等因素而有所不同。因此,在选择图像格式时,您应根据具体要求和应用场景进行评估和选择。
主要介绍 webpack 对图片进行压缩,可以使用以下步骤:
- 安装依赖:首先,确保你已经在项目中安装了webpack和相关的loader。可以使用以下命令安装所需的loader:
1npm install --save-dev file-loader image-webpack-loader - 配置Webpack:在Webpack的配置文件中进行相关配置。以下是一个简单的示例:
1const path = require('path');
2
3module.exports = {
4 entry: 'src/index.js',
5 output: {
6 filename: 'bundle.js',
7 path: path.resolve(__dirname, 'dist')
8 },
9 module: {
10 rules: [
11 {
12 test: /\.(png|jpe?g|gif)$/i,
13 use: [
14 {
15 loader: 'file-loader',
16 options: {
17 name: '[name].[ext]',
18 outputPath: 'images/'
19 }
20 },
21 {
22 loader: 'image-webpack-loader',
23 options: {
24 mozjpeg: {
25 progressive: true,
26 quality: 65
27 },
28 // optipng.enabled: false will disable optipng
29 optipng: {
30 enabled: false,
31 },
32 pngquant: {
33 quality: [0.65, 0.90],
34 speed: 4
35 },
36 gifsicle: {
37 interlaced: false,
38 },
39 // the webp option will enable WEBP
40 webp: {
41 quality: 75
42 }
43 }
44 }
45 ]
46 }
47 ]
48 }
49};上述配置中,我们使用file-loader将图片复制到输出目录,并使用image-webpack-loader对图片进行压缩和优化。
- 运行Webpack:现在,当你运行Webpack时,它将自动使用
image-webpack-loader对匹配到的图片进行压缩和优化。压缩后的图片将被复制到输出目录中。
Web图片优化的雪碧图(CSS Sprites)是一种将多个小图片合并为一个大图片的技术。通过将多个小图片合并成一张大图片,可以减少浏览器发送的请求次数,从而提高页面加载速度。
雪碧图的原理是通过CSS的background-image和background-position属性,将所需的小图片显示在指定的位置上。这样,只需加载一张大图,就可以显示多个小图片,减少了网络请求的数量,提高了页面加载速度。
听上去好像很麻烦, 实际上可以使用 webpack 插件 webpack-spritesmith 完成自动化处理雪碧图合成,我们在使用过程中正常使用即可。
以下是使用webpack-spritesmith插件来自动处理雪碧图的步骤:
- 安装插件:使用npm或yarn安装
webpack-spritesmith插件。
1npm install webpack-spritesmith --save-dev- 配置Webpack:在Webpack配置文件中,引入
webpack-spritesmith插件,并配置相应的选项。
1const SpritesmithPlugin = require('webpack-spritesmith');
2
3module.exports = {
4 // ...其他配置
5
6 plugins: [
7 new SpritesmithPlugin({
8 src: {
9 cwd: path.resolve(__dirname, 'path/to/sprites'), // 需要合并的小图片所在的目录
10 glob: '*.png' // 小图片的文件名格式
11 },
12 target: {
13 image: path.resolve(__dirname, 'path/to/output/sprite.png'), // 生成的雪碧图的路径和文件名
14 css: path.resolve(__dirname, 'path/to/output/sprite.css') // 生成的CSS样式表的路径和文件名
15 },
16 apiOptions: {
17 cssImageRef: 'path/to/output/sprite.png' // CSS样式表中引用雪碧图的路径
18 }
19 })
20 ]
21}- 使用雪碧图:在HTML中,使用生成的CSS样式类来显示相应的小图片。Webpack会自动处理雪碧图的合并和CSS样式的生成。例如:
然后,你可以按照以下方法在CSS中引用雪碧图:
CSS方式:
1div {
2 background: url(path/to/output/sprite.png) no-repeat;
3}
4
5.icon-facebook {
6 /* 设置小图标在雪碧图中的位置和大小 */
7 width: 32px;
8 height: 32px;
9 background-position: 0 0; /* 该小图标在雪碧图中的位置 */
10}
11
12.icon-twitter {
13 width: 32px;
14 height: 32px;
15 background-position: -32px 0; /* 该小图标在雪碧图中的位置 */
16}
17
18.icon-instagram {
19 width: 32px;
20 height: 32px;
21 background-position: -64px 0; /* 该小图标在雪碧图中的位置 */
22}在HTML中,你可以像下面这样使用对应的CSS类来显示相应的小图标:
1<div class="icon icon-facebook"></div>
2<div class="icon icon-twitter"></div>
3<div class="icon icon-instagram"></div>这样,Webpack会根据配置自动处理雪碧图,并生成对应的雪碧图和CSS样式表。CSS中的background属性会引用生成的雪碧图,并通过background-position来指定显示的小图标在雪碧图中的位置。
确保在CSS中指定了每个小图标在雪碧图中的位置和大小,以便正确显示。
使用Webpack自动处理雪碧图可以简化开发流程,并且可以根据需要自定义配置。webpack-spritesmith是一个常用的Webpack插件,可以帮助自动处理雪碧图。
如果你有很多图标类型的图片资源,并且想使用iconfont来处理这些资源,可以按照以下步骤进行处理:
-
获取图标资源:首先,你需要获取你想要的图标资源。你可以从
iconfont网站或其他图标库中选择和下载符合需求的图标。这个没有啥好说的, 直接推荐: https://www.iconfont.cn/ -
生成字体文件:接下来,你需要将这些图标转换成字体文件。你可以使用
iconfont提供的在线转换工具,将图标文件上传并生成字体文件(包括.ttf、.eot、.woff和.svg格式)。 -
引入字体文件:将生成的字体文件下载到本地,并在你的项目中引入。通常,你需要在CSS文件中通过
@font-face规则引入字体文件,并为字体定义一个唯一的名称。 -
使用图标:一旦字体文件引入成功,你可以在CSS中通过设置
content属性来使用图标。每个图标都会有一个对应的Unicode代码,你可以在iconfont提供的网站或字体文件中找到对应图标的Unicode代码,并通过设置content属性的值为该Unicode代码来使用图标。
以下是一个简单的示例,以帮助你更好地理解:
1@font-face {
2 font-family: 'iconfont';
3 src: url('path/to/iconfont.eot'); /* 引入字体文件 */
4 /* 其他格式的字体文件 */
5}
6
7.icon {
8 font-family: 'iconfont'; /* 使用定义的字体名称 */
9 font-size: 16px; /* 图标大小 */
10 line-height: 1; /* 图标行高 */
11}
12
13.icon-facebook::before {
14 content: '\e001'; /* 使用Unicode代码表示想要显示的图标 */
15}
16
17.icon-twitter::before {
18 content: '\e002'; /* 使用Unicode代码表示想要显示的图标 */
19}
20
21.icon-instagram::before {
22 content: '\e003'; /* 使用Unicode代码表示想要显示的图标 */
23}在上述示例中,我们首先通过@font-face引入了字体文件,并为字体定义了一个名称iconfont。然后,我们使用该名称作为font-family属性的值,以便在.icon 类中使用该字体。最后,我们通过在::before伪元素中设置content属性为图标的Unicode代码,来显示相应的图标。
在HTML中,你可以像下面这样使用对应的CSS类来显示相应的图标:
1<span class="icon icon-facebook"></span>
2<span class="icon icon-twitter"></span>
3<span class="icon icon-instagram"></span>通过上述步骤,你可以使用iconfont来处理你的图标资源,并在项目中方便地使用它们。确保在CSS中设置了图标的字体大小和行高,以便正确显示图标。
实际开发过程中, 为何会考虑 base64 ?
使用Base64图片的优势有以下几点:
-
减少HTTP请求数量:通常情况下,每个网页都需要加载多张图片,因此会发送多个HTTP请求来获取这些图片文件。使用Base64图片可以将图片数据嵌入到CSS或HTML文件中,减少了对服务器的请求次数,从而提高网页加载速度。
-
减少图片文件的大小 :Base64是一种编码方式,可以将二进制数据转换成文本字符串。通过使用Base64,可以将图片文件转换成文本字符串,并将其嵌入到CSS或HTML文件中。相比于直接引用图片文件,Base64编码的字符串通常会更小,因此可以减少图片文件的大小,从而减少了网页的总体积,加快了网页加载速度。
-
简化部署和维护:将图片数据嵌入到CSS或HTML文件中,可以减少文件的数量和复杂性,使得部署和维护变得更加简单和方便。此外,也不需要处理图片文件的路径和引用相关的问题。
-
实现一些特殊效果:通过Base64图片,可以实现一些特殊的效果,例如页面背景渐变、图标的使用等。这样可以避免使用额外的图片文件,简化了开发过程。
上面虽然说饿了挺多有点, 但是劣势也是很明显:
-
增加了文本文件的体积:因为Base64编码将二进制数据转换成文本字符串,所以会增加CSS或HTML文件的体积。在图片较大或数量较多时,这可能会导致文件变得庞大,从而导致网页加载速度变慢。
-
缓存问题:由于Base64图片被嵌入到了CSS或HTML文件中,如果图片内容有更新,那么整个文件都需要重新加载,而无法使用缓存。相比于独立的图片文件,Base64图片对缓存的利用效率较低。
使用Base64图片在一些特定的场景下可以提供一些优势,但也需要权衡其带来的一些缺点。在实际开发中,可以根据具体的需求和情况,选择是否使用Base64图片。 所以建议复用性很强, 变更率较低, 且 小于 10KB 的图片文件, 可以考虑 base64
如何使用? 有要介绍一下 webpack 插件了: url-loader 或 file-loader
要使用Webpack将图片自动转换为Base64编码,您需要执行以下步骤:
- 安装依赖:首先,确保您已经安装了
url-loader或file-loader,它们是Webpack的两个常用的加载器。
1npm install url-loader --save-dev- 配置Webpack:在Webpack的配置文件中,添加对图片文件的处理规则。您可以在
module.rules数组中添加一个新的规则,以匹配图片文件的后缀。
1module.exports = {
2 // ...
3 module: {
4 rules: [
5 // ...
6 {
7 test: /\.(png|jpe?g|gif)$/i,
8 use: [
9 {
10 loader: 'url-loader',
11 options: {
12 limit: 8192, // 设置图片大小的阈值,小于该值的图片会被转为Base64
13 outputPath: 'images', // 输出路径
14 publicPath: 'images', // 资源路径
15 },
16 },
17 ],
18 },
19 ],
20 },
21 // ...
22};在上面的示例中,配置了一个处理png、jpeg、jpg和gif格式图片的规则。使用url-loader加载器,并设置了一些选项,例如limit限制了图片大小的阈值,小于该值的图片将会被转换为Base64编码。
- 在代码中引用图片:在您的代码中,可以像引用普通图片一样引用图片文件,Webpack会根据配置自动将其转换为Base64编码。
1import imgSrc from './path/to/image.png';
2
3const imgElement = document.createElement('img');
4imgElement.src = imgSrc;
5document.body.appendChild(imgElement);- 构建项目:最后,使用Webpack构建项目,它会根据配置自动将符合规则的图片文件转换为Base64编码,并将其嵌入到生成的输出文件中。
这样,Webpack就会自动将图片转换为Base64编码,并将其嵌入到生成的输出文件中。请注意,在使用Base64图片时,需要权衡文件大小和性能,适度使用Base64编码,避免过大的文件导致网页加载变慢。
CND 加载图片优势非常明显:
-
加速网页加载速度:CDN通过将图片资源分布在全球的多个节点上,使用户能从离自己最近的节点获取资源,从而大大减少了网络延迟和加载时间。这可以提高网页的加载速度和用户体验。
-
减轻服务器负载:CDN充当了一个缓冲层,当用户请求图片资源时,CDN会将图片资源从源服务器获取并缓存在节点中,下次再有用户请求同一资源时,CDN会直接从节点返回,减少了对源服务器的请求,分担了服务器的负载。
-
提高并发性能:CDN节点分布在不同地区,用户请求图片资源时可以从离他们最近的节点获取,这可以减少网络拥塞和并发请求,提高了并发性能。
-
节省带宽成本:CDN的节点之间会自动选择最优路径,有效利用了带宽资源,减少了数据传输的成本,尤其在大量图片资源请求时,能够带来显著的成本节省。
-
提供高可用性:CDN通过分布式存储和负载均衡技术,提供了高可用性和容错能力。即使某个节点或源服务器发生故障,CDN会自动切换到其他可用节点,确保用户能够正常访问图片资源。
总之,使用CDN加载图片可以提高网页加载速度、降低服务器负载、提高并发性能、节省带宽成本,并提供高可用性,从而改善用户体验和网站性能。
图片懒加载是一种在网站或应用中延迟加载图片的技术。它的主要目的是减少页面的初始加载时间,并提高用户的浏览体验。
-
原理:图片懒加载的原理是只在用户需要时加载图片,而不是在页面初始加载时全部加载。这通常通过将图片的真实地址存储在自定义属性(例如
data-src)中,而不是在src属性中。然后,在图片进入浏览器视图时,通过JavaScript动态将data-src的值赋给src属性,触发图片的加载。 -
优势:图片懒加载可以显著减少初始页面的加载时间,特别是当页面中有大量图片时。它使页面加载变得更快,提高了用户的浏览体验。此外,懒加载还可以节省带宽和减轻服务器负载,因为只有当图片进入视图时才会加载。
-
实现方法:图片懒加载可以通过纯JavaScript实现,也可以使用现成的JavaScript库,如
LazyLoad.js、Intersection Observer API等。这些库提供了方便的API和配置选项,可以自定义懒加载的行为和效果。
最佳实践:在使用图片懒加载时,可以考虑一些最佳实践。例如,设置一个占位符或加载中的动画,以提供更好的用户体验。另外,确保在不支持JavaScript的情况下仍然可用,并为可访问性提供替代文本(alt属性)。此外,对于移动设备,可以考虑使用响应式图片来适应不同的屏幕分辨率。
实现举例:
图片懒加载可以延迟图片的加载,只有当图片即将进入视口范围时才进行加载。这可以大大减轻页面的加载时间,并降低带宽消耗,提高了用户的体验。以下是一些常见的实现方法:
- Intersection Observer API
Intersection Observer API 是一种用于异步检查文档中元素与视口叠加程度的API。可以将其用于检测图片是否已经进入视口,并根据需要进行相应的处理。
1let observer = new IntersectionObserver(function(entries) {
2 entries.forEach(function(entry) {
3 if (entry.isIntersecting) {
4 const lazyImage = entry.target;
5 lazyImage.src = lazyImage.dataset.src;
6 observer.unobserve(lazyImage);
7 }
8 });
9});
10
11const lazyImages = [...document.querySelectorAll(".lazy")];
12lazyImages.forEach(function(image) {
13 observer.observe(image);
14});- 自定义监听器
或者,可以通过自定义监听器来实现懒加载。其中,应该避免在滚动事件处理程序中频繁进行图片加载,因为这可能会影响性能。相反,使用自定义监听器只会在滚动停止时进行图片加载。
1function lazyLoad() {
2 const images = document.querySelectorAll(".lazy");
3 const scrollTop = window.pageYOffset;
4 images.forEach((img) => {
5 if (img.offsetTop < window.innerHeight + scrollTop) {
6 img.src = img.dataset.src;
7 img.classList.remove("lazy");
8 }
9 });
10}
11
12let lazyLoadThrottleTimeout;
13document.addEventListener("scroll", function() {
14 if (lazyLoadThrottleTimeout) {
15 clearTimeout(lazyLoadThrottleTimeout);
16 }
17 lazyLoadThrottleTimeout = setTimeout(lazyLoad, 20);
18});在这个例子中,我们使用了 setTimeout() 函数来延迟图片的加载,以避免在滚动事件的频繁触发中对性能的影响。
无论使用哪种方法,都需要为需要懒加载的图片设置占位符,并将未加载的图片路径保存在 data 属性中,以便在需要时进行加载。这些占位符可以是简单的 div 或样式类,用于预留图片的空间,避免页面布局的混乱。
1<!-- 占位符示例 -->
2<div class="lazy-placeholder" style="background-color: #ddd;height: 500px;"></div>
3
4<!-- 图片示例 -->
5<img class="lazy" data-src="path/to/image.jpg" alt="预览图" />图片预加载是一种在网站或应用中提前加载图片资源的技术。它的主要目的是在用户实际需要加载图片之前,将其提前下载到浏览器缓存中。
图片预加载通常是在页面加载过程中或在特定事件触发前异步加载图片资源。 通过使用 JavaScript,可以在网页DOM元素中创建一个新的Image对象,并将要预加载的图片的URL赋值给该对象的src属性。 浏览器在加载过程中会提前下载这些图片,并将其缓存起来,以备将来使用。
图片预加载可以使用原生JavaScript实现,也可以使用现成的JavaScript库,如Preload.js、LazyLoad.js等。这些库提供了方便的API和配置选项,可以灵活地控制预���载的行为和效果。
实现图片预加载可以使用原生JavaScript或使用专门的JavaScript库。下面分别介绍两种方式的实现方法:
- 使用原生JavaScript实现图片预加载:
1function preloadImage(url) {
2 return new Promise(function(resolve, reject) {
3 var img = new Image();
4 img.onload = resolve;
5 img.onerror = reject;
6 img.src = url;
7 });
8}
9
10// 调用预加载函数
11preloadImage('image.jpg')
12 .then(function() {
13 console.log('图片加载成功');
14 // 在此处可以执行加载成功后的操作,例如显示图片等
15 })
16 .catch(function() {
17 console.error('图片加载失败');
18 // 在此处可以执行加载失败后的操作,例如显示错误信息等
19 });在上述代码中,我们定义了一个preloadImage函数,它使用Image对象来加载图片资源。通过onload事件和onerror事件来监听图片加载完成和加载错误的情况,并使用Promise对象进行异步处理。
- 使用JavaScript库实现图片预加载:
使用JavaScript库可以更简便地实现图片预加载,并提供更多的配置选项和功能。以下以Preload.js库为例进行说明:
首先,在HTML文件中引入Preload.js库:
1<script src="preload.js"></script>然后,在JavaScript代码中使用Preload.js库来进行图片预加载:
1var preload = new createjs.LoadQueue();
2preload.on("complete", handleComplete);
3preload.on("error", handleError);
4preload.loadFile('image.jpg');
5
6function handleComplete() {
7 console.log('图片加载成功');
8 // 在此处可以执行加载成功后的操作,例如显示图片等
9}
10
11function handleError() {
12 console.error('图片加载失败');
13 // 在此处可以执行加载失败后的操作,例如显示错误信息等
14}在上述代码中,我们首先创建一个LoadQueue对象,并使用on方法来监听加载完成和加载错误的事件。然后使用loadFile方法来指定要预加载的图片资源的URL。
当图片加载完成时,handleComplete函数会被调用,我们可以在此处执行加载成功后的操作。当图片加载错误时,handleError函数会被调用,我们可以在此处执行加载失败后的操作。
以上是两种常用的实现图片预加载的方法,根据具体需求和项目情况选择合适的方式来实现图片预加载。
要在不同分辨率的设备上显示不同尺寸的图片,你可以使用<picture>元素和<source>元素来实现响应式图片。以下是一个示例:
1<picture>
2 <source media="(min-width: 1200px)" srcset="large-image.jpg">
3 <source media="(min-width: 768px)" srcset="medium-image.jpg">
4 <source srcset="small-image.jpg">
5 <img src="fallback-image.jpg" alt="Fallback Image">
6</picture>在上面的示例中,<picture>元素内部有多个<source>元素,每个<source>元素通过srcset属性指定了对应分辨率下的图片链接。media 属性可以用来指定在哪个分辨率下应用对应的图片。如果没有任何<source>元素匹配当前设备的分辨率,那么就会使用<img>元素的src属性指定的图片链接。
可以根据不同分辨率的设备,提供不同尺寸和质量的图片,以优化用户的视觉体验和页面加载性能。
有可以使用 webpack responsive-loader 来实现自动根据设备分辨率加载不同的倍图:
依赖安装:
1npm install responsive-loader sharp --save-dev webpack 配置示范
1module.exports = {
2 entry: { ... },
3 output: { ... },
4 module: {
5 rules: [
6 {
7 test: /\.(jpe?g|png|webp)$/i,
8 use: [
9 {
10 loader: "responsive-loader",
11 options: {
12 adapter: require('responsive-loader/sharp'),
13 sizes: [320, 640, 960, 1200, 1800, 2400],
14 placeholder: true,
15 placeholderSize: 20
16 },
17 },
18 ],
19 }
20 ]
21 },
22}在CSS中使用它(如果使用多个大小,则只使用第一个调整大小的图像)
1.myImage {
2 background: url('myImage.jpg?size=1140');
3}
4
5@media (max-width: 480px) {
6 .myImage {
7 background: url('myImage.jpg?size=480');
8 }
9}导入图片到 JS 中:
1import responsiveImage from 'img/myImage.jpg?sizes[]=300,sizes[]=600,sizes[]=1024,sizes[]=2048';
2import responsiveImageWebp from 'img/myImage.jpg?sizes[]=300,sizes[]=600,sizes[]=1024,sizes[]=2048&format=webp';
3
4// Outputs
5// responsiveImage.srcSet => '2fefae46cb857bc750fa5e5eed4a0cde-300.jpg 300w,2fefae46cb857bc750fa5e5eed4a0cde-600.jpg 600w,2fefae46cb857bc750fa5e5eed4a0cde-600.jpg 600w ...'
6// responsiveImage.images => [{height: 150, path: '2fefae46cb857bc750fa5e5eed4a0cde-300.jpg', width: 300}, {height: 300, path: '2fefae46cb857bc750fa5e5eed4a0cde-600.jpg', width: 600} ...]
7// responsiveImage.src => '2fefae46cb857bc750fa5e5eed4a0cde-2048.jpg'
8// responsiveImage.toString() => '2fefae46cb857bc750fa5e5eed4a0cde-2048.jpg'
9...
10<picture>
11 <source srcSet={responsiveImageWebp.srcSet} type='image/webp' sizes='(min-width: 1024px) 1024px, 100vw'/>
12 <img
13 src={responsiveImage.src}
14 srcSet={responsiveImage.srcSet}
15 width={responsiveImage.width}
16 height={responsiveImage.height}
17 sizes='(min-width: 1024px) 1024px, 100vw'
18 loading="lazy"
19 />
20</picture>
21...实现渐进式加载的主要思想是先加载一张较低分辨率的模糊图片,然后逐步加载更高分辨率的图片。
下面是实现渐进式加载图片的一般步骤:
-
创建一张模糊的低分辨率图片。可以使用图片处理工具将原始图片进行模糊处理,或者使用低分辨率的缩略图作为初始图片。
-
使用
<img>标签将低分辨率的图片设置为src属性。这将立即加载并显示这张低分辨率的图片。 -
在加载低分辨率图片时,同时加载高分辨率的原始图片。可以将高分辨率图片的URL设置为
data-src等自定义属性,或者使用JavaScript动态加载高清图片。 -
使用JavaScript监听图片的加载事件,在高分辨率图片加载完成后,将其替换低分辨率图片的
src属性,以实现渐进式加载的效果。
下面是一个示例代码,演示了如何实现渐进式加载图片:
1<!-- HTML -->
2<img src="blur-image.jpg" data-src="high-res-image.jpg" alt="Image">
3
4<script>
5 // JavaScript
6 const image = document.querySelector('img');
7
8 // 监听高分辨率图片加载完成事件
9 image.addEventListener('load', () => {
10 // 替换低分辨率图片的src属性
11 image.src = image.dataset.src;
12 });
13</script>在上面的示例中,一开始会显示一张模糊的低分辨率图片,然后在高分辨率图片加载完成后,将其替换为高分辨率图片,实现了渐进式加载的效果。
渐进式加载图片可以减少用户等待时间,提供更好的用户体验。然而,需要注意的是,为了实现渐进式加载,需要额外加载高分辨率的图片,这可能会增加页面加载时间和网络带宽消耗。因此,开发者需要在性能和用户体验之间进行权衡,并根据实际情况进行选择和优化。