2023.03.09 - 2023.03.15 更新收集面试问题(45道题)【2部分】
获取更多面试问题可以访问
github 地址: https://github.com/pro-collection/interview-question/issues
gitee 地址: https://gitee.com/yanleweb/interview-question/issues
目录:
-
高级开发者相关问题【共计 2 道题】
- 84.手写实现 call、apply、bind?【JavaScript】
- 85.知道 JS 中的尾调用吗,如何做尾调优化?【JavaScript】
-
资深开发者相关问题【共计 3 道题】
- 83.react和vue的区别?【web框架】
- 86.V8 引擎了解多少?【Nodejs、网络】
- 87.如何进行 node 内存优化?【Nodejs】
84.手写实现 call、apply、bind?【JavaScript】
https://www.jianshu.com/p/6a1bc149b598
简单粗暴地来说,call,apply,bind是用于绑定this指向的。
我们单独看看ECMAScript规范对apply的定义,看个大概就行:
通过定义简单说一下call和apply方法,他们就是参数不同,作用基本相同。
1、每个函数都包含两个非继承而来的方法:apply()和call()。
2、他们的用途相同,都是在特定的作用域中调用函数。
3、接收参数方面不同,apply()接收两个参数,一个是函数运行的作用域(this),另一个是参数数组。
4、call()方法第一个参数与apply()方法相同,但传递给函数的参数必须列举出来。
一个简单的demo:
1let yanle = {
2 name: 'yanle',
3 sayHello: function (age) {
4 console.log(`hello, i am ${this.name} and ${age} years old`);
5 }
6};
7let lele = {
8 name: 'lele'
9};
10yanle.sayHello(26); // hello, i am yanle and 26 years old
11
12yanle.sayHello.call(lele, 20); // hello, i am lele and 20 years old
13yanle.sayHello.apply(lele, [21]); // hello, i am lele and 21 years old结果都相同。从写法上我们就能看出二者之间的异同。 相同之处在于,第一个参数都是要绑定的上下文,后面的参数是要传递给调用该方法的函数的。 不同之处在于,call方法传递给调用函数的参数是逐个列出的,而apply则是要写在数组中。
总结一句话介绍call和apply
call()方法在使用一个指定的this值和若干个指定的参数值的前提下调用某个函数或方法。
apply()方法在使用一个指定的this值和参数值必须是数组类型的前提下调用某个函数或方法
上面代码,我们注意到了两点:
1、call和apply改变了this的指向,指向到lulin
2、sayHello函数执行了
这里默认大家都对this有一个基本的了解,知道什么时候this该指向谁, 我们结合这两句话来分析这个通用函数:f.apply(o),我们直接看一本书对其中原理的解读, 具体什么书,我也不知道,参数我们先不管,先了解其中的大致原理。

知道了这个基本原来我们再来看看刚才jawil.sayHello.call(lulin, 24)执行的过程:
1// 第一步
2lulin.fn = jawil.sayHello
3// 第二步
4lulin.fn()
5// 第三步
6delete lulin.fn上面的说的是原理,可能你看的还有点抽象,下面我们用代码模拟实现apply一下。
根据这个思路,我们可以尝试着去写第一版的 applyOne 函数:
1Function.prototype.applyOne = function (context) {
2 context.fn = this;
3 context.fn();
4 delete context.fn;
5};
6let yanle = {
7 name: 'yanle',
8 sayHello: function (age) {
9 console.log(`hello, i am ${this.name} and ${age} years old`);
10 }
11};
12let lele = {
13 name: 'lele'
14};
15yanle.sayHello.applyOne(lele); // hello, i am lele and undefined years old正好可以打印lulin而不是之前的jawil了。
最一开始也讲了,apply函数还能给定参数执行函数。
注意:传入的参数就是一个数组,很简单,我们可以从Arguments对象中取值, Arguments不知道是何物,赶紧补习,此文也不太适合初学者,第二个参数就是数组对象, 但是执行的时候要把数组数值传递给函数当参数,然后执行,这就需要一点小技巧。
参数问题其实很简单,我们先偷个懒,我们接着要把这个参数数组放到要执行的函数的参数里面去。
1Function.prototype.applyTwo = function(context) {
2 context.fn = this;
3 let args = arguments[1];
4 context.fn(args.join(','));
5 delete context.fn;
6}很简单是不是,那你就错了,数组join方法返回的是啥?
typeof [1,2,3,4].join(',')//string
最后是一个 “1,2,3,4” 的字符串,其实就是一个参数,肯定不行啦。
也许有人会想到用ES6的一些奇淫方法,不过apply是ES3的方法, 我们为了模拟实现一个ES3的方法,要用到ES6的方法,反正面试官也没说不准这样。 但是我们这次用eval方法拼成一个函数,类似于这样: eval('context.fn(' + args +')')
先简单了解一下eval函数吧 定义和用法:
eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
语法:eval(string)
string必需。要计算的字符串,其中含有要计算的 JavaScript 表达式或要执行的语句。 该方法只接受原始字符串作为参数,如果 string 参数不是原始字符串,那么该方法将不作任何改变地返回。 因此请不要为 eval() 函数传递 String 对象来作为参数。
简单来说吧,就是用JavaScript的解析引擎来解析这一堆字符串里面的内容,这么说吧,你可以这么理解,你把eval看成是。
eval('function Test(a,b,c,d){console.log(a,b,c,d)};Test(1,2,3,4)')就是相当于这样:
1<script>
2function Test(a,b,c,d){
3 console.log(a,b,c,d)
4};
5Test(1,2,3,4)
6</script>第二版代码大致如下:
1Function.prototype.applyTwo = function(context) {
2 var args = arguments[1]; //获取传入的数组参数
3 context.fn = this; //假想context对象预先不存在名为fn的属性
4 var fnStr = 'context.fn(';
5 for (var i = 0; i < args.length; i++) {
6 fnStr += i == args.length - 1 ? args[i] : args[i] + ',';
7 }
8 fnStr += ')';//得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
9 eval(fnStr); //还是eval强大
10 delete context.fn; //执行完毕之后删除这个属性
11}
12//测试一下
13var jawil = {
14 name: "jawil",
15 sayHello: function (age) {
16 console.log(this.name,age);
17 }
18};
19
20var lulin = {
21 name: "lulin",
22};
23
24jawil.sayHello.applyTwo(lulin,[24])//lulin 24好像就行了是不是,其实这只是最粗糙的版本,能用,但是不完善,完成了大约百分之六七十了。
1.this参数可以传null或者不传,当为null的时候,视为指向window
demo1:
1var name = 'jawil';
2function sayHello() {
3 console.log(this.name);
4}
5sayHello.apply(null); // 'jawil'demo2:
1var name = 'jawil';
2function sayHello() {
3 console.log(this.name);
4}
5sayHello.apply(); // 'jawil'2.函数是可以有返回值的
1var obj = {
2 name: 'jawil'
3}
4
5function sayHello(age) {
6 return {
7 name: this.name,
8 age: age
9 }
10}
11
12console.log(sayHello.apply(obj,[24]));// {name: "jawil", age: 24}这些都是小问题,想到了,就很好解决。我们来看看此时的第三版apply模拟方法。
1//原生JavaScript封装apply方法,第三版
2Function.prototype.applyThree = function(context) {
3 var context = context || window
4 var args = arguments[1] //获取传入的数组参数
5 context.fn = this //假想context对象预先不存在名为fn的属性
6 if (args == void 0) { //没有传入参数直接执行
7 return context.fn()
8 }
9 var fnStr = 'context.fn('
10 for (var i = 0; i < args.length; i++) {
11 //得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
12 fnStr += i == args.length - 1 ? args[i] : args[i] + ','
13 }
14 fnStr += ')'
15 var returnValue = eval(fnStr) //还是eval强大
16 delete context.fn //执行完毕之后删除这个属性
17 return returnValue
18}其实一开始就埋下了一个隐患,我们看看这段代码:
1Function.prototype.applyThree = function(context) {
2 var context = context || window
3 var args = arguments[1] //获取传入的数组参数
4 context.fn = this //假想context对象预先不存在名为fn的属性
5 ......
6}就是这句话, context.fn = this //假想context对象预先不存在名为fn的属性 ,这就是一开始的隐患, 我们只是假设,但是并不能防止contenx对象一开始就没有这个属性,要想做到完美,就要保证这个context.fn中的fn的唯一性。
于是我自然而然的想到了强大的ES6,这玩意还是好用啊,幸好早就了解并一直在使用ES6,还没有学习过ES6的童鞋赶紧学习一下,没有坏处的。
重新复习下新知识:
基本数据类型有6种:Undefined、Null、布尔值(Boolean)、字符串(String)、数值(Number)、对象(Object)。
ES5对象属性名都是字符串容易造成属性名的冲突。
1var a = { name: 'jawil'};
2a.name = 'lulin';
3//这样就会重写属性ES6引入了一种新的原始数据类型Symbol,表示独一无二的值。
注意,Symbol函数前不能使用new命令,否则会报错。这是因为生成的Symbol是一个原始类型的值,不是对象
Symbol函数可以接受一个字符串作为参数,表示对Symbol实例的描述,主要是为了在控制台显示,或者转为字符串时,比较容易区分。
1// 没有参数的情况
2var s1 = Symbol();
3var s2 = Symbol();
4s1 === s2 // false
5
6// 有参数的情况
7var s1 = Symbol("foo");
8var s2 = Symbol("foo");
9s1 === s2 // false注意:Symbol值不能与其他类型的值进行运算。
作为属性名的Symbol
1var mySymbol = Symbol();
2
3// 第一种写法
4var a = {};
5a[mySymbol] = 'Hello!';
6
7// 第二种写法
8var a = {
9 [mySymbol]: 'Hello!'
10};
11
12// 第三种写法
13var a = {};
14Object.defineProperty(a, mySymbol, { value: 'Hello!' });
15
16// 以上写法都得到同样结果
17a[mySymbol] // "Hello!"注意,Symbol值作为对象属性名时,不能用点运算符。
继续看下面这个例子:
1var a = {};
2var name = Symbol();
3a.name = 'jawil';
4a[name] = 'lulin';
5console.log(a.name,a[name]); //jawil,lulinSymbol值作为属性名时,该属性还是公开属性,不是私有属性。
这个有点类似于java中的protected属性 (protected和private的区别:在类的外部都是不可以访问的,在类内的子类可以继承protected不可以继承private)
但是这里的Symbol在类外部也是可以访问的,只是不会出现在for…in、for…of循环中, 也不会被Object.keys()、Object.getOwnPropertyNames()返回。 但有一个 Object.getOwnPropertySymbols 方法,可以获取指定对象的所有Symbol属性名。
看看第四版的实现demo,想必大家了解上面知识已经猜得到怎么写了,很简单。 直接加个var fn = Symbol()就行了
1//原生JavaScript封装apply方法,第四版
2Function.prototype.applyFour = function(context) {
3 var context = context || window
4 var args = arguments[1] //获取传入的数组参数
5 var fn = Symbol()
6 context[fn] = this //假想context对象预先不存在名为fn的属性
7 if (args == void 0) { //没有传入参数直接执行
8 return context[fn]()
9 }
10 var fnStr = 'context[fn]('
11 for (var i = 0; i < args.length; i++) {
12 //得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
13 fnStr += i == args.length - 1 ? args[i] : args[i] + ','
14 }
15 fnStr += ')'
16 var returnValue = eval(fnStr) //还是eval强大
17 delete context[fn] //执行完毕之后删除这个属性
18 return returnValue
19}呃呃呃额额,慢着,ES3就出现的方法,你用ES6来实现,你好意思么? 你可能会说,不管黑猫白猫,只要能抓住老鼠的猫就是好猫,面试官直说不准用call和apply方法但是没说不准用ES6语法啊。
反正公说公有理婆说婆有理,这里还是不用Symbol方法实现一下,我们知道,ES6其实都是语法糖,ES6能写的, 咋们ES5都能实现,这就导致了babel这类把ES6语法转化成ES5的代码了。
至于babel把Symbol属性转换成啥代码了,我也没去看,有兴趣的可以看一下稍微研究一下,这里我说一下简单的模拟。
ES5 没有 Sybmol,属性名称只可能是一个字符串,如果我们能做到这个字符串不可预料, 那么就基本达到目标。要达到不可预期,一个随机数基本上就解决了。
1//简单模拟Symbol属性
2function jawilSymbol(obj) {
3 var unique_proper = "00" + Math.random();
4 if (obj.hasOwnProperty(unique_proper)) {
5 arguments.callee(obj)//如果obj已经有了这个属性,递归调用,直到没有这个属性
6 } else {
7 return unique_proper;
8 }
9}
10//原生JavaScript封装apply方法,第五版
11Function.prototype.applyFive = function(context) {
12 var context = context || window
13 var args = arguments[1] //获取传入的数组参数
14 var fn = jawilSymbol(context);
15 context[fn] = this //假想context对象预先不存在名为fn的属性
16 if (args == void 0) { //没有传入参数直接执行
17 return context[fn]()
18 }
19 var fnStr = 'context[fn]('
20 for (var i = 0; i < args.length; i++) {
21 //得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
22 fnStr += i == args.length - 1 ? args[i] : args[i] + ','
23 }
24 fnStr += ')'
25 var returnValue = eval(fnStr) //还是eval强大
26 delete context[fn] //执行完毕之后删除这个属性
27 return returnValue
28};
29var obj = {
30 name: 'jawil'
31}
32function sayHello(age) {
33 return {
34 name: this.name,
35 age: age
36 }
37}
38console.log(sayHello.applyFive(obj,[24]));// 完美输出{name: "jawil", age: 24}这个不需要讲了吧,道理都一样,就是参数一样,这里我给出我实现的一种方式,看不懂,自己写一个去。
1//原生JavaScript封装call方法
2Function.prototype.callOne = function(context) {
3 return this.applyFive(([].shift.applyFive(arguments), arguments));
4 //巧妙地运用上面已经实现的applyFive函数
5}看不太明白也不能怪我咯,我就不细讲了,看个demo证明一下,这个写法没问题。
1Function.prototype.applyFive = function(context) {//刚才写的一大串}
2Function.prototype.callOne = function(context) {
3 return this.applyFive(([].shift.applyFive(arguments)), arguments)
4 //巧妙地运用上面已经实现的applyFive函数
5};
6//测试一下
7var obj = {
8 name: 'jawil'
9};
10
11function sayHello(age) {
12 return {
13 name: this.name,
14 age: age
15 }
16}
17console.log(sayHello.callOne(obj,24));// 完美输出{name: "jawil", age: 24}什么是bind函数
如果掌握了上面实现apply的方法,我想理解起来模拟实现bind方法也是轻而易举,原理都差不多,我们还是来看看bind方法的定义。
我们还是简单的看下ECMAScript规范对bind方法的定义,暂时看不懂不要紧,获取几个关键信息就行。
bind() 方法会创建一个新函数,当这个新函数被调用时,它的 this 值是传递给 bind() 的第一个参数, 它的参数是 bind() 的其他参数和其原本的参数, bind返回的绑定函数也能使用new操作符创建对象:这种行为就像把原函数当成构造器。 提供的this值被忽略,同时调用时的参数被提供给模拟函数。。
语法是这样样子的: fun.bind(thisArg[, arg1[, arg2[, ...]]])
是不是似曾相识,这不是call方法的语法一个样子么,,,但它们是一样的吗?
bind方法传递给调用函数的参数可以逐个列出,也可以写在数组中。 bind方法与call、apply最大的不同就是前者返回一个绑定上下文的函数, 而后两者是直接执行了函数。由于这个原因,上面的代码也可以这样写:
1jawil.sayHello.bind(lulin)(24); //hello, i am lulin 24 years old
2jawil.sayHello.bind(lulin)([24]); //hello, i am lulin 24 years oldbind方法还可以这样写 fn.bind(obj, arg1)(arg2).
用一句话总结bind的用法: 该方法创建一个新函数,称为绑定函数,绑定函数会以创建它时传入bind方法的第一个参数作为this, 传入bind方法的第二个以及以后的参数加上绑定函数运行时本身的参数按照顺序作为原函数的参数来调用原函数。
以前解决这个问题的办法通常是缓存this,例如:
1function Person(name){
2 this.nickname = name;
3 this.distractedGreeting = function() {
4 var self = this; // <-- 注意这一行!
5 setTimeout(function(){
6 console.log("Hello, my name is " + self.nickname); // <-- 还有这一行!
7 }, 500);
8 }
9}
10
11var alice = new Person('jawil');
12alice.distractedGreeting();
13// after 500ms logs "Hello, my name is jawil"但是现在有一个更好的办法!您可以使用bind。上面的例子中被更新为:
1function Person(name){
2 this.nickname = name;
3 this.distractedGreeting = function() {
4 setTimeout(function(){
5 console.log("Hello, my name is " + this.nickname);
6 }.bind(this), 500); // <-- this line!
7 }
8}
9
10var alice = new Person('jawil');
11alice.distractedGreeting();
12// after 500ms logs "Hello, my name is jawil"用法总结:
bind() 最简单的用法是创建一个函数,使这个函数不论怎么调用都有同样的 this 值。 JavaScript新手经常犯的一个错误是将一个方法从对象中拿出来,然后再调用,希望方法中的 this 是原来的对象。 (比如在回调中传入这个方法。)如果不做特殊处理的话,一般会丢失原来的对象。 从原来的函数和原来的对象创建一个绑定函数,则能很漂亮地解决这个问题:
1this.x = 9;
2var module = {
3 x: 81,
4 getX: function() { return this.x; }
5};
6
7module.getX(); // 81
8
9var getX = module.getX;
10getX(); // 9, 因为在这个例子中,"this"指向全局对象
11
12// 创建一个'this'绑定到module的函数
13var boundGetX = getX.bind(module);
14boundGetX(); // 81备注:
很不幸,Function.prototype.bind 在IE8及以下的版本中不被支持, 所以如果你没有一个备用方案的话,可能在运行时会出现问题。 bind 函数在 ECMA-262 第五版才被加入;它可能无法在所有浏览器上运行。 你可以部份地在脚本开头加入以下代码,就能使它运作,让不支持的浏览器也能使用 bind() 功能。
了解了以上内容,我们来实现一个初级的bind函数Polyfill:
1Function.prototype.bind = function (context) {
2 var me = this;
3 var argsArray = Array.prototype.slice.callOne(arguments);
4 return function () {
5 return me.applyFive(context, argsArray.slice(1))
6 }
7}简单解读: 基本原理是使用apply进行模拟。函数体内的this,就是需要绑定this的实例函数,或者说是原函数。 最后我们使用apply来进行参数(context)绑定,并返回。
同时,将第一个参数(context)以外的其他参数,作为提供给原函数的预设参数,这也是基本的“颗粒化(curring)”基础。
进行兼容处理,就是锦上添花了。
1Function.prototype.bind = Function.prototype.bind || function (context) {
2 ...
3}对于函数的柯里化不太了解的童鞋,可以先尝试读读这篇文章:前端基础进阶(八):深入详解函数的柯里化。
上述的实现方式中,我们返回的参数列表里包含:atgsArray.slice(1),他的问题在于存在预置参数功能丢失的现象。
想象我们返回的绑定函数中,如果想实现预设传参(就像bind所实现的那样),就面临尴尬的局面。真正实现颗粒化的“完美方式”是:
1Function.prototype.bind = Function.prototype.bind || function (context) {
2 var me = this;
3 var args = Array.prototype.slice.callOne(arguments, 1);
4 return function () {
5 var innerArgs = Array.prototype.slice.callOne(arguments);
6 var finalArgs = args.concat(innerArgs);
7 return me.applyFive(context, finalArgs);
8 }
9} 1Function.prototype.bind = Function.prototype.bind || function (context) {
2 var me = this;
3 var args = Array.prototype.slice.callOne(arguments, 1);
4 var F = function () {};
5 F.prototype = this.prototype;
6 var bound = function () {
7 var innerArgs = Array.prototype.slice.callOne(arguments);
8 var finalArgs = args.concat(innerArgs);
9 return me.apply(this instanceof F ? this : context || this, finalArgs);
10 }
11 bound.prototype = new F();
12 return bound;
13}我们需要调用bind方法的一定要是一个函数,所以可以在函数体内做一个判断:
1if (typeof this !== "function") {
2 throw new TypeError("Function.prototype.bind - what is trying to be bound is not callable");
3}做到所有这一切,基本算是完成了。其实MDN上有个自己实现的polyfill,就是如此实现的。 另外,《JavaScript Web Application》一书中对bind()的实现,也是如此。
1//简单模拟Symbol属性
2function jawilSymbol(obj) {
3 var unique_proper = "00" + Math.random();
4 if (obj.hasOwnProperty(unique_proper)) {
5 arguments.callee(obj)//如果obj已经有了这个属性,递归调用,直到没有这个属性
6 } else {
7 return unique_proper;
8 }
9}
10//原生JavaScript封装apply方法,第五版
11Function.prototype.applyFive = function(context) {
12 var context = context || window
13 var args = arguments[1] //获取传入的数组参数
14 var fn = jawilSymbol(context);
15 context[fn] = this //假想context对象预先不存在名为fn的属性
16 if (args == void 0) { //没有传入参数直接执行
17 return context[fn]()
18 }
19 var fnStr = 'context[fn]('
20 for (var i = 0; i < args.length; i++) {
21 //得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
22 fnStr += i == args.length - 1 ? args[i] : args[i] + ','
23 }
24 fnStr += ')'
25 var returnValue = eval(fnStr) //还是eval强大
26 delete context[fn] //执行完毕之后删除这个属性
27 return returnValue
28}
29//简单模拟call函数
30Function.prototype.callOne = function(context) {
31 return this.applyFive(([].shift.applyFive(arguments)), arguments)
32 //巧妙地运用上面已经实现的applyFive函数
33}
34
35//简单模拟bind函数
36Function.prototype.bind = Function.prototype.bind || function (context) {
37 var me = this;
38 var args = Array.prototype.slice.callOne(arguments, 1);
39 var F = function () {};
40 F.prototype = this.prototype;
41 var bound = function () {
42 var innerArgs = Array.prototype.slice.callOne(arguments);
43 var finalArgs = args.concat(innerArgs);
44 return me.applyFive(this instanceof F ? this : context || this, finalArgs);
45 }
46 bound.prototype = new F();
47 return bound;
48}
49var obj = {
50 name: 'jawil'
51}
52
53function sayHello(age) {
54 return {
55 name: this.name,
56 age: age
57 }
58}
59
60console.log(sayHello.bind(obj,24)());// 完美输出{name: "jawil", age: 24}85.知道 JS 中的尾调用吗,如何做尾调优化?【JavaScript】
es6 javascript 尾调用
深入理解JavaScript中的尾调用(Tail Call)
尾调用是函数式编程里比较重要的一个概念,尾调用的概念非常简单, 一句话就能说清楚,它的意思是在函数的执行过程中,如果最后一个动作是一个函数的调用, 即这个调用的返回值被当前函数直接返回,则称为尾调用。
1function f(x){
2 return g(x);
3}上面代码中,函数 f 的最后一步是调用函数 g ,这就叫尾调用。以下三种情况,都不属于尾调用。
1// 情况一
2function f(x){
3 let y = g(x);
4 return y;
5}
6// 情况二
7function f(x){
8 return g(x) + 1;
9}
10// 情况三
11function f(x){
12 g(x);
13}上面代码中,情况一是调用函数 g 之后,还有赋值操作,所以不属于尾调用,即使语义完全一样。情况二也属于调用后还有操作,即使写在一行内。情况三等同于下面的代码。
1function f(x){
2 g(x);
3 return undefined;
4}尾调用不一定出现在函数尾部,只要是最后一步操作即可。
1function f(x) {
2 if (x > 0) {
3 return m(x)
4 }
5 return n(x);
6}上面代码中,函数 m 和 n 都属于尾调用,因为它们都是函数 f 的最后一步操作。
尾调用之所以与其他调用不同,就在于它的特殊的调用位置。
我们知道,函数调用会在内存形成一个 “ 调用记录 ” ,又称 “ 调用帧 ” ( call frame ),保存调用位置和内部变量等信息。 如果在函数 A 的内部调用函数 B ,那么在 A 的调用帧上方,还会形成一个 B 的调用帧。 等到 B 运行结束,将结果返回到 A , B 的调用帧才会消失。 如果函数 B 内部还调用函数 C ,那就还有一个 C 的调用帧,以此类推。 所有的调用帧,就形成一个 “ 调用栈 ” ( call stack )。
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧, 因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
1function f() {
2 let m = 1;
3 let n = 2;
4 return g(m + n);
5}
6f();
7// 等同于
8function f() {
9 return g(3);
10}
11f();
12// 等同于
13g(3);上面代码中,如果函数 g 不是尾调用,函数 f 就需要保存内部变量 m 和 n 的值、 g 的调用位置等信息。 但由于调用 g 之后,函数 f 就结束了,所以执行到最后一步,完全可以删除 f(x) 的调用帧,只保留 g(3) 的调用帧。
这就叫做 “ 尾调用优化 ” ( Tail call optimization ),即只保留内层函数的调用帧。 如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存。这就是 “ 尾调用优化 ” 的意义。
注意,只有不再用到外层函数的内部变量,内层函数的调用帧才会取代外层函数的调用帧,否则就无法进行 “ 尾调用优化 ” 。
1function addOne(a){
2 var one = 1;
3 function inner(b){
4 return b + one;
5 }
6 return inner(a);
7}上面的函数不会进行尾调用优化,因为内层函数inner用到了外层函数addOne的内部变量one。
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。 递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生 “ 栈溢出 ” 错误( stack overflow )。 但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生 “ 栈溢出 ” 错误。
1function factorial(n) {
2 if (n === 1) return 1;
3 return n * factorial(n - 1);
4}
5factorial(5) // 120上面代码是一个阶乘函数,计算 n 的阶乘,最多需要保存 n 个调用记录,复杂度 O(n) 。
如果改写成尾递归,只保留一个调用记录,复杂度 O(1) 。
1function factorial(n, total) {
2 if (n === 1) return total;
3 return factorial(n - 1, n * total);
4}
5factorial(5, 1) // 120还有一个比较著名的例子,就是计算 fibonacci(斐波那契) 数列,也能充分说明尾递归优化的重要性 如果是非尾递归的 fibonacci 递归方法
1function Fibonacci (n) {
2 if ( n <= 1 ) {return 1};
3 return Fibonacci(n - 1) + Fibonacci(n - 2);
4}
5Fibonacci(10); // 89
6// Fibonacci(100)
7// Fibonacci(500)
8// 堆栈溢出了如果我们使用尾递归优化过的 fibonacci 递归算法
1function Fibonacci2 (n , ac1 = 1 , ac2 = 1) {
2 if( n <= 1 ) {return ac2};
3 return Fibonacci2 (n - 1, ac2, ac1 + ac2);
4}
5Fibonacci2(100) // 573147844013817200000
6Fibonacci2(1000) // 7.0330367711422765e+208
7Fibonacci2(10000) // Infinity由此可见, “ 尾调用优化 ” 对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。 ES6 也是如此,第一次明确规定,所有 ECMAScript 的实现,都必须部署 “ 尾调用优化 ” 。这就是说,在 ES6 中,只要使用尾递归,就不会发生栈溢出,相对节省内存。
尾递归的实现,往往需要改写递归函数,确保最后一步只调用自身。做到这一点的方法,就是把所有用到的内部变量改写成函数的参数。 比如上面的例子,阶乘函数 factorial 需要用到一个中间变量 total ,那就把这个中间变量改写成函数的参数。 这样做的缺点就是不太直观,第一眼很难看出来,为什么计算 5 的阶乘,需要传入两个参数 5 和 1 ?
两个方法可以解决这个问题。 方法一是在尾递归函数之外,再提供一个正常形式的函数。
1function tailFactorial(n, total) {
2 if (n === 1) return total;
3 return tailFactorial(n - 1, n * total);
4}
5function factorial(n) {
6 return tailFactorial(n, 1);
7}
8factorial(5) // 120上面代码通过一个正常形式的阶乘函数 factorial ,调用尾递归函数 tailFactorial ,看起来就正常多了。
函数式编程有一个概念,叫做柯里化( currying ),意思是将多参数的函数转换成单参数的形式。这里也可以使用柯里化。
1function currying(fn, n) {
2 return function (m) {
3 return fn.call(this, m, n);
4 };
5}
6function tailFactorial(n, total) {
7 if (n === 1) return total;
8 return tailFactorial(n - 1, n * total);
9}
10const factorial = currying(tailFactorial, 1);
11factorial(5) // 120上面代码通过柯里化,将尾递归函数 tailFactorial 变为只接受 1 个参数的 factorial 。
第二种方法就简单多了,就是采用 ES6 的函数默认值。
1function factorial(n, total = 1) {
2 if (n === 1) return total;
3 return factorial(n - 1, n * total);
4}
5factorial(5) // 120上面代码中,参数 total 有默认值 1 ,所以调用时不用提供这个值。
总结一下,递归本质上是一种循环操作。纯粹的函数式编程语言没有循环操作命令,所有的循环都用递归实现,这就是为什么尾递归对这些语言极其重要。 对于其他支持 “ 尾调用优化 ” 的语言(比如 Lua , ES6 ),只需要知道循环可以用递归代替,而一旦使用递归,就最好使用尾递归。
ES6 的尾调用优化只在严格模式下开启,正常模式是无效的。
这是因为在正常模式下,函数内部有两个变量,可以跟踪函数的调用栈。
func.arguments:返回调用时函数的参数。
func.caller:返回调用当前函数的那个函数。
尾调用优化发生时,函数的调用栈会改写,因此上面两个变量就会失真。严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效。
1function restricted() {
2 "use strict";
3 restricted.caller; // 报错
4 restricted.arguments; // 报错
5}
6restricted();尾递归优化只在严格模式下生效,那么正常模式下,或者那些不支持该功能的环境中,有没有办法也使用尾递归优化呢?回答是可以的,就是自己实现尾递归优化。
它的原理非常简单。尾递归之所以需要优化,原因是调用栈太多,造成溢出,那么只要减少调用栈,就不会溢出。 怎么做可以减少调用栈呢?就是采用 “ 循环 ” 换掉 “ 递归 ” 。
下面是一个正常的递归函数。
1function sum(x, y) {
2 if (y > 0) {
3 return sum(x + 1, y - 1);
4 } else {
5 return x;
6 }
7}
8sum(1, 100000)
9// Uncaught RangeError: Maximum call stack size exceeded(…)上面代码中,sum是一个递归函数,参数x是需要累加的值,参数y控制递归次数。 一旦指定sum递归 100000 次,就会报错,提示超出调用栈的最大次数。 蹦床函数(trampoline) 可以将递归执行转为循环执行。
1function trampoline(f) {
2 while (f && f instanceof Function) {
3 f = f();
4 }
5 return f;
6}上面就是蹦床函数的一个实现,它接受一个函数f作为参数。只要f执行后返回一个函数,就继续执行。 注意,这里是返回一个函数,然后执行该函数,而不是函数里面调用函数,这样就避免了递归执行,从而就消除了调用栈过大的问题。
然后,要做的就是将原来的递归函数,改写为每一步返回另一个函数。
1function sum(x, y) {
2 if (y > 0) {
3 return sum.bind(null, x + 1, y - 1);
4 } else {
5 return x;
6 }
7}上面代码中,sum函数的每次执行,都会返回自身的另一个版本。 现在,使用蹦床函数执行sum,就不会发生调用栈溢出。
1trampoline(sum(1, 100000))
2// 100001
3//蹦床函数并不是真正的尾递归优化,下面的实现才是。
4function tco(f) {
5 var value;
6 var active = false;
7 var accumulated = [];
8 return function accumulator() {
9 accumulated.push(arguments);
10 if (!active) {
11 active = true;
12 while (accumulated.length) {
13 value = f.apply(this, accumulated.shift());
14 }
15 active = false;
16 return value;
17 }
18 };
19}
20var sum = tco(function(x, y) {
21 if (y > 0) {
22 return sum(x + 1, y - 1)
23 }else {
24 return x
25 }
26});
27sum(1, 100000)
28// 100001上面代码中,tco函数是尾递归优化的实现,它的奥妙就在于状态变量active。 默认情况下,这个变量是不激活的。一旦进入尾递归优化的过程,这个变量就激活了。 然后,每一轮递归sum返回的都是undefined,所以就避免了递归执行; 而accumulated数组存放每一轮sum执行的参数,总是有值的,这就保证了accumulator函数内部的while循环总是会执行。 这样就很巧妙地将 “ 递归 ” 改成了 “ 循环 ” ,而后一轮的参数会取代前一轮的参数,保证了调用栈只有一层。
文档转自:https://blog.csdn.net/CystalVon/article/details/78428036
Vue.js与React.js从某些反面来说很相似,通过两个框架的学习,有时候对一些用法会有一点思考,为加深学习的思索,特翻阅了两个文档,从以下各方面进行了对比,加深了对这两个框架的认知。
- vue是双向绑定, Vue.js 最核心的功能有两个,一是响应式的数据绑定系统,二是组件系统。所谓双向绑定,指的是vue实例中的data与其渲染的DOM元素的内容保持一致,无论谁被改变,另一方会相应的更新为相同的数据。这是通过设置属性访问器实现的。
- 在vue中,与数据绑定有关的有 插值表达式、指令系统、*Class和Style、事件处理器和表单空间、ajax请求和计算属性
插值和指令又称为模板语法
. 数据绑定最常见的形式就是使用“Mustache”语法 (双大括号) 的文本插值
. Mustache 语法不能作用在 HTML 特性上,遇到这种情况应该使用 v-bind 指令
-
vue中的指令很方便,指令 (Directives) 是带有 v- 前缀的特殊属性。指令属性的值预期是单个 JavaScript 表达式 (v-for 是例外情况,稍后我们再讨论)。指令的职责是,当表达式的值改变时,将其产生的连带影响,响应式地作用于 DOM。
-
vue中的12个指令:
v-bind,v-once,v-model,v-text,v-html,v-on,v-if,v-else,v-show,v-for,v-pre,v-clock -
数据绑定的一个常见需求是操作元素的 class 列表和它的内联样式。因为它们都是属性 ,我们可以用v-bind 处理它们:只需要计算出表达式最终的字符串。不过,字符串拼接麻烦又易错。因此,在 v-bind 用于 class 和 style 时,Vue.js 专门增强了它。表达式的结果类型除了字符串之外,还可以是对象或数组。
-
对象语法
- 我们可以传给 v-bind:class 一个对象,以动态地切换 class
-
数组语法
- 我们可以把一个数组传给 v-bind:class,以应用一个 class 列表:
1<div v-bind:class="[activeClass, errorClass]"></div>
21-
v-if条件渲染一组数
-
我们用 v-for 指令根据一组数组的选项列表进行渲染。v-for 指令需要使用 item in items 形式的特殊语法,items 是源数据数组并且 item 是数组元素迭代的别名。
-
通过v-on给元素注册事件
-
使用 v-on 有几个好处:
- 扫一眼 HTML 模板便能轻松定位在 JavaScript 代码里对应的方法。
- 因为你无须在 JavaScript 里手动绑定事件,你的 ViewModel 代码可以是非常纯粹的逻辑,和 DOM 完全解耦,更易于测试。
- 当一个 ViewModel 被销毁时,所有的事件处理器都会自动被删除。你无须担心如何自己清理它们。
-
v-model在表单控件元素上创建双向数据绑定
-
它会根据控件类型自动选取正确的方法来更新元素。
-
在Vue中引入了计算属性来处理模板中放入太多的逻辑会让模板过重且难以维护的问题,这样不但解决了上面的问题,而且也同时让模板和业务逻辑更好的分离。
-
简单来说,假如data里面有属性a=1,然后你需要一个变量跟着a变化,例如b=a+1,那么就需要用到计算属性,Vue实例的computed属性中,设置b为其属性,其表现为一个函数,返回值是b的值。
-
Vue 的依赖追踪是【原理上不支持双向绑定,v-model 只是通过监听 DOM 事件实现的语法糖】
-
vue的依赖追踪是通过 Object.defineProperty 把data对象的属性全部转为 getter/setter来实现的;当改变数据的某个属性值时,会触发set函数,获取该属性值的时候会触发get函数,通过这个特性来实现改变数据时改变视图;也就是说只有当数据改变时才会触发视图的改变,反过来在操作视图时,只能通过DOM事件来改变数据,再由此来改变视图,以此来实现双向绑定
-
双向绑定是在同一个组件内,将数据和视图绑定起来,和父子组件之间的通信并无什么关联;
-
组件之间的通信采用单向数据流是为了组件间更好的解耦,在开发中可能有多个子组件依赖于父组件的某个数据,假如子组件可以修改父组件数据的话,一个子组件变化会引发所有依赖这个数据的子组件发生变化,所以vue不推荐子组件修改父组件的数据,直接修改props会抛出警告
-
react是单向数据流
-
react中通过将state(Model层)与View层数据进行双向绑定达数据的实时更新变化,具体来说就是在View层直接写JS代码Model层中的数据拿过来渲染,一旦像表单操作、触发事件、ajax请求等触发数据变化,则进行双同步
-
React 元素的事件处理和 DOM元素的很相似。但是有一点语法上的不同:
-
React事件绑定属性的命名采用驼峰式写法,而不是小写。
-
如果采用 JSX 的语法你需要传入一个函数作为事件处理函数,而不是一个字符串(DOM元素的写法)
-
在 React 中另一个不同是你不能使用返回 false 的方式阻止默认行为。你必须明确的使用 preventDefault。
-
当你使用 ES6 class 语法来定义一个组件的时候,事件处理器会成为类的一个方法。一般需要显式的绑定this,例如
this.handleClick = this.handleClick.bind(this); -
你必须谨慎对待 JSX 回调函数中的 this,类的方法默认是不会绑定 this 的。如果你忘记绑定 this.handleClick 并把它传入 onClick, 当你调用这个函数的时候 this 的值会是 undefined。
-
-
React 中的条件渲染和 JavaScript 中的一致,使用 JavaScript 操作符 if 或条件运算符来创建表示当前状态的元素,然后让 React 根据它们来更新 UI。
-
你可以通过用花括号包裹代码在 JSX 中嵌入任何表达式 ,也包括 JavaScript 的逻辑与 &&,它可以方便地条件渲染一个元素。之所以能这样做,是因为在 JavaScript 中,true && expression 总是返回 expression,而 false && expression 总是返回 false。因此,如果条件是 true,&& 右侧的元素就会被渲染,如果是 false,React 会忽略并跳过它。
-
条件渲染的另一种方法是使用 JavaScript 的条件运算符 condition ? true : false。
-
你可以通过使用{}在JSX内构建一个元素集合,使用Javascript中的map()方法循遍历数组
-
Keys可以在DOM中的某些元素被增加或删除的时候帮助React识别哪些元素发生了变化。因此你应当给数组中的每一个元素赋予一个确定的标识。一个元素的key最好是这个元素在列表中拥有的一个独一无二的字符串。通常,我们使用来自数据的id作为元素的key。
-
HTML表单元素与React中的其他DOM元素有所不同,因为表单元素生来就保留一些内部状态。
-
当用户提交表单时,HTML的默认行为会使这个表单会跳转到一个新页面。在React中亦是如此。但大多数情况下,我们都会构造一个处理提交表单并可访问用户输入表单数据的函数。实现这一点的标准方法是使用一种称为“受控组件”的技术。其值由React控制的输入表单元素称为“受控组件”。
this.setState({value: event.target.value}); -
当你有处理多个受控的input元素时,你可以通过给每个元素添加一个name属性,来让处理函数根据 event.target.name的值来选择做什么。
-
在React中,状态分享是通过将state数据提升至离需要这些数据的组件最近的父组件来完成的。这就是所谓的状态提升。
this.props.xxx -
在React应用中,对应任何可变数据理应只有一个单一“数据源”。通常,状态都是首先添加在需要渲染数据的组件中。此时,如果另一个组件也需要这些数据,你可以将数据提升至离它们最近的父组件中。你应该在应用中保持 自上而下的数据流,而不是尝试在不同组件中同步状态。
-
React是单向数据流,数据主要从父节点传递到子节点(通过props)。如果顶层(父级)的某个props改变了,React会重渲染所有的子节点。
-
react中实现组件有两种实现方式,一种是createClass方法,另一种是通过ES2015的思想类继承React.Component来实现
-
在React应用中,按钮、表单、对话框、整个屏幕的内容等,这些通常都被表示为组件。
-
React推崇的是函数式编程和单向数据流:给定原始界面(或数据),施加一个变化,就能推导出另外一个状态(界面或者数据的更新)
-
组件可以将UI切分成一些的独立的、可复用的部件,这样你就只需专注于构建每一个单独的部件。组件从概念上看就像是函数,它可以接收任意的输入值(称之为“props”),并返回一个需要在页面上展示的React元素。
1. Props的只读性 -
无论是使用函数或是类来声明一个组件,它决不能修改它自己的props。
-
所有的React组件必须像纯函数那样使用它们的props。
props与State的区别
. props是property的缩写,可以理解为HTML标签的attribute。不可以使用this.props直接修改props,因为props是只读的,props是用于整个组件树中传递数据和配置。在当前组件访问props,使用this.props。
. props是一个组件的设置参数,可以在父控件中选择性设置。父组件对子控件的props进行赋值,并且props的值不可改变。一个子控件自身不能改变自己的 props。
. state:当一个组件 mounts的时候,state如果设置有默认值的会被使用,并且state可能时刻的被改变。一个子控件自身可以管理自己的state,但是需要注意的是,无法管理其子控件的state。所以可以认为,state是子控件自身私有的。
. 每个组件都有属于自己的state,state和props的区别在于前者(state)只存在于组件内部,只能从当前组件调用this.setState修改state值(不可以直接修改this.state!)。
. props是一个父组件传递给子组件的数据流,可以一直的被传递到子孙组件中。然而 state代表的是子组件自身的内部状态。从语义上讲,改变组件的状态,可能会导致dom结构的改变或者重新渲染。而props是父组件传递的参数,所以可以被用于初始化渲染和改变组件自身的状态,虽然大多数时候组件的状态是又外部事件触发改变的。我们需要知道的是,无论是state改变,还是父组件传递的 props改变,render方法都可能会被执行。
. 一般我们更新子组件都是通过改变state值,更新新子组件的props值从而达到更新。
-
父子组件数通信
- 父与子之间通props属性进行传递
- 子与父之间,父组件定义事件,子组件触发父组件中的事件时,通过实参的形式来改变父组件中的数据来通信
即:
. . 父组件更新组件状态 —–props—–> 子组件更新
. . 子组件更新父组件状态 —–需要父组件传递回调函数—–> 子组件调用触发
- 非父子组件之间的通信,嵌套不深的非父子组件可以使共同父组件,触发事件函数传形参的方式来实现
兄弟组件:
(1) 按照React单向数据流方式,我们需要借助父组件进行传递,通过父组件回调函数改变兄弟组件的props。
. 其实这种实现方式与子组件更新父组件状态的方式是大同小异的。
(2) 当组件层次很深的时候,在这里,React官方给我们提供了一种上下文方式,可以让子组件直接访问祖先的数据或函数,无需从祖先组件一层层地传递数据到子组件中。
1construtor() //创建组件
2componentWillMount() //组件挂载之前
3componentDidMount() // 组件挂载之后
4componentWillReceiveProps() // 父组件发生render的时候子组件调用该函数
5shouldComponentUpdate() // 组件挂载之后每次调用setState后都会调用该函数判断是否需要重新渲染组件,默认返回true
6componentDidUpdate() // 更新
7render() //渲染,react中的核心函数
8componentWillUnmount() //组件被卸载的时候调用,一般在componentDidMount注册的事件需要在这里删除
9
10123456789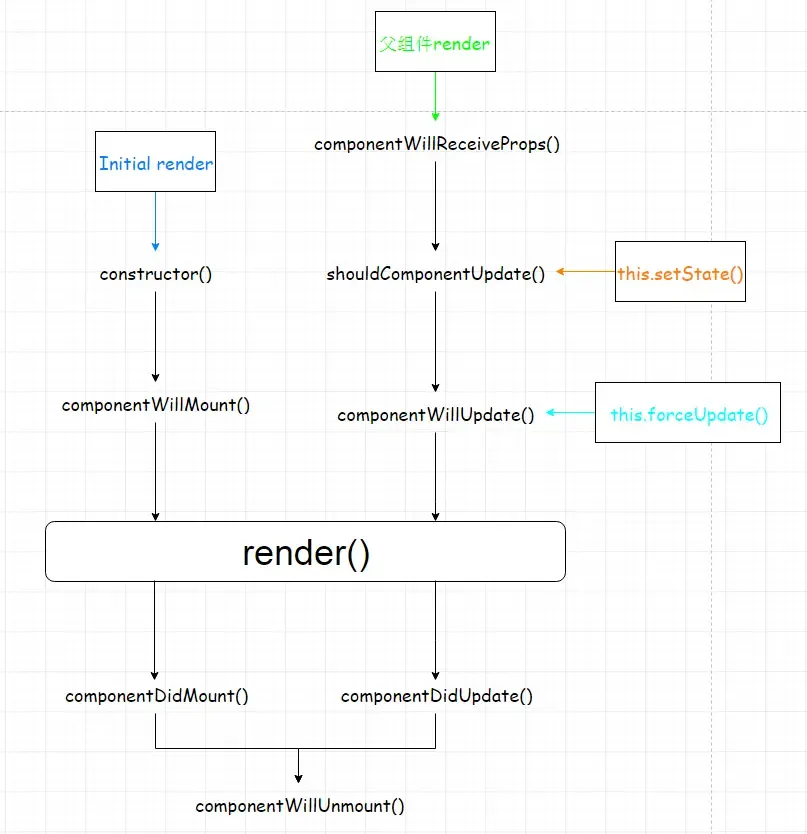
-
组件系统是 Vue 的另一个重要概念,因为它是一种抽象,允许我们使用小型、独立和通常可复用的组件构建大型应用。
-
在 Vue 里,一个组件本质上是一个拥有预定义选项的一个 Vue 实例
-
在一个大型应用中,有必要将整个应用程序划分为组件,以使开发可管理。
-
组件(component)是 Vue 最强大的功能之一。组件可以帮助你扩展基本的 HTML 元素,以封装可重用代码。在较高层面上,组件是 Vue 编译器附加行为后的自定义元素。在某些情况下,组件也可以是原生 HTML 元素的形式,以特定的 is 特性扩展。
-
组件中,data必须是一个函数
-
组件可以扩展 HTML 元素,封装可重用的代码。在较高层面上,组件是自定义元素,Vue.js 的编译器为它添加特殊功能。在有些情况下,组件也可以是原生 HTML 元素的形式,以 is 特性扩展。
-
当一个 Vue 实例被创建时,它向 Vue 的响应式系统中加入了其 data 对象中能找到的所有的属性。当这些属性的值发生改变时,视图将会产生“响应”,即匹配更新为新的值。
-
当这些数据改变时,视图会进行重渲染。值得注意的是只有当实例被创建时 data 中存在的属性是响应式的。
-
每个 Vue 实例在被创建之前都要经过一系列的初始化过程。例如需要设置数据监听、编译模板、挂载实例到 DOM、在数据变化时更新 DOM 等。同时在这个过程中也会运行一些叫做生命周期钩子的函数,给予用户机会在一些特定的场景下添加他们自己的代码。
-
比如 created 钩子可以用来在一个实例被创建之后执行代码,也有一些其它的钩子,在实例生命周期的不同场景下调用,如 mounted、updated、destroyed。钩子的 this 指向调用它的 Vue 实例。
-
生命周期图示:
-
Vue默认的是单向数据流,这是Vue直接提出来说明的,父组件默认可以向子组件传递数据,但是子组件向父组件传递数据就需要额外设置了。
-
Vue 也支持双向绑定,默认为单向绑定,数据从父组件单向传给子组件。在大型应用中使用单向绑定让数据流易于理解。
-
父子组件之间的数据通信是通过Prop和自定义事件实现的,而非父子组件可以使用订阅/发布模式实现(类似于Angualr中的非父子指令之间的通信),再复杂一点也是建议使用状态管理(vuex)。
-
在 Vue 中,父子组件之间的关系可以概述为:props 向下,events 向上。父组件通过 props 向下传递数据给子组件,子组件通过 events 发送消息给父组件。
1.父向子
. 每个组件实例都有自己的孤立隔离作用域。也就是说,不能(也不应该)直接在子组件模板中引用父组件数据。要想在子组件模板中引用父组件数据,可以使用 props 将数据向下传递到子组件。
. 每个 prop 属性,都可以控制是否从父组件的自定义属性中接收数据。子组件需要使用 props 选项显式声明 props,以便它可以从父组件接收到期望的数据。
. 动态Props,类似于将一个普通属性绑定到一个表达式,我们还可以使用 v-bind 将 props 属性动态地绑定到父组件中的数据。无论父组件何时更新数据,都可以将数据向下流入到子组件中
2.子向父
. 使用自定义事件
. 每个 Vue 实例都接入了一个事件接口(events interface),也就是说,这些 Vue 实例可以做到:
. 使用 on(eventName)监听一个事件−使用” role=“presentation” style=“position: relative;“>on(eventName)监听一个事件−使用on(eventName)监听一个事件−使用emit(eventName) 触发一个事件
3. 非父子组件通信
. 可以使用一个空的 Vue 实例作为一个事件总线中心(central event bus),用emit触发事件,” role=“presentation” style=“position: relative;“>emit触发事件,emit触发事件,on监听事件
单向数据流示意图:
-
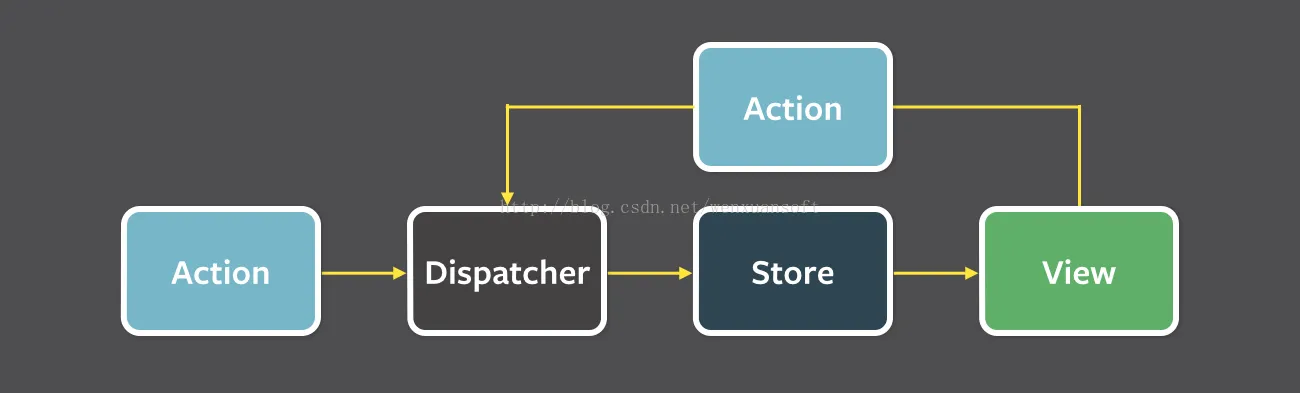
Redux 是 React 生态环境中最流行的 Flux 实现。Redux 事实上无法感知视图层,所以它能够轻松的通过一些简单绑定和 Vue 一起使用。
-
创建actions
- 定义动作,事件触发需要用dispatcher来调用
- 行为,如增加操作、删除操作、更新操作,就是一堆函数。
-
创建store
- store中包含应用的状态和逻辑,用来管理应用中不同的状态和逻辑,相当于Model层
-
创建dispatcher
- 在dispatcher中通过register来给每个action注对应的的store中的方法
-
在view层调用action中的方法
- 就是各类component
-
-
vuex借鉴了 Flux、Redux、和 The Elm Architecture。与其他模式不同的是,Vuex 是专门为 Vue.js 设计的状态管理库,以利用 Vue.js 的细粒度数据响应机制来进行高效的状态更新。这使得它能够更好地和 Vue 进行整合,同时提供简洁的 API 和改善过的开发体验。
-
组件不允许直接修改属于 store 实例的 state,而应执行 action 来分发 (dispatch) 事件通知 store 去改变,我们最终达成了 Flux 架构。这样约定的好处是,我们能够记录所有 store 中发生的 state 改变,同时实现能做到记录变更 (mutation)、保存状态快照、历史回滚/时光旅行的先进的调试工具。
-
每一个 Vuex 应用的核心就是 store(仓库)。“store”基本上就是一个容器,它包含着你的应用中大部分的状态
-
Vuex 和单纯的全局对象有以下两点不同:
-
Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
-
你不能直接改变 store 中的状态。改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样使得我们可以方便地跟踪每一个状态的变化,从而让我们能够实现一些工具帮助我们更好地了解我们的应用。
-
State
-
-
Vuex 使用单一状态树——是的,用一个对象就包含了全部的应用层级状态。至此它便作为一个“唯一数据源 (SSOT)”而存在。这也意味着,每个应用将仅仅包含一个 store 实例。单一状态树让我们能够直接地定位任一特定的状态片段,在调试的过程中也能轻易地取得整个当前应用状态的快照。这也意味着,每个应用将仅仅包含一个 store 实例。
- Getters
-
从state中获取状态值,有时候我们需要从 store 中的 state 中派生出一些状态,例如对列表进行过滤并计数。
-
Mutation
- 更改 Vuex 的 store 中的状态的唯一方法是提交 mutation。Vuex 中的 mutation 非常类似于事件:每个 mutation 都有一个字符串的 事件类型 (type) 和 一个 回调函数 (handler)。这个回调函数就是我们实际进行状态更改的地方,并且它会接受 state 作为第一个参数。
- 你不能直接调用一个 mutation handler。这个选项更像是事件注册:“当触发一个类型为 increment 的 mutation 时,调用此函数。”要唤醒一个 mutation handler,你需要以相应的 type 调用 store.commit 方法
-
Action
-
Action 类似于 mutation,不同在于:
-
Action 提交的是 mutation,而不是直接变更状态。
-
Action 可以包含任意异步操作。
-
dispatch分发action
-
-
Module
-
-
由于使用单一状态树,应用的所有状态会集中到一个比较大的对象。当应用变得非常复杂时,store 对象就有可能变得相当臃肿。
-
Vuex 允许我们将 store 分割成模块(module)。每个模块拥有自己的 state、mutation、action、getter、甚至是嵌套子模块——从上至下进行同样方式的分割

-
两者的路由很相似,都是利用了组件化思想
-
在路由库的问题上,React 选择把问题交给社区维护,因此创建了一个更分散的生态系统。但相对的,React 的生态系统相比 Vue 更加繁荣。
-
react中,需要引入react-router库,
使用时,路由器Router就是React的一个组件。 -
Router组件本身只是一个容器,真正的路由要通过Route组件定义。
-
Route组件定义了URL路径与组件的对应关系。你可以同时使用多个Route组件。
1<Router history={hashHistory}>
2 <Route path="/" component={App}/>
3 <Route path="/repos" component={Repos}/>
4 <Route path="/about" component={About}/>
5</Router>
612345-
Vue 的路由库和状态管理库都是由官方维护支持且与核心库同步更新的。
-
使用 Vue.js ,我们已经可以通过组合组件来组成应用程序,当你要把 vue-router 添加进来,我们需要做的是,将组件(components)映射到路由(routes),然后告诉 vue-router 在哪里渲染它们。
- HTML中:
1<div id="app">
2 <h1>Hello App!</h1>
3 <p>
4 <!-- 使用 router-link 组件来导航. -->
5 <!-- 通过传入 `to` 属性指定链接. -->
6 <!-- <router-link> 默认会被渲染成一个 `<a>` 标签 -->
7 <router-link to="/foo">Go to Foo</router-link>
8 <router-link to="/bar">Go to Bar</router-link>
9 </p>
10 <!-- 路由出口 -->
11 <!-- 路由匹配到的组件将渲染在这里 -->
12 <router-view></router-view>
13</div>
1412345678910111213-
在操作界面时,要尽量减少对DOM的操作,Vue 和 React 都使用虚拟DOM来实现,并且两者工作一样好。
-
尽量减少除DOM操作以外的其他操作。(vue和react的不同)
-
React 的渲染建立在 Virtual DOM 上——一种在内存中描述 DOM 树状态的数据结构。当状态发生变化时,React 重新渲染 Virtual DOM,比较计算之后给真实 DOM 打补丁。
-
Virtual DOM 提供了函数式的方法描述视图,它不使用数据观察机制,每次更新都会重新渲染整个应用,因此从定义上保证了视图与数据的同步。它也开辟了 JavaScript 同构应用的可能性。
-
在超大量数据的首屏渲染速度上,React 有一定优势,因为 Vue 的渲染机制启动时候要做的工作比较多,而且 React 支持服务端渲染。
-
元素是构成 React 应用的最小单位。元素用来描述你在屏幕上看到的内容,与浏览器的 DOM 元素不同,React 当中的元素事实上是普通的对象,React DOM 可以确保 浏览器 DOM 的数据内容与 React 元素保持一致。
-
我们用React 开发应用时一般只会定义一个根节点。但如果你是在一个已有的项目当中引入 React 的话,你可能会需要在不同的部分单独定义 React 根节点。我们将 元素传入一个名为 ReactDOM.render() 的方法来将其渲染到页面上,页面上就会显示该元素。
组件渲染
. 当React遇到的元素是用户自定义的组件,它会将JSX属性作为单个对象传递给该组件,这个对象称之为“props”。
-
Vue 通过建立一个虚拟 DOM 对真实 DOM 发生的变化保持追踪。
-
vue渲染的过程如下:
- new Vue,执行初始化
- 挂载$mount方法,通过自定义Render方法、template、el等生成Render函数
- 通过Watcher监听数据的变化
- 当数据发生变化时,Render函数执行生成VNode对象
- 通过patch方法,对比新旧VNode对象,通过DOM Diff算法,添加、修改、删除真正的DOM元素
-
React 元素都是immutable 不可变的。当元素被创建之后,你是无法改变其内容或属性的。一个元素就好像是动画里的一帧,它代表应用界面在某一时间点的样子。
-
根据我们现阶段了解的有关 React 知识,更新界面的唯一办法是创建一个新的元素,然后将它传入 ReactDOM.render() 方法
-
React本身,是严格的view层,MVC模式
-
Vue 提供了Vue-cli 脚手架,能让你非常容易地构建项目,包含了 Webpack,Browserify,甚至 no build system。
-
Vue是MVVM模式的一种方式实现
-
虽然没有完全遵循 MVVM 模型,Vue 的设计无疑受到了它的启发。因此在文档中经常会使用 vm (ViewModel 的简称) 这个变量名表示 Vue 实例。
-
React 提供了create-react-app,但是现在还存在一些局限性:
- 它不允许在项目生成时进行任何配置,而 Vue 支持 Yeoman-like 定制。
- 它只提供一个构建单页面应用的单一模板,而 Vue 提供了各种���途的模板。
- 它不能用用户自建的模板构建项目,而自建模板对企业环境下预先建立协议是特别有用的。
-
在 React 中,一切都是 JavaScript。不仅仅是 HTML 可以用 JSX 来表达,现在的潮流也越来越多地将 CSS 也纳入到 JavaScript 中来处理。这类方案有其优点,但也存在一些不是每个开发者都能接受的取舍。
Vue 的整体思想是拥抱经典的 Web 技术,并在其上进行扩展。
-
在 React 中,所有的组件的渲染功能都依靠 JSX。JSX 是使用 XML 语法编写 JavaScript 的一种语法糖。
-
JSX, 一种 JavaScript 的语法扩展。 我们推荐在 React 中使用 JSX 来描述用户界面。JSX 乍看起来可能比较像是模版语言,但事实上它完全是在 JavaScript 内部实现的。
-
JSX 用来声明 React 当中的元素。
-
JSX本身也是一种表达式,在编译之后呢,JSX 其实会被转化为普通的 JavaScript 对象。这也就意味着,你其实可以在 if 或者 for 语句里使用 JSX,将它赋值给变量,当作参数传入,作为返回值都可以
-
JSX 说是手写的渲染函数有下面这些优势:
- 你可以使用完整的编程语言 JavaScript 功能来构建你的视图页面。比如你可以使用临时变量、JS 自带的流程控制、以及直接引用当前 JS 作用域中的值等等。
- 开发工具对 JSX 的支持相比于现有可用的其他 Vue 模板还是比较先进的 (比如,linting、类型检查、编辑器的自动完成)。
-
除非你把组件分布在多个文件上 (例如 CSS Modules),CSS 作用域在 React 中是通过 CSS-in-JS 的方案实现的 (比如 styled-components、glamorous 和 emotion)。这引入了一个新的面向组件的样式范例,它和普通的 CSS 撰写过程是有区别的。另外,虽然在构建时将 CSS 提取到一个单独的样式表是支持的,但 bundle 里通常还是需要一个运行时程序来让这些样式生效。当你能够利用 JavaScript 灵活处理样式的同时,也需要权衡 bundle 的尺寸和运行时的开销。
-
事实上 Vue 也提供了渲染函数,甚至支持 JSX。然而,我们默认推荐的还是模板。任何合乎规范的 HTML 都是合法的 Vue 模板,这也带来了一些特有的优势:
- 对于很多习惯了 HTML 的开发者来说,模板比起 JSX 读写起来更自然。这里当然有主观偏好的成分,但如果这种区别会导致开发效率的提升,那么它就有客观的价值存在。
- 基于 HTML 的模板使得将已有的应用逐步迁移到 Vue 更为容易。
- 这也使得设计师和新人开发者更容易理解和参与到项目中。
- 你甚至可以使用其他模板预处理器,比如 Pug 来书写 Vue 的模板。
-
Vue.js 使用了基于 HTML 的模板语法,允许开发者声明式地将 DOM 绑定至底层 Vue 实例的数据。所有 Vue.js 的模板都是合法的 HTML ,所以能被遵循规范的浏览器和 HTML 解析器解析。
-
在底层的实现上,Vue 将模板编译成虚拟 DOM 渲染函数。结合响应系统,在应用状态改变时,Vue 能够智能地计算出重新渲染组件的最小代价并应用到 DOM 操作上。
-
Vue 设置样式的默认方法是单文件组件里类似 style 的标签。
单文件组件让你可以在同一个文件里完全控制 CSS,将其作为组件代码的一部分。 -
Vue 的单文件组件里的样式设置是非常灵活的。通过 vue-loader,你可以使用任意预处理器、后处理器,甚至深度集成 CSS Modules——全部都在
-
更抽象一点来看,我们可以把组件区分为两类:一类是偏视图表现的 (presentational),一类则是偏逻辑的 (logical)。我们推荐在前者中使用模板,在后者中使用 JSX 或渲染函数。这两类组件的比例会根据应用类型的不同有所变化,但整体来说我们发现表现类的组件远远多于逻辑类组件。
9.1.1 期待构建一个大型应用程序——选择React
- 同时用Vue和React实现的简单应用程序,可能会让一个开发者潜意识中更加倾向于Vue。这是因为基于模板的应用程序第一眼看上去更加好理解,而且能很快跑起来。但是这些好处引入的技术债会阻碍应用扩展到更大的规模。模板容易出现很难注意到的运行时错误,同时也很难去测试,重构和分解。
相比之下,Javascript模板可以组织成具有很好的分解性和干(DRY)代码的组件,干代码的可重用性和可测试性更好。Vue也有组件系统和渲染函数,但是React的渲染系统可配置性更强,还有诸如浅(shallow)渲染的特性,和React的测试工具结合起来使用,使代码的可测试性和可维护性更好。
与此同时,React的immutable应用状态可能写起来不够简洁,但它在大型应用中意义非凡,因为透明度和可测试性在大型项目中变得至关重要。
9.1.2 期待同时适用于Web端和原生APP的框架——选择React
-
React Native是一个使用Javascript构建移动端原生应用程序(iOS,Android)的库。 它与React.js相同,只是不使用Web组件,而是使用原生组件。 如果你学过React.js,很快就能上手React Native,反之亦然。
它的意义在于,开发者只需要一套知识和工具就能开发Web应用和移动端原生应用。如果你想同时做Web端开发和移动端开发,React为你准备了一份大礼。
阿里的Weex也是一个跨平台UI项目,目前它以Vue为灵感,使用了许多相同的语法,同时计划在未来完全集成Vue,然而集成的时间和细节还不清楚。因为Vue将HTML模板作为它设计的核心部分,并且现有特性不支持自定义渲染,因此很难看出目前的Vue.js的跨平台能力能像React和React Native一样强大。 -
毫无疑问,React是目前最受欢迎的前端框架。它在NPM上每个月的下载量超过了250万次,相比之下,Vue是22.5万次。人气不仅仅是一个肤浅的数字,这意味着更多的文章,教程和更多Stack Overflow的解答,还意味有着更多的工具和插件可以在项目中使用,让开发者不再孤立无援。
这两个框架都是开源的,但是React诞生于Facebook,有Facebook背书,它的开发者和Facebook都承诺会持续维护React。相比之下,Vue是独立开发者尤雨溪的作品。尤雨溪目前在全职维护Vue,也有一些公司资助Vue,但是规模和Facebook和Google没得比。不过请对Vue的团队放心,它的小规模和独立性并没有成为劣势,Vue有着固定的发布周期,甚至更令人称道的是,Github上Vue只有54个open issue,3456个closed issue,作为对比,React有多达530个open issue,3447个closed issue。 -
Vue应用的默认选项是把markup放在HTML文件中。数据绑定表达式采用的是和Angular相似的mustache语法,而指令(特殊的HTML属性)用来向模板添加功能。
相比之下,React应用不使用模板,它要求开发者借助JSX在JavaScript中创建DOM。 -
对于来自标准Web开发方式的新开发者,模板更容易理解。但是一些资深开发者也喜欢模板,因为模板可以更好的把布局和功能分割开来,还可以使用Pug之类的模板引擎。
但是使用模板的代价是不得不学习所有的HTML扩展语法,而渲染函数只需要会标准的HTML和JavaScript。而且比起模板,渲染函数更加容易调试和测试。当然你不应该因为这方面的原因错过Vue,因为在Vue2.0中提供了使用模板或者渲染函数的选项。
9.2.2 期待简单和“能用就行”的东西——选择 Vue
-
一个简单的Vue项目可以不需要转译直接运行在浏览器中,所以使用Vue可以像使用jQuery一样简单。当然这对于React来说在技术上也是可行的,但是典型的React代码是重度依赖于JSX和诸如class之类的ES6特性的。
Vue的简单在程序设计的时候体现更深,让我们来比较一下两个框架是怎样处理应用数据的(也就是state)。 -
React中是通过比较当前state和前一个state来决定何时在DOM中进行重渲染以及渲染的内容,因此需要不可变(immutable)的state。
Vue中的数据是可变(mutated)的,所以同样的操作看起来更加简洁。
让我们来看看Vue中是如何进行状态管理的。当向state添加一个新对象的时候,Vue将遍历其中的所有属性并且转换为getter,setter方法,现在Vue的响应系统开始保持对state的跟踪了,当state中的内容发生变化的时候就会自动重新渲染DOM。令人称道的是,Vue中改变state的状态的操作不仅更加简洁,而且它的重新渲染系统也比React 的更快更有效率。 -
Vue的响应系统还有有些坑的,例如:它不能检测属性的添加和删除和某些数组更改。这时候就要用到Vue API中的类似于React的set方法来解决。
-
当应用程序的状态改变时,React和Vue都将构建一个虚拟DOM并同步到真实DOM中。 两者都有各自的方法优化这个过程。
Vue核心开发者提供了一个benchmark测试,可以看出Vue的渲染系统比React的更快。测试方法是10000个项目的列表渲染100次,结果如下图。从实用的观点来看,这种benchmark只和边缘情况有关,大部分应用程序中不会经常进行这种操作,所以这不应该被视为一个重要的比较点。但是,页面大小是与所有项目有关的,这方面Vue再次领先,它目前的版本压缩后只有25.6KB。React要实现同样的功能,你需要React DOM(37.4KB)和React with Addon库(11.4KB),共计44.8KB,几乎是Vue的两倍大。双倍的体积并不能带来双倍的功能。 -
客户端渲染路线:1. 请求一个html -> 2. 服务端返回一个html -> 3. 浏览器下载html里面的js/css文件 -> 4. 等待js文件下载完成 -> 5. 等待js加载并初始化完成 -> 6. js代码终于可以运行,由js代码向后端请求数据( ajax/fetch ) -> 7. 等待后端数据返回 -> 8. react-dom( 客户端 )从无到完整地,把数据渲染为响应页面
-
服务端渲染路线:1. 请求一个html -> 2. 服务端请求数据( 内网请求快 ) -> 3. 服务器初始渲染(服务端性能好,较快) -> 4. 服务端返回已经有正确内容的页面 -> 5. 客户端请求js/css文件 -> 6. 等待js文件下载完成 -> 7. 等待js加载并初始化完成 -> 8. react-dom( 客户端 )把剩下一部分渲染完成( 内容小,渲染快 )
-
React的虚拟DOM是其可被用于服务端渲染的关键。首先每个ReactComponent 在虚拟DOM中完成渲染,然后React通过虚拟DOM来更新浏览器DOM中产生变化的那一部分,虚拟DOM作为内存中的DOM表现,为React在Node.js这类非浏览器环境下的吮吸给你提供了可能,React可以从虚拟DoM中生成一个字符串。而不是跟新真正的DOM,这使得我们可以在客户端和服务端使用同一个React Component。
-
React 提供了两个可用于服务端渲染组件的函数:React.renderToString 和React.render-ToStaticMarkup。 在设计用于服务端渲染的ReactComponent时需要有预见性,考虑以下方面。
- 选取最优的渲染函数。
- 如何支持组件的异步状态。
- 如何将应用的初始化状态传递到客户端。
- 哪些生命周期函数可以用于服务端的渲染。
- 如何为应用提供同构路由支持。
- 单例、实例以及上下文的用法。
1. 什么是服务器端渲染(SSR)?
-
Vue.js 是构建客户端应用程序的框架。默认情况下,可以在浏览器中输出 Vue 组件,进行生成 DOM 和操作 DOM。然而,也可以将同一个组件渲染为服务器端的 HTML 字符串,将它们直接发送到浏览器,最后将静态标记”混合”为客户端上完全交互的应用程序。
-
服务器渲染的 Vue.js 应用程序也可以被认为是”同构”或”通用”,因为应用程序的大部分代码都可以在服务器和客户端上运行。
2. 服务器端渲染优势
. 更好的 SEO,由于搜索引擎爬虫抓取工具可以直接查看完全渲染的页面。
. 更快的内容到达时间(time-to-content),特别是对于缓慢的网络情况或运行缓慢的设备。无需等待所有的 JavaScript 都完成下载并执行,才显示服务器渲染的标记,所以你的用户将会更快速地看到完整渲染的页面。通常可以产生更好的用户体验,并且对于那些「内容到达时间(time-to-content)与转化率直接相关」的应用程序而言,服务器端渲染(SSR)至关重要。
-
传入数据模型,渲染 UI 但没有任何交互。最好把这些过程解耦,因为创建一个静态版本更多需要的是码代码,不太需要逻辑思考,而添加交互则更多需要的是逻辑思考,不是码代码。
-
在创建静态版本的时候不要使用 state。
-
你可以自顶向下或者自底向上构建应用。也就是,你可以从层级最高的组件开始构建(即 FilterableProductTable开始)或层级最低的组件开始构建(ProductRow)。在较为简单的例子中,通常自顶向下更容易,而在较大的项目中,自底向上会更容易并且在你构建的时候有利于编写测试。
-
React 的单向数据流(也叫作单向绑定)保证了一切是模块化并且是快速的。
-
想想实例应用中的数据,让我们来看看每一条,找出哪一个是 state。每个数据只要考虑三个问题:
- 它是通过 props 从父级传来的吗?如果是,他可能不是 state。
- 它随着时间推移不变吗?如果是,它可能不是 state。
- 你能够根据组件中任何其他的 state 或 props 把它计算出来吗?如果是,它不是 state。
-
对你应用的每一个 state:
- 确定每一个需要这个 state 来渲染的组件。
- 找到一个公共所有者组件(一个在层级上高于所有其他需要这个 state 的组件的组件)
- 这个公共所有者组件或另一个层级更高的组件应该拥有这个 state。
- 如果你没有找到可以拥有这个 state 的组件,创建一个仅用来保存状态的组件并把它加入比这个公共所有者组件层级更高的地方。
总结一下,我们发现,
. Vue的优势包括:
. 模板和渲染函数的弹性选择
. 简单的语法及项目创建
. 更快的渲染速度和更小的体积
. React的优势包括:
. 更适用于大型应用和更好的可测试性
. 同时适用于Web端和原生App
. 更大的生态圈带来的更多支持和工具
. 而实际上,React和Vue都是非常优秀的框架,它们之间的相似之处多过不同之处,并且它们大部分最棒的功能是相通的:
. 利用虚拟DOM实现快速渲染
. 轻量级
. 响应式和组件化
. 服务器端渲染
. 易于集成路由工具,打包工具以及状态管理工具
. 优秀的支持和社区
文章参考来源:
目录
编程语言分为 编译型语言和解释型语 言两类。
编译型语言在执行之前要先进行完全编译,而 解释型语言一边编译一边执行, 很明显解释型语言的执行速度是慢于编译型语言的,而JavaScript就是一种解释型脚本语言, 支持动态类型、弱类型、基于原型的语言,内置支持类型。
就是将HTML/CSS/JavaScript等文本或图片等信息转换成浏览器上可见的可视化图像结果的转换程序。
WebKit,一个由苹果发起的一个开源项目,如今它在移动端占据着垄断地位,更有基于WebKit的web操作系统不断涌现(如:Chrome OS、Web OS)。
WebKit内部结构大体如下

上图中实线框内模块是所有移植的共有部分,虚线框内不同的厂商可以自己实现。由上图可知,WebKit主要有操作系统、WebCore 、WebKit嵌入式接口和第三方库组成。
操作系统: 是管理和控制计算机硬件与软件资源的计算机程序。
WebCore: JavaScriptCore是WebKit的默认引擎,在谷歌系列产品中被替换为V8引擎。
WebKit嵌入式接口: 该接口主要供浏览器调用,与移植密切相关,不同的移植有不同的接口规范。 第三方库: 主要是诸如图形库、网络库、视频库、数据存储库等第三方库。
首先,系统将网页输入到HTML解析器,HTML解析器解析,然后构建DOM树,在这期间如果遇到JavaScript代码则交给JavaScript引擎处理; 如果遇到CSS样式信息,则构建一个内部绘图模型。该模型由布局模块计算模型内部各个元素的位置和大小信息,最后由绘图模块完成从该模型到图像的绘制。
对于网页的绘制过程,大体可以分为3个阶段:
1、从输入URL到生成DOM树
在这个阶段中,主要会经历一下几个步骤:
地址栏输入URL,WebKit调用资源加载器加载相应资源;
加载器依赖网络模块建立连接,发送请求并接收答复;
WebKit接收各种网页或者资源数据,其中某些资源可能同步或异步获取;
网页交给HTML解析器转变为词语;
解释器根据词语构建节点,形成DOM树;
如果节点是JavaScript代码,调用JavaScript引擎解释并执行;
JavaScript代码可能会修改DOM树结构;
如果节点依赖其他资源,如图片、视频等,调用资源加载器加载它们,但这些是异步加载的,不会阻碍当前DOM树继续创建;如果是JavaScript资源URL(没有标记异步方式),则需要停止当前DOM树创建,直到JavaScript加载并被JavaScript引擎执行后才继续DOM树的创建。
2、从DOM树到构建WebKit绘图上下文
CSS文件被CSS解释器解释成内部表示;
CSS解释器完成工作后,在DOM树上附加样式信息,生成RenderObject树;
RenderObject节点在创建的同时,WebKit会根据网页层次结构构建RenderLayer树,同时构建一个虚拟绘图上下文。
3、绘图上下文内容并呈现图像内容
绘图上下文是一个与平台无关的抽象类,它将每个绘图操作桥接到不同的具体实现类,也就是绘图具体实现类;
绘图实现类也可能有简单的实现,也可能有复杂的实现,软件渲染、硬件渲染、合成渲染等;
绘图实现类将2D图形库或者3D图形库绘制结果保存,交给浏览器界面进行展示。
JavaScript这种解释性语言来讲,如何提高解析速度就是当务之急。JavaScript引擎和渲染引擎的关系如下图所示

为了提高性能,JavaScript引入了Java虚拟机和C++编译器中的众多技术。 而一个完整JavaScript引擎的执行过程大致流程如下:源代码-→抽象语法树-→字节码-→JIT-→本地代码。一个典型的抽象语法树如下图所示:
题外话 关于 JIT:
JIT 编译 (JIT compilation),运行时需要代码时。
JIT具体的做法是这样的:当载入一个类型时,CLR为该类型创建一个内部数据结构和相应的函数,当函数第一被调用时,JIT将该函数编译成机器语言.当再次遇到该函数时则直接从cache中执行已编译好的机器语言.
为了节约将抽象语法树通过JIT技术转换成本地代码的时间,V8放弃了生成字节码阶段的性能优化。而通过Profiler采集一些信息,来优化本地代码。
在2017年4月底,v8 发布了5.9 版本,在此版本中新增了一个 Ignition 字节码解释器,并默认开启。 做出这一改变的原因为:(主要动机)减轻机器码占用的内存空间,即牺牲时间换空间; 提高代码的启动速度;对 v8 的代码进行重构,降低 v8 的代码复杂度(详细介绍请查阅:JS 引擎与字节码的不解之缘)
前面,我们介绍了V8引擎的一些历史,下面我们重点来看看V8项目一些知识。首先,V8项目的结构如下:

JavaScript作为一种无类型的语言,在编译时并不能准确知道变量的类型,只可以在运行时确定。因而JavaScript运行效率比C++或Java低。
而对于JavaScript 来说,并不能像C++那样在执行时已经知道变量的类型和地址,所以在代码解析过程中,会产生很多的临时变量,而变量的存取是非常普遍和频繁的。
在JavaScript中,除boolean,number,string,null,undefined这个五个简单变量外,其他的数据都是对象,V8使用一种特殊的方式来表示它们,进而优化JavaScript的内部表示问题。
JavaScript对象在V8中的实现包含三个部分:隐藏类指针,这是v8为JavaScript对象创建的隐藏类;属性值表指针,指向该对象包含的属性值;元素表指针,指向该对象包含的属性。
在V8中,数据的内部表示由数据的实际内容和数据的句柄构成。数据的实际内容是变长的,类型也是不同的;句柄固定大小,包含指向数据的指针。 这种设计可以方便V8进行垃圾回收和移动数据内容,如果直接使用指针的话就会出问题或者需要更大的开销, 使用句柄的话,只需修改句柄中的指针即可,使用者使用的还是句柄,指针改动是对使用者透明的。
除少数数据(如整型数据)由handle本身存储外,其他内容限于句柄大小和变长等原因,都存储在堆中。 整数直接从value中取值,然后使用一个指针指向它,可以减少内存的占用并提高访问速度。 一个句柄对象的大小是4字节(32位设备)或者8字节(64位设备),而在JavaScriptCore中,使用的8个字节表示句柄。 在堆中存放的对象都是4字节对齐的,所以它们指针的后两位是不需要的,V8用这两位表示数据的类型,00为整数,01为其他。
V8引擎在执行JavaScript的过程中,主要有两个阶段:编译和运行。
在V8引擎中,源代码先被解析器转变为抽象语法树(AST),然后使用JIT编译器的全代码生成器从AST直接生成本地可执行代码。
但由于缺少了转换为字节码这一中间过程,也就减少了优化代码的机会。
V8引擎编译本地代码时使用的主要类如下所示:
Script:表示JavaScript代码,即包含源代码,又包含编译之后生成的本地代码,即是编译入口,又是运行入口;
Compiler:编译器类,辅组Script类来编译生成代码,调用解释器(Parser)来生成AST和全代码生成器,将AST转变为本地代码;
AstNode:抽象语法树节点类,是其他所有节点的基类,包含非常多的子类,后面会针对不同的子类生成不同的本地代码;
FullCodeGenerator:AstVisitor类的子类,通过遍历AST来为JavaScript生成本地可执行代码。
Script类调用Compiler类的Compile函数为其生成本地代码;
Compile函数先使用Parser类生成AST,再使用FullCodeGenerator类来生成本地代码;
本地代码与具体的硬件平台密切相关,FullCodeGenerator使用多个后端来生成与平台相匹配的本地汇编代码。
大体的流程图如下所示:

在执行编译之前,V8会构建众多全局对象并加载一些内置的库(如math库),来构建一个运行环境。 但是,在JavaScript源代码中,并非所有的函数都被编译生成本地代码,而是采用在调用时才会编译的逻辑来动态编译。
由于V8缺少了生成中间字节码这一环节,为了提升性能,V8会在生成本地代码后,使用数据分析器(profiler)采集一些信息, 然后根据这些数据将本地代码进行优化,生成更高效的本地代码,这是一个逐步改进的过程。 当发现优化后代码的性能还不如未优化的代码,V8将退回原来的代码,也就是优化回滚。
在这一阶段涉及的类主要有:
Script:表示JavaScript代码,即包含源代码,又包含编译之后生成的本地代码,即是编译入口,又是运行入口;
Execution:运行代码的辅组类,包含一些重要函数,如Call函数,它辅组进入和执行Script代码;
JSFunction:需要执行的JavaScript函数表示类;
Runtime:运行这些本地代码的辅组类,主要提供运行时所需的辅组函数,如:属性访问、类型转换、编译、算术、位操作、比较、正则表达式等;
Heap:运行本地代码需要使用的内存堆类;
MarkCompactCollector:垃圾回收机制的主要实现类,用来标记、清除和整理等基本的垃圾回收过程;
SweeperThread:负责垃圾回收的线程。
在V8中,函数是一个基本单位,当某个JavaScript函数被调用时,V8会查找该函数是否已经生成本地代码,如果已经生成,则直接调用该函数。 否则,V8引擎会生成属于该函数的本地代码。 这样,对于那些不用的代码就可以减少执行时间。再次借助Runtime类中的辅组函数,将不用的空间进行标记清除和垃圾回收。
因为V8是基于AST直接生成本地代码,没有经过中间表示层的优化,所以本地代码尚未经过很好的优化。 于是,在2010年,V8引入了新的编译器-Crankshaft,它主要针对热点函数进行优化, 基于JavaScript源代码开始分析而非本地代码,同时构建Hydroger图并基于此来进行优化分析。
Crankshaft编译器为了性能考虑,通常会做出比较乐观和大胆的预测—代码稳定且变量类型不变,所以可以生成高效的本地代码。 但是,鉴于JavaScript的一个弱类型的语言,变量类型也可能在执行的过程中进行改变,鉴于这种情况,V8会将该编译器做的想当然的优化进行回滚,称为优化回滚。
例如,下面的示例:
1var counter = 0;
2function test(x, y) {
3 counter++;
4 if (counter < 1000000) {
5 // do something
6 return 'jeri';
7 }
8 var unknown = new Date();
9 console.log(unknown);
10}该函数被调用多次之后,V8引擎可能会触发Crankshaft编译器对其进行优化,而优化代码认为示例代码的类型信息都已经被确定。 当程序执行到new Date()这个地方,并未获取unknown这个变量的类型,V8只得将该部分代码进行回滚。
优化回滚是一个很耗时的操作,在写代码过程中,尽量不要触发优化该操作。在最近发布的 V8 5.9 版本中,新增了一个 Ignition 字节码解释器, TurboFan 和 Ignition 结合起来共同完成JavaScript的编译。 这个版本中消除 Cranshaft 这个旧的编译器,并让新的 Turbofan 直接从字节码来优化代码, 并当需要进行反优化的时候直接反优化到字节码,而不需要再考虑 JS 源代码。
Node中通过JavaScript使用内存时就会发现只能使用部分内存(64位系统下约为1.4 GB,32位系统下约为0.7 GB), 其深层原因是 V8 垃圾回收机制的限制所致(如果可使用内存太大,V8在进行垃圾回收时需耗费更多的资源和时间,严重影响JS的执行效率)。下面对内存管理进行介绍。
内存的管理组要由分配和回收两个部分构成。V8的内存划分如下:
Zone:管理小块内存。其先自己申请一块内存,然后管理和分配一些小内存,当一块小内存被分配之后,不能被Zone回收, 只能一次性回收Zone分配的所有小内存。当一个过程需要很多内存,Zone将需要分配大量的内存,却又不能及时回收,会导致内存不足情况。
堆:管理JavaScript使用的数据、生成的代码、哈希表等。为方便实现垃圾回收,堆被分为三个部分(这和Java等的堆不一样):
年轻分代:为新创建的对象分配内存空间,经常需要进行垃圾回收。 为方便年轻分代中的内容回收,可再将年轻分代分为两半,一半用来分配,另一半在回收时负责将之前还需要保留的对象复制过来。
年老分代:根据需要将年老的对象、指针、代码等数据保存起来,较少地进行垃圾回收。
大对象:为那些需要使用较多内存对象分配内存,当然同样可能包含数据和代码等分配的内存,一个页面只分配一个对象。
用一张图可以表示如下:

V8 使用了分代和大数据的内存分配,在回收内存时使用精简整理的算法标记未引用的对象,然后消除没有标记的对象,最后整理和压缩那些还未保存的对象,即可完成垃圾回收。
在V8中,使用较多的是年轻分代和年老分代。年轻分代中的对象垃圾回收主要通过 Scavenge 算法进行垃圾回收。在Scavenge的具体实现中,主要采用了 Cheney 算法。
Cheney算法:通过复制的方式实现的垃圾回收算法。 它将堆内存分为两个 semispace(半空间),一个处于使用中(From空间),另一个处于闲置状态(To空间)。 当分配对象时,先是在From空间中进行分配。 当开始进行垃圾回收时,会检查From空间中的存活对象,这些存活对象将被复制到To空间中,而非存活对象占用的空间将会被释放。 完成复制后,From空间和To空间的角色发生对换。在垃圾回收的过程中,就是通过将存活对象在两个 semispace 空间之间进行复制。
年轻分代中的对象有机会晋升为年老分代,条件主要有两个:一个是对象是否经历过Scavenge回收,一个是To空间的内存占用比超过限制。
对于年老分代中的对象,由于存活对象占较大比重,再采用上面的方式会有两个问题: 一个是存活对象较多,复制存活对象的效率将会很低;另一个问题依然是浪费一半空间的问题。 为此,V8在年老分代中主要采用了Mark-Sweep(标记清除)标记清除和Mark-Compact(标记整理) 相结合的方式进行垃圾回收。
在V8引擎启动时,需要构建JavaScript运行环境,需要加载很多内置对象, 同时也需要建立内置的函数,如Array,String,Math等。为了使V8更加整洁, 加载对象和建立函数等任务都是使用JavaScript文件来实现的,V8引擎负责提供机制来支持,就是在编译和执行JavaScript前先加载这些文件。
V8引擎需要编译和执行这些内置的JavaScript代码,同时使用堆等来保存执行过程中创建的对象、代码等,这些都需要时间。 为此,V8引入了快照机制,将这些内置的对象和函数加载之后的内存保存并序列化。经过快照机制的启动时间可以缩减几毫秒。
JavaScriptCore引擎是WebKit中默认的JavaScript引擎,也是苹果开源的一个项目,应用较为广泛。 最初,性能不是很好,从2008年开始了一系列的优化,重新实现了编译器和字节码解释器,使得引擎的性能有较大的提升。 随后内嵌缓存、基于正则表达式的JIT、简单的JIT及字节码解释器等技术引入进来,JavaScriptCore引擎也在不断的迭代和发展。
JavaScriptCore 的大致流程为:源代码-→抽象语法树-→字节码-→JIT-→本地代码。
JavaScriptCore与V8有一些不同之处,其中最大的不同就是新增了字节码的中间表示, 并加入了多层JIT编译器(如:简单JIT编译器、DFG JIT编译器、LLVM等)优化性能,不停的对本地代码进行优化(在V8 的 5.9 版本中,新增了一个 Ignition 字节码解释器)。
JavaScript引擎的主要功能是解析和执行JavaScript代码,往往不能满足使用者多样化的需要, 那么就可以增加扩展以提升它的能力。V8引擎有两种扩展机制:绑定和扩展。
使用IDL文件或接口文件生成绑定文件,将这些文件同V8引擎一起编译。 WebKit中使用IDL来定义JavaScript,但又与IDL有所不同,有一些改变。定义一个新的接口的步骤大致如下:
1.定义新的接口文件,可以在JavaScript代码进行调用,如mymodule.MyObj.myAttr:
1module mymodule {
2 interface [
3 InterfaceName = MyObject
4 ] MyObj {
5 readonly attribute long myAttr;
6 DOMString myMethod (DOMString myArg);
7 };
8}2.按照引擎定义的标准接口为基础实现接口类,生成JavaScript引擎所需的绑定文件。 WebKit提供了工具帮助生成所需的绑定类,根据引擎不同和引擎开发语言的不同而有所差异。 V8引擎会为上述示例代码生成 v8MyObj.h (MyObj类具体的实现代码)和 V8MyObj.cpp (桥接代码,辅组注册桥接的函数到V8引擎)两个绑定文件。
JavaScript引擎绑定机制需要将扩展代码和JavaScript引擎一块编译和打包, 不能根据需要在引擎启动后再动态注入这些本地代码。 在实际WEB开发中,开发者都是基于现有浏览器的,根本不可能介入到JavaScript引擎的编译中, 绑定机制有很大的局限性,但其非常高效,适用于对性能要求较高的场景。
通过V8的基类Extension进行能力扩展,无需和V8引擎一起编译,可以动态为引擎增加功能特性,具有很强的灵活性。
Extension机制的大致思路就是,V8提供一个基类Extension和一个全局注册函数,要想扩展JavaScript能力,需要经过以下步骤:
1class MYExtension : public v8::Extension {
2 public:
3 MYExtension() : v8::Extension("v8/My", "native function my();") {}
4 virtual v8::Handle<v8::FunctionTemplate> GetNativeFunction (
5 v8::Handle<v8::String> name) {
6 // 可以根据name来返回不同的函数
7 return v8::FunctionTemplate::New(MYExtention::MY);
8 }
9 static v8::Handle<v8::Value> MY(const v8::Arguments& args) {
10 // Do sth here
11 return v8::Undefined();
12 }
13};
14MYExtension extension;
15RegisterExtension(&extension);1.基于Extension基类构建一个它的子类,并实现它的虚函数—GetNativeFunction,根据参数name来决定返回实函数;
2.创建一个该子类的对象,并通过注册函数将该对象注册到V8引擎,当JavaScript调用’my’函数时就可被调用到。 Extension机制是调用V8的接口注入新函数,动态扩展非常方便,但没有绑定机制高效,适用于对性能要求不高的场景。
作为一个提高JavaScript渲染的高效引擎,学习V8引擎应该重点掌握以下几个概念:
- 类型。
对于函数,JavaScript是一种动态类型语言,JavaScriptCore和V8都使用隐藏类和内嵌缓存来提高性能, 为了保证缓存命中率,一个函数应该使用较少的数据类型; 对于数组,应尽量存放相同类型的数据,这样就可以通过偏移位置来访问。 - 数据表示。
简单类型数据(如整型)直接保存在句柄中,可以减少寻址时间和内存占用, 如果可以使用整数表示的,尽量不要用浮点类型。 - 内存。 虽然JavaScript语言会自己进行垃圾回收,但我们也应尽量做到及时回收不用的内存, 对不再使用的对象设置为null或使用delete方法来删除(使用delete方法删除会触发隐藏类新建,需要更多的额外操作)。
- 优化回滚。 在执行多次之后,不要出现修改对象类型的语句,尽量不要触发优化回滚,否则会大幅度降低代码的性能。
- 新机制。 使用JavaScript引擎或者渲染引擎提供的新机制和新接口提高性能。
参考文章如下:
Google V8 引擎【翻】
87.如何进行 node 内存优化?【Nodejs】
目录
假设代码中有一个对象 jerry ,这个对象从创建到被销毁,刚好走完了整个生命周期,通常会是这样一个过程:
1、这个对象被分配到了 new space;
2、随着程序的运行,new space 塞满了,gc 开始清理 new space 里的死对象,jerry 因为还处于活跃状态,所以没被清理出去;
3、gc 清理了两遍 new space,发现 jerry 依然还活跃着,就把 jerry 移动到了 old space;
4、随着程序的运行,old space 也塞满了,gc 开始清理 old space,这时候发现 jerry 已经没有被引用了,就把 jerry 给清理出去了。
说明:
第二步里,清理 new space 的过程叫做 Scavenge,这个过程采用了空间换时间的做法, 用到了上面图中的 inactive new space,过程如下:
当活跃区满了之后,交换活跃区和非活跃区,交换后活跃区变空了;
将非活跃区的两次清理都没清理出去的对象移动到 old space;
将还没清理够两次的但是活跃状态的对象移动到活跃区。
第四步里,清理 old space 的过程叫做 Mark-sweep ,这块占用内存很大,所以没有使用 Scavenge, 这个回收过程包含了若干次标记过程和清理过程:
标记从根(root)可达的对象为黑色;
遍历黑色对象的邻接对象,直到所有对象都标记为黑色;
循环标记若干次;
清理掉非黑色的对象。
简单来说,Mark-sweep 就是把从根节点无法获取到的对象清理掉了。
JavaScript使用垃圾回收机制来自动管理内存。
垃圾回收是一把双刃剑,其好处是可以大幅简化程序的内存管理代码,降低程序员的负担,减少因 长时间运转而带来的内存泄露问题。 但使用了垃圾回收即意味着程序员将无法掌控内存。
ECMAScript没有暴露任何垃圾回收器的接口。我们无法强迫其进 行垃圾回收,更无法干预内存管理
在浏览器中,Chrome V8引擎实例的生命周期不会很长(谁没事一个页面开着几天几个月不关),而且运行在用户的机器上。 如果不幸发生内存泄露等问题,仅仅会 影响到一个终端用户。 且无论这个V8实例占用了多少内存,最终在关闭页面时内存都会被释放,几乎没有太多管理的必要(当然并不代表一些大型Web应用不需 要管理内存)。 但如果使用Node作为服务器,就需要关注内存问题了,一旦内存发生泄漏,久而久之整个服务将会瘫痪(服务器不会频繁的重启)。
Chrome限制了所能使用的内存极限(64位为1.4GB,32位为1.0GB),这也就意味着将无法直接操作一些大内存对象。
Chrome之所以限制了内存的大小,表面上的原因是V8最初是作为浏览器的JavaScript引擎而设计,不太可能遇到大量内存的场景, 而深层次的原因 则是由于V8的垃圾回收机制的限制。 由于V8需要保证JavaScript应用逻辑与垃圾回收器所看到的不一样,V8在执行垃圾回收时会阻塞 JavaScript应用逻辑, 直到垃圾回收结束再重新执行JavaScript应用逻辑,这种行为被称为“全停顿”(stop-the-world)。 若V8的堆内存为1.5GB,V8做一次小的垃圾回收需要50ms以上,做一次非增量式的垃圾回收甚至要1秒以上。 这样浏览器将在1s内失去对用户的响 应,造成假死现象。如果有动画效果的话,动画的展现也将显著受到影响。
V8的堆其实并不只是由老生代和新生代两部分构成,可以将堆分为几个不同的区域:
* 新生代内存区:大多数的对象被分配在这里,这个区域很小但是垃圾回特别频繁
* 老生代指针区:属于老生代,这里包含了大多数可能存在指向其他对象的指针的对象,大多数从新生代晋升的对象会被移动到这里
* 老生代数据区:属于老生代,这里只保存原始数据对象,这些对象没有指向其他对象的指针
* 大对象区:这里存放体积超越其他区大小的对象,每个对象有自己的内存,垃圾回收其不会移动大对象
* 代码区:代码对象,也就是包含JIT之后指令的对象,会被分配在这里。唯一拥有执行权限的内存区
* Cell区、属性Cell区、Map区:存放Cell、属性Cell和Map,每个区域都是存放相同大小的元素,结构简单
每个区域都是由一组内存页构成,内存页是V8申请内存的最小单位,除了大对象区的内存页较大以外, 其他区的内存页都是1MB大小,而且按照1MB对 齐。 内存页除了存储的对象,还有一个包含元数据和标识信息的页头,以及一个用于标记哪些对象是活跃对象的位图区。 另外每个内存页还有一个单独分配在另外内 存区的槽缓冲区,里面放着一组对象,这些对象可能指向其他存储在该页的对象。 垃圾回收器只会针对新生代内存区、老生代指针区以及老生代数据区进行垃圾回收
如何确定哪些内存需要回收,哪些内存不需要回收,这是垃圾回收期需要解决的最基本问题。
我们可以这样假定,一个对象为活对象当且仅当它被一个根对象 或另一个活对象指向。根对象永远是活对象,它是被浏览器或V8所引用的对象。
垃圾回收器需要面临一个问题,它需要判断哪些是数据,哪些是指针。由于很多垃圾回收算法会将对象在内存中移动(紧凑,减少内存碎片),所以经常需要进行指针的改写。
目前主要有三种方法来识别指针:
- 保守法: 将所有堆上对齐的字都认为是指针,那么有些数据就会被误认为是指针。 于是某些实际是数字的假指针,会背误认为指向活跃对象, 导致内存泄露(假指针指向的对象可能是死对象,但依旧有指针指向——这个假指针指向它)同时我们不能移动任何内存区域。
- 编译器提示法: 如果是静态语言,编译器能够告诉我们每个类当中指针的具体位置, 而一旦我们知道对象时哪个类实例化得到的,就能知道对象中所有指针。 这是JVM实现垃圾回收的方式,但这种方式并不适合JS这样的动态语言
- 标记指针法: 这种方法需要在每个字末位预留一位来标记这个字段是指针还是数据。 这种方法需要编译器支持,但实现简单,而且性能不错。 V8采用的是这种方式。V8将所有数据以32bit字宽来存储,其中最低一位保持为0,而指针的最低两位为01
自动垃圾回收算法的演变过程中出现了很多算法,但是由于不同对象的生存周期不同,没有一种算法适用于所有的情况。 所以V8采用了一种分代回收的策 略,将内存分为两个生代:新生代和老生代。 新生代的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象。 分别对新生代和老生代使用 不同的垃圾回收算法来提升垃圾回收的效率。 对象起初都会被分配到新生代,当新生代中的对象满足某些条件(后面会有介绍)时,会被移动到老生代(晋升)
默认情况下,64位环境下的V8引擎的新生代内存大小32MB、老生代内存大小为1400MB,而32位则减半,分别为16MB和700MB。 V8内存的最大保留空间分别为1464MB(64位)和732MB(32位)。 具体的计算公式是4*reserved_semispace_space_ + max_old_generation_size_, 新生代由两块reserved_semispace_space_组成,每块16MB(64位)或8MB(32位)
大多数的对象被分配在这里,这个区域很小但是垃圾回特别频繁。 在新生代分配内存非常容易,我们只需要保存一个指向内存区的指针,不断根据新对象的大小进行递增即可。 当该指针到达了新生代内存区的末尾,就会有一次清理(仅仅是清理新生代)
新生代使用Scavenge算法进行回收。在Scavenge算法的实现中,主要采用了Cheney算法。
具体的执行过程大致是这样:
首先将From空间中所有能从根对象到达的对象复制到To区, 然后维护两个To区的指针scanPtr和allocationPtr,分别指向即将 扫描的活跃对象和即将为新对象分配内存的地方,开始循环。 循环的每一轮会查找当前scanPtr所指向的对象,确定对象内部的每个指针指向哪里。 如果指向 老生代我们就不必考虑它了。 如果指向From区,我们就需要把这个所指向的对象从From区复制到To区,具体复制的位置就是allocationPtr 所指向的位置。 复制完成后将scanPtr所指对象内的指针修改为新复制对象存放的地址,并移动allocationPtr。 如果一个对象内部的所有指针 都被处理完,scanPtr就会向前移动,进入下一个循环。 若scanPtr和allocationPtr相遇,则说明所有的对象都已被复制完,From 区剩下的都可以被视为垃圾,可以进行清理了。
举个栗子(以及凑篇幅),如果有类似如下的引用情况:
1 +----- A对象
2 |
3根对象----+----- B对象 ------ E对象
4 |
5 +----- C对象 ----+---- F对象
6 |
7 +---- G对象 ----- H对象
8
9 D对象 在执行Scavenge之前,From区长这幅模样
1+---+---+---+---+---+---+---+---+--------+
2| A | B | C | D | E | F | G | H | |
3+---+---+---+---+---+---+---+---+--------+ 那么首先将根对象能到达的ABC对象复制到To区,于是乎To区就变成了这个样子:
1 allocationPtr
2 ↓
3+---+---+---+----------------------------+
4| A | B | C | |
5+---+---+---+----------------------------+
6 ↑
7scanPtr 接下来进入循环,扫描scanPtr所指的A对象,发现其没有指针,于是乎scanPtr移动,变成如下这样
1 allocationPtr
2 ↓
3+---+---+---+----------------------------+
4| A | B | C | |
5+---+---+---+----------------------------+
6 ↑
7 scanPtr 接下来扫描B对象,发现其有指向E对象的指针,且E对象在From区,那么我们需要将E对象复制到allocationPtr所指的地方并移动allocationPtr指针:
1 allocationPtr
2 ↓
3+---+---+---+---+------------------------+
4| A | B | C | E | |
5+---+---+---+---+------------------------+
6 ↑
7 scanPtr B对象里所有指针都已被复制完,所以移动scanPtr:
1 allocationPtr
2 ↓
3+---+---+---+---+------------------------+
4| A | B | C | E | |
5+---+---+---+---+------------------------+
6 ↑
7 scanPtr 接下来扫描C对象,C对象中有两个指针,分别指向F对象和G对象,且都在From区,先复制F对象到To区:
1 allocationPtr
2 ↓
3+---+---+---+---+---+--------------------+
4| A | B | C | E | F | |
5+---+---+---+---+---+--------------------+
6 ↑
7 scanPtr 然后复制G对象到To区
1 allocationPtr
2 ↓
3+---+---+---+---+---+---+----------------+
4| A | B | C | E | F | G | |
5+---+---+---+---+---+---+----------------+
6 ↑
7 scanPtr 这样C对象内部的指针已经复制完成了,移动scanPtr:
1 allocationPtr
2 ↓
3+---+---+---+---+---+---+----------------+
4| A | B | C | E | F | G | |
5+---+---+---+---+---+---+----------------+
6 ↑
7 scanPtr 逐个扫描E,F对象,发现其中都没有指针,移动scanPtr:
1 allocationPtr
2 ↓
3+---+---+---+---+---+---+----------------+
4| A | B | C | E | F | G | |
5+---+---+---+---+---+---+----------------+
6 ↑
7 scanPtr 扫描G对象,发现其中有一个指向H对象的指针,且H对象在From区,复制H对象到To区,并移动allocationPtr:
1 allocationPtr
2 ↓
3+---+---+---+---+---+---+---+------------+
4| A | B | C | E | F | G | H | |
5+---+---+---+---+---+---+---+------------+
6 ↑
7 scanPtr 完成后由于G对象没有其他指针,且H对象没有指针移动scanPtr:
1 allocationPtr
2 ↓
3+---+---+---+---+---+---+---+------------+
4| A | B | C | E | F | G | H | |
5+---+---+---+---+---+---+---+------------+
6 ↑
7 scanPtr 此时scanPtr和allocationPtr重合,说明复制结束
可以对比一下From区和To区在复制完成后的结果:
1//From区
2+---+---+---+---+---+---+---+---+--------+
3| A | B | C | D | E | F | G | H | |
4+---+---+---+---+---+---+---+---+--------+
5//To区
6+---+---+---+---+---+---+---+------------+
7| A | B | C | E | F | G | H | |
8+---+---+---+---+---+---+---+------------+ D对象没有被复制,它将被作为垃圾进行回收
如果新生代中的一个对象只有一个指向它的指针,而这个指针在老生代中, 我们如何判断这个新生代的对象是否存活? 为了解决这个问题,需要建立一个列表用来记录所有老生代对象指向新生代对象的情况。 每当有老生代对象指向新生代对象的时候,我们就记录下来
当一个对象经过多次新生代的清理依旧幸存,这说明它的生存周期较长,也就会被移动到老生代,这称为对象的晋升。具体移动的标准有两种:
- 对象从From空间复制到To空间时,会检查它的内存地址来判断这个对象是否已经经历过一个新生代的清理,如果是,则复制到老生代中,否则复制到To空间中
- 对象从From空间复制到To空间时,如果To空间已经被使用了超过25%,那么这个对象直接被复制到老生代
老生代所保存的对象大多数是生存周期很长的甚至是常驻内存的对象,而且老生代占用的内存较多
老生代占用内存较多(64位为1.4GB,32位为700MB),如果使用Scavenge算法, 浪费一半空间不说,复制如此大块的内存消耗时间将 会相当长。所以Scavenge算法显然不适合。 V8在老生代中的垃圾回收策略采用 Mark-Sweep和Mark-Compact 相结合
标记清除分为标记和清除两个阶段。 在标记阶段需要遍历堆中的所有对象,并标记那些活着的对象,然后进入清除阶段。 在清除阶段总,只清除没有被标记的对象。 由于标记清除只清除死亡对象,而死亡对象在老生代中占用的比例很小,所以效率较高
标记清除有一个问题就是进行一次标记清楚后,内存空间往往是不连续的,会出现很多的内存碎片。 如果后续需要分配一个需要内存空间较多的对象时,如果所有的内存碎片都不够用,将会使得V8无法完成这次分配,提前触发垃圾回收。
标记整理正是为了解决标记清除所带来的内存碎片的问题。 标记整理在标记清除的基础进行修改,将其的清除阶段变为紧缩极端。 在整理的过程中,将活着的 对象向内存区的一段移动,移动完成后直接清理掉边界外的内存。 紧缩过程涉及对象的移动,所以效率并不是太好,但是能保证不会生成内存碎片。
标记清除和标记整理都分为两个阶段:标记阶段、清除或紧缩阶段
在标记阶段,所有堆上的活跃对象都会被标记。 每个内存页有一个用来标记对象的位图,位图中的每一位对应内存页中的一个字。 这个位图需要占据一定的空 间(32位下为3.1%,64位为1.6%)。 另外有两位用来标记对象的状态,这个状态一共有三种(所以要两位)——白,灰,黑:
- 如果一个对象为白对象,它还没未被垃圾回收器发现
- 如果一个对象为灰对象,它已经被垃圾回收器发现,但其邻接对象尚未全部处理
- 如果一个对象为黑对象,说明他步进被垃圾回收器发现,其邻接对象也全部被处理完毕了
Chrome V8的老生代使用标记清除和标记整理结合的方式,主要采用标记清除算法,如果空间不足以分配从新生代晋升过来的对象时,才使用标记整理
参考文章: