2023.03.09 - 2023.03.15 更新收集面试问题(45道题)【第5部分】
获取更多面试问题可以访问
github 地址: https://github.com/pro-collection/interview-question/issues
gitee 地址: https://gitee.com/yanleweb/interview-question/issues
目录:
-
初级开发者相关问题【共计 1 道题】
- 61.浏览器的主要组成部分是什么?【浏览器】
-
中级开发者相关问题【共计 11 道题】
- 53.手写实现函数节流【JavaScript】
- 54.请设计一个算法, 将两个有序数组合并为一个数组, 请不要使用concat以及sort方法【JavaScript】
- 55.常见清除浮动的解决方案有哪些【CSS】
- 56.[ES6]模块与[CommonJS]模块的差异有哪些?【JavaScript】
- 58.
display: none;与visibility: hidden;的区别是啥【CSS】 - 59.
display: block;和display: inline;的区别【CSS】 - 60.海量数据的处理问题: 如何从10亿个数中找出最大的10000个数?【JavaScript】
- 63.浏览器是如何渲染UI的?【浏览器】
- 64.浏览器 DOM Tree是如何构建的?【浏览器】
- 65.常见的浏览器内核有哪些,有啥区别?【浏览器】
- 66.重绘与重排的区别?【浏览器】
-
高级开发者相关问题【共计 3 道题】
- 57.手写 Promise , 并描述其原理与实现【JavaScript】
- 62.浏览器如何解析css选择器?【浏览器】
- 68.如何避免重绘或者重排?【JavaScript】
浏览器的主要组成部分是什么
- 用户界面 - 包括地址栏、前进/后退按钮、书签菜单等。除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
- 浏览器引擎 - 在用户界面和呈现引擎之间传送指令。
- 呈现引擎 - 负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
- 网络 - 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
- 用户界面后端 - 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
- JavaScript 解释器 - 用于解析和执行 JavaScript 代码。
- 数据存储。这是持久层 - 浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5) 定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。
https://blog.csdn.net/beijiyang999/article/details/79836463
对于持续触发的事件,规定一个间隔时间(n秒),每隔一段只能执行一次。
函数防抖(debounce)与本篇说的函数节流(throttle)相似又不同。
函数防抖一般是指对于在事件被触发n秒后再执行的回调,如果在这n秒内又重新被触发,则重新开始计时。
二者都能防止函数过于频繁的调用。
区别在于,当事件持续被触发,如果触发时间间隔短于规定的等待时间(n秒),那么
- 函数防抖的情况下,函数将一直推迟执行,造成不会被执行的效果;
- 函数节流的情况下,函数将每个 n 秒执行一次。
函数节流的实现有不同的思路,可以通过时间戳实现,也可以通过定时器实现。
只要触发,就用 Date 获取现在的时间,与上一次的时间比较。
如果时间差大于了规定的等待时间,就可以执行一次;
目标函数执行以后,就更新 previous 值,确保它是“上一次”的时间。
否则就等下一次触发时继续比较。
1function throttle(func, wait) {
2 let previous = 0;
3 return function() {
4 let now = +new Date();
5 let context = this;
6 if (now - previous >= wait) {
7 func.apply(context, arguments);
8 previous = now; // 执行后更新 previous 值
9 }
10 }
11}
12container.onmousemove = throttle(doSomething, 1000);用定时器实现时间间隔。
当定时器不存在,说明可以执行函数,于是定义一个定时器来向任务队列注册目标函数
目标函数执行后设置保存定时器ID变量为空
当定时器已经被定义,说明已经在等待过程中。则等待下次触发事件时再进行查看。
1function throttle(func, wait) {
2 let time, context;
3 return function(){
4 context = this;
5 if(!time){
6 time = setTimeout(function(){
7 func.apply(context, arguments);
8 time = null
9 }, wait)
10 }
11 }
12}一个周期内:
时间戳实现的:先执行目标函数,后等待规定的时间段;
计时器实现的:先等待够规定时间,再执行。 即停止触发后,若定时器已经在任务队列里注册了目标函数,它也会执行最后一次。
结合二者,实现一次触发,两次执行(先立即执行,结尾也有执行)
1function throttle (func, wait) {
2 let previous = 0;
3 let context, args, time;
4 return function(){
5 let now = +new Date();
6 context = this;
7 args = arguments;
8 if(now - previous >= wait){ //当距上一次执行的间隔大于规定,可以直接执行
9 func.apply(context, args);
10 previous = now
11 } else { // 否则继续等待,结尾执行一次
12 if(time) clearTimeout(time);
13 time = setTimeout(
14 () => {
15 func.apply(context, args);
16 time = null
17 }
18 , wait)
19 }
20 }
21}已经实现了一次触发,两次执行,有头有尾的效果。
问题是,上一个周期的“尾”和下一个周期的“头”之间,失去了对时间间隔的控制。
仔细查看,发现问题出在了 previous 的设置上。
仅仅在“可直接执行”的情况下更新了 previous 值,在通过计时器注册入任务队列后执行的情况下,忽略了 previous 的更新。 导致了 previous 的值不再是“上一次执行”时的时间,而是“上一次直接可执行情况下执行”的时间。
同时,引入变量 remaining 表示还需要等待的时间,来让尾部那一次的执行也符合时间间隔。
1function throttle(func, wait) {
2 let previous = 0;
3 let context, args, time, remaining;
4
5 return function() {
6 let now = +new Date();
7 context = this;
8 args = arguments;
9 remaining = wait - (now - previous); // 剩余的还需要等待的时间
10 if (remaining <= 0) {
11 func.apply(context, args);
12 previous = now // 重置“上一次执行”的时间
13 } else {
14 if (time) {
15 clearTimeout(time);
16 }
17 time = setTimeout(() => {
18 func.apply(context, args);
19 time = null;
20 previous = +new Date() // 重置“上一次执行”的时间
21 }, remaining) //等待还需等待的时间
22 }
23 };
24}参考 underscore 与 mqyqingfeng ,实现是否启用第一次 / 尾部最后一次计时回调的执行。
设置 options 作为第三个参数,然后根据传的值判断到底哪种效果,约定:
- leading:false 表示禁用第一次执行
- trailing: false 表示禁用停止触发的回调
1function throttle(func, wait, options) {
2 let time, context, args, result;
3 let previous = 0;
4 if (!options) options = {};
5
6 let later = function () {
7 previous = options.leading === false ? 0 : new Date().getTime();
8 time = null;
9 func.apply(context, args);
10 if (!time) context = args = null;
11 };
12
13 let throttled = function () {
14 let now = new Date().getTime();
15 if (!previous && options.leading === false) previous = now;
16 let remaining = wait - (now - previous);
17 context = this;
18 args = arguments;
19 if (remaining <= 0 || remaining > wait) {
20 if (time) {
21 clearTimeout(time);
22 time = null;
23 }
24 previous = now;
25 func.apply(context, args);
26 if (!time) context = args = null;
27 } else if (!time && options.trailing !== false) {
28 time = setTimeout(later, remaining);
29 }
30 };
31 return throttled;
32}如果想添加一个取消功能:
1throttled.cancel = function() {
2 clearTimeout(time);
3 time = null;
4 previous = 0;
5}54.请设计一个算法, 将两个有序数组合并为一个数组, 请不要使用concat以及sort方法【JavaScript】
1let merge = function (left, right) {
2 let leftIndex = 0, rightIndex = 0;
3 let result = [];
4 let leftLen = left.length;
5 let rightLen = right.length;
6 let diffIndex = leftLen - rightLen;
7 let connectList;
8 if(diffIndex > 0) {
9 connectList = left.slice(rightLen);
10 } else {
11 connectList = right.slice(leftLen);
12 }
13 while (leftIndex < left.length && rightIndex < right.length) {
14 if (left[leftIndex] < right[rightIndex]) {
15 result.push(left[leftIndex++])
16 } else {
17 result.push(right[rightIndex++])
18 }
19 }
20 // console.log(result);
21 result = result.concat(connectList);
22 return result;
23};
24
25let left = [1, 4, 7, 8, 9, 10];
26let right = [2, 5];
27console.log(merge(left, right)); 1<style type="text/css">
2 .div1 {
3 background: #000080;
4 border: 1px solid red; /*解决代码*/
5 height: 200px;
6 }
7
8 .div2 {
9 background: #800080;
10 border: 1px solid red;
11 height: 100px;
12 margin-top: 10px
13 }
14
15 .left {
16 float: left;
17 width: 20%;
18 height: 200px;
19 background: #DDD
20 }
21
22 .right {
23 float: right;
24 width: 30%;
25 height: 80px;
26 background: #DDD
27 }
28</style>
29<div class="div1">
30 <div class="left">Left</div>
31 <div class="right">Right</div>
32</div>
33<div class="div2">
34 div2
35</div>原理:父级div手动定义height,就解决了父级div无法自动获取到高度的问题。
优点:简单、代码少、容易掌握
缺点:只适合高度固定的布局,要给出精确的高度,如果高度和父级div不一样时,会产生问题
建议:不推荐使用,只建议高度固定的布局时使用
1<style type="text/css">
2 .div1 {
3 background: #000080;
4 border: 1px solid red
5 }
6
7 .div2 {
8 background: #800080;
9 border: 1px solid red;
10 height: 100px;
11 margin-top: 10px
12 }
13
14 .left {
15 float: left;
16 width: 20%;
17 height: 200px;
18 background: #DDD
19 }
20
21 .right {
22 float: right;
23 width: 30%;
24 height: 80px;
25 background: #DDD
26 }
27
28 /*清除浮动代码*/
29 .clearfloat {
30 clear: both
31 }
32</style>
33<div class="div1">
34 <div class="left">Left</div>
35 <div class="right">Right</div>
36 <div class="clearfloat"></div>
37</div>
38<div class="div2">
39 div2
40</div>原理:添加一个空div,利用css提高的clear:both清除浮动,让父级div能自动获取到高度
优点:简单、代码少、浏览器支持好、不容易出现怪问题
缺点:不少初学者不理解原理;如果页面浮动布局多,就要增加很多空div,让人感觉很不好
建议:不推荐使用,但此方法是以前主要使用的一种清除浮动方法
3、父级div定义 伪类:after 和 zoom
1<style type="text/css">
2 .div1 {
3 background: #000080;
4 border: 1px solid red;
5 }
6
7 .div2 {
8 background: #800080;
9 border: 1px solid red;
10 height: 100px;
11 margin-top: 10px
12 }
13
14 .left {
15 float: left;
16 width: 20%;
17 height: 200px;
18 background: #DDD
19 }
20
21 .right {
22 float: right;
23 width: 30%;
24 height: 80px;
25 background: #DDD
26 }
27
28 /*清除浮动代码*/
29 .clearfloat:after {
30 display: block;
31 clear: both;
32 content: "";
33 visibility: hidden;
34 height: 0
35 }
36
37 .clearfloat {
38 zoom: 1
39 }
40</style>
41<div class="div1 clearfloat">
42 <div class="left">Left</div>
43 <div class="right">Right</div>
44</div>
45<div class="div2">
46 div2
47</div>原理:IE8以上和非IE浏览器才支持:after,原理和方法2有点类似,zoom(IE转有属性)可解决ie6,ie7浮动问题
优点:浏览器支持好、不容易出现怪问题(目前:大型网站都有使用,如:腾迅,网易,新浪等等)
缺点:代码多、不少初学者不理解原理,要两句代码结合使用才能让主流浏览器都支持。
建议:推荐使用,建议定义公共类,以减少CSS代码。
4、父级div定义 overflow:hidden
1<style type="text/css">
2 .div1 {
3 background: #000080;
4 border: 1px solid red; /*解决代码*/
5 width: 98%;
6 overflow: hidden
7 }
8
9 .div2 {
10 background: #800080;
11 border: 1px solid red;
12 height: 100px;
13 margin-top: 10px;
14 width: 98%
15 }
16
17 .left {
18 float: left;
19 width: 20%;
20 height: 200px;
21 background: #DDD
22 }
23
24 .right {
25 float: right;
26 width: 30%;
27 height: 80px;
28 background: #DDD
29 }
30</style>
31<div class="div1">
32 <div class="left">Left</div>
33 <div class="right">Right</div>
34</div>
35<div class="div2">
36 div2
37</div>原理:必须定义width或zoom:1,同时不能定义height,使用overflow:hidden时,浏览器会自动检查浮动区域的高度
优点:简单、代码少、浏览器支持好
缺点:不能和position配合使用,因为超出的尺寸的会被隐藏。
建议:只推荐没有使用position或对overflow:hidden理解比较深的朋友使用。
1<style type="text/css">
2 .div1 {
3 background: #000080;
4 border: 1px solid red; /*解决代码*/
5 width: 98%;
6 overflow: auto
7 }
8
9 .div2 {
10 background: #800080;
11 border: 1px solid red;
12 height: 100px;
13 margin-top: 10px;
14 width: 98%
15 }
16
17 .left {
18 float: left;
19 width: 20%;
20 height: 200px;
21 background: #DDD
22 }
23
24 .right {
25 float: right;
26 width: 30%;
27 height: 80px;
28 background: #DDD
29 }
30</style>
31<div class="div1">
32 <div class="left">Left</div>
33 <div class="right">Right</div>
34</div>
35<div class="div2">
36 div2
37</div>原理:必须定义width或zoom:1,同时不能定义height,使用overflow:auto时,浏览器会自动检查浮动区域的高度
优点:简单、代码少、浏览器支持好
缺点:内部宽高超过父级div时,会出现滚动条。
建议:不推荐使用,如果你需要出现滚动条或者确保你的代码不会出现滚动条就使用吧。
1<style type="text/css">
2 .div1 {
3 background: #000080;
4 border: 1px solid red; /*解决代码*/
5 width: 98%;
6 margin-bottom: 10px;
7 float: left
8 }
9
10 .div2 {
11 background: #800080;
12 border: 1px solid red;
13 height: 100px;
14 width: 98%; /*解决代码*/
15 clear: both
16 }
17
18 .left {
19 float: left;
20 width: 20%;
21 height: 200px;
22 background: #DDD
23 }
24
25 .right {
26 float: right;
27 width: 30%;
28 height: 80px;
29 background: #DDD
30 }
31</style>
32<div class="div1">
33 <div class="left">Left</div>
34 <div class="right">Right</div>
35</div>
36<div class="div2">
37 div2
38</div>原理:所有代码一起浮动,就变成了一个整体
优点:没有优点
缺点:会产生新的浮动问题。
建议:不推荐使用,只作了解。
1<style type="text/css">
2 .div1 {
3 background: #000080;
4 border: 1px solid red; /*解决代码*/
5 width: 98%;
6 display: table;
7 margin-bottom: 10px;
8 }
9
10 .div2 {
11 background: #800080;
12 border: 1px solid red;
13 height: 100px;
14 width: 98%;
15 }
16
17 .left {
18 float: left;
19 width: 20%;
20 height: 200px;
21 background: #DDD
22 }
23
24 .right {
25 float: right;
26 width: 30%;
27 height: 80px;
28 background: #DDD
29 }
30</style>
31<div class="div1">
32 <div class="left">Left</div>
33 <div class="right">Right</div>
34</div>
35<div class="div2">
36 div2
37</div>原理:将div属性变成表格
优点:没有优点
缺点:会产生新的未知问题。
建议:不推荐使用,只作了解。
1<style type="text/css">
2 .div1 {
3 background: #000080;
4 border: 1px solid red;
5 margin-bottom: 10px;
6 zoom: 1
7 }
8
9 .div2 {
10 background: #800080;
11 border: 1px solid red;
12 height: 100px
13 }
14
15 .left {
16 float: left;
17 width: 20%;
18 height: 200px;
19 background: #DDD
20 }
21
22 .right {
23 float: right;
24 width: 30%;
25 height: 80px;
26 background: #DDD
27 }
28
29 .clearfloat {
30 clear: both
31 }
32</style>
33<div class="div1">
34 <div class="left">Left</div>
35 <div class="right">Right</div>
36 <br class="clearfloat"/>
37</div>
38<div class="div2">
39 div2
40</div>原理:父级div定义zoom:1来解决IE浮动问题,结尾处加 br标签 clear:both
建议:不推荐使用,只作了解。
56.[ES6]模块与[CommonJS]模块的差异有哪些?【JavaScript】
差异主要有如下几点:
- CommonJS 输出是值的拷贝,即原来模块中的值改变不会影响已经加载的该值,ES6静态分析,动态引用,输出的是值的引用,值改变,引用也改变,即原来模块中的值改变则该加载的值也改变。
- CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
- CommonJS 加载的是整个模块,即将所有的接口全部加载进来,ES6 可以单独加载其中的某个接口(方法),
- CommonJS this 指向当前模块,ES6 this 指向undefined
CommonJS 模块输出的是值的拷贝,也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。 ES6 模块的运行机制与 CommonJS 不一样。 JS 引擎对脚本静态分析的时候,遇到模块加载命令import,就会生成一个只读引用。 等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。 ES6 模块不会缓存运行结果,而是动态地去被加载的模块取值,并且变量总是绑定其所在的模块。
58.display: none;与visibility: hidden;的区别是啥【CSS】
联系:它们都能让元素不可见
区别:
- display:none;会让元素完全从渲染树中消失,渲染的时候不占据任何空间; visibility: hidden;不会让元素从渲染树消失,渲染师元素继续占据空间,只是内容不可见
- display: none;是非继承属性,子孙节点消失由于元素从渲染树消失造成,通过修改子孙节点属性无法显示; visibility: hidden;是继承属性,子孙节点消失由于继承了hidden,通过设置visibility: visible;可以让子孙节点显式
- 修改常规流中元素的display通常会造成文档重排。修改visibility属性只会造成本元素的重绘。
- 读屏器不会读取display: none;元素内容;会读取visibility: hidden;元素内容
59.display: block;和display: inline;的区别【CSS】
block元素特点:
1.处于常规流中时,如果width没有设置,会自动填充满父容器 2.可以应用margin/padding 3.在没有设置高度的情况下会扩展高度以包含常规流中的子元素 4.处于常规流中时布局时在前后元素位置之间(独占一个水平空间) 5.忽略vertical-align
inline元素特点
1.水平方向上根据direction依次布局 2.不会在元素前后进行换行 3.受white-space控制 4.margin/padding在竖直方向上无效,水平方向上有效 5.width/height属性对非替换行内元素无效,宽度由元素内容决定 6.非替换行内元素的行框高由line-height确定,替换行内元素的行框高由height,margin,padding,border决定 6.浮动或绝对定位时会转换为block 7.vertical-align属性生效
60.海量数据的处理问题: 如何从10亿个数中找出最大的10000个数?【JavaScript】
从10亿个数中找出最大的10000个数是一项非常具有挑战性的任务,需要使用高效的算法和数据结构来处理。
以下是一种基于分治思想的常见方法:
将10亿个数分成1000个小文件,每个文件包含100万个数。 对每个小文件进行排序,选出每个文件中最大的1000个数,并将它们放入一个临时文件中。 将1000个临时文件合并成一个大文件,并再次对其进行排序。 选出最大的10000个数。
这种方法的时间复杂度为O(N*log(N/K)),其中N是所有数据的数量,K是每个小文件中的数据量。由于K相对较小,因此这种方法非常高效。
浏览器渲染UI的过程通常被称为渲染流水线(rendering pipeline),它可以分为以下几个步骤:
-
解析HTML:浏览器首先解析HTML代码,创建DOM(文档对象模型)树。DOM树是由节点和对象组成的层次结构,它表示了文档的内容和结构。
-
解析CSS:浏览器接着解析CSS代码,创建CSSOM(CSS对象模型)树。CSSOM树是由CSS规则和对应的元素组成的层次结构,它表示了文档中的元素的样式信息。
-
创建渲染树:浏览器将DOM树和CSSOM树结合起来,生成渲染树。渲染树只包含需要显示的元素,它是一种按照渲染顺序排列的树形结构。
-
布局:浏览器对渲染树进行布局(layout),计算每个元素在屏幕上的位置和大小。
-
绘制:浏览器将渲染树中的每个元素绘制到屏幕上。
-
合成:如果有多个层叠的元素,浏览器将它们合成一个图层,以提高性能。
这些步骤通常是逐步完成的,而且它们是相互依赖的。例如,布局必须在绘制之前完成,因为绘制需要知道每个元素的位置和大小。为了提高性能,浏览器通常会对这些步骤进行优化,例如使用异步布局和延迟合成等技术。
64.浏览器 DOM Tree是如何构建的?【浏览器】
浏览器构建DOM树的过程包括以下几个步骤:
-
解析HTML代码:浏览器会将HTML代码解析成一个DOM树的结构。
-
创建根节点:DOM树的根节点通常是HTML元素。
-
创建子节点:根据HTML标记的嵌套关系,浏览器会在DOM树中创建相应的子节点,每个节点表示一个HTML元素。
-
创建属性节点:HTML元素可能有一些属性,例如id、class、src等,浏览器会将这些属性创建为节点的属性节点。
-
创建文本节点:如果HTML元素中包含文本内容,浏览器会将这些文本内容创建为文本节点,并将它们作为元素的子节点插入到DOM树中。
-
创建注释节点:HTML代码中可能包含注释,浏览器会将注释创建为注释节点,并将它们插入到DOM树中。
-
构建完整的DOM树:经过以上步骤,浏览器会将所有HTML代码解析成一个完整的DOM树。
需要注意的是,浏览器构建DOM树是一个逐步进行的过程,解析器会逐个读取HTML标记,并创建相应的节点,直到解析完整个HTML代码。在这个过程中,如果遇到错误的HTML标记,浏览器也会尽可能地将其解析成一个节点,以保证DOM树的完整性。
65.常见的浏览器内核有哪些,有啥区别?【浏览器】
常见的浏览器内核包括:
-
Trident内核:由Microsoft开发,主要用于Internet Explorer浏览器,也是Windows系统自带的默认浏览器内核。该内核在HTML和CSS的解释、渲染方面存在一些问题,但在JavaScript引擎的处理上表现较为出色。
-
Gecko内核:由Mozilla开发,主要用于Firefox浏览器。该内核在HTML和CSS的解释、渲染方面表现较好,同时也有较强的JavaScript引擎。
-
WebKit内核:由苹果公司开发,最初是为Safari浏览器所用。该内核在HTML、CSS和JavaScript处理方面都表现出色,支持的CSS特性较多。
-
Blink内核:由Google和Opera Software共同开发,用于Chrome浏览器和Opera浏览器。该内核是Webkit内核的一个分支,对Web标准的支持也非常好。
这些浏览器内核之间的主要区别在于对Web标准的支持程度、渲染引擎的处理能力、JavaScript引擎的性能、浏览器的兼容性等方面。此外,不同的浏览器内核也会有一些独特的特性和优化,以满足不同用户的需求。
| 浏览器内核 | 开发公司 | 代表浏览器 | 支持程度 | 渲染引擎 | JavaScript引擎 | 浏览器兼容性 |
|---|---|---|---|---|---|---|
| Trident | Microsoft | Internet Explorer | 一般 | 一般 | 出色 | 差 |
| Gecko | Mozilla | Firefox | 较好 | 较好 | 出色 | 好 |
| WebKit | Apple | Safari | 出色 | 出色 | 出色 | 好 |
| Blink | Google and Opera Software | Chrome and Opera | 出色 | 出色 | 出色 | 好 |
浏览器重绘(Repaint)和重排(Reflow)是Web页面中常见的两种渲染方式,它们的区别如下:
-
重排(Reflow):当DOM元素的结构或者布局发生变化时,浏览器需要重新计算元素的几何属性(比如位置、大小等),然后重新构建渲染树,这个过程叫做重排。重排的代价比较高,因为需要浏览器重新计算和布局,会消耗较多的CPU资源和时间。
-
重绘(Repaint):当元素的样式(如背景颜色、字体颜色、边框颜色等)发生变化时,浏览器会重新绘制元素的样式,这个过程叫做重绘。重绘的代价比较低,因为不需要重新计算元素的位置和大小,只需要重新绘制元素的样式即可。
因此,重排会触发重绘,但是重绘不一定会触发重排。在Web开发中,我们应该尽量避免频繁的重排和重绘,以提高页面的性能。一些常见的优化方式包括:减少DOM操作、使用CSS3动画代替JavaScript动画、避免使用table布局等。
57.手写 Promise , 并描述其原理与实现【JavaScript】
目录
-
Promise 概括来说是对异步的执行结果的描述对象。(这句话的理解很重要)
-
Promise 规范中规定了,promise 的状态只有3种:
- pending
- fulfilled
- rejected
Promise 的状态一旦改变则不会再改变。
-
Promise 规范中还规定了 Promise 中必须有 then 方法,这个方法也是实现异步的链式操作的基本。
-
Promise 构造器中必须传入函数,否则会抛出错误。(没有执行器还怎么做异步操作。。。)
-
Promise.prototype上的 catch(onrejected) 方法是 then(null,onrejected) 的别名,并且会处理链之前的任何的reject。
-
Promise.prototype 上的 then和 catch 方法总会返回一个全新的 Promise 对象。
-
如果传入构造器的函数中抛出了错误,该 promise 对象的[[PromiseStatus]]会赋值为 rejected,并且[[PromiseValue]]赋值为 Error 对象。
-
then 中的回调如果抛出错误,返回的 promise 对象的[[PromiseStatus]]会赋值为 rejected,并且[[PromiseValue]]赋值为 Error 对象。
-
then 中的回调返回值会影响 then 返回的 promise 对象。(下文会具体分析)
做了上面的铺垫,实现一个 Promise 的思路就清晰很多了,本文使用 ES6 来进行实现, 暂且把这个类取名为 GPromise吧(不覆盖原生的,便于和原生进行对比测试)。 下文中 GPromise 代指将要实现的类,Promise 代指 ES6中的 Promise 类。
在浏览器中打印出一个 Promise 实例会发现其中会包括两用”[[ ]]”包裹起来的属性,这是系统内部属性,只有JS 引擎能够访问。
1[[PromiseStatus]]
2[[PromiseValue]] 以上两个属性分别是 Promise 对象的状态和最终值。
我们自己不能实现内部属性,JS中私有属性特性(#修饰符现在还是提案)暂时也没有支持, 所以暂且用”_”前缀规定私有属性,这样就模拟了Promise 中的两个内部属性。
1class GPromise {
2 constructor(executor) {
3 this._promiseStatus = GPromise.PENDING;
4 this._promiseValue;
5 this.execute(executor);
6 }
7
8 execute(executor){
9 //...
10 }
11
12 then(onfulfilled, onrejected){
13 //...
14 }
15 }
16
17GPromise.PENDING = 'pedding';
18GPromise.FULFILLED = 'resolved';
19GPromise.REJECTED = 'rejected';- 传入构造器的executor为函数,并且在构造时就会执行。
- 我们给 executor 中传入 resolve 和 reject 参数,这两个参数都是函数,用于改变改变 _promiseStatus和 _promiseValue 的值。
- 并且内部做了捕获异常的操作,一旦传入的executor 函数执行抛出错误,GPromise 实例会变成 rejected状态, 即 _promiseStatus赋值为’rejected’,并且 _promiseValue赋值为Error对象。
1execute(executor) {
2 if (typeof executor != 'function') {
3 throw new Error(` GPromise resolver ${executor} is not a function`);
4 }
5 //捕获错误
6 try {
7 executor(data => {
8 this.promiseStatus = GPromise.FULFILLED;
9 this.promiseValue = data;
10 }, data => {
11 this.promiseStatus = GPromise.REJECTED;
12 this.promiseValue = data;
13 });
14 } catch (e) {
15 this.promiseStatus = GPromise.REJECTED;
16 this.promiseValue = e;
17 }
18}then 方法内部逻辑稍微复杂点,并且有一点一定一定一定要注意到: then 方法中的回调是异步执行的,思考下下段代码:
1console.log(1);
2new Promise((resolve,reject)=>{
3 console.log(2);
4 resolve();
5})
6.then(()=>console.log(3));
7console.log(4);执行结果是什么呢?答案其实是:1 2 4 3。
then 方法中的难点就是处理异步,其中一个方案是通过 setInterval来监听GPromise 对象的状态改变, 一旦改变则执行相应then 中相应的回调函数(onfulfilled和onrejected),这样回调函数就能够插入事件队列末尾, 异步执行,实验证明可行,这种方案是最直观也最容易理解的。
then 方法的返回值是一个新的 GPromise 对象,并且这个对象的状态和 then 中的回调返回值相关,回调指代传入的 onfulfilled 和 rejected。
- 如果 then 中的回调抛出了错误,返回的 GPromise 的 _promiseStatus 赋值为’rejected’, _promiseValue赋值为抛出的错误对象。
- 如果回调返回了一个非 GPromise 对象, then返回的 GPromise 的 _promiseStatus 赋值为’resolved’, _promiseValue赋值为回调的返回值。
- 如果回调返回了一个 GPromise 对象,then返回的GPromise对象 的_promiseStatus和 _promiseValue 和其保持同步。也就是 then 返回的GPromise记录了回调返回的状态和值,不是直接返回回调的返回值。
1then(onfulfilled, onrejected) {
2 let _ref = null,
3 timer = null,
4 result = new GPromise(() => {});
5
6 //因为 promise 的 executor 是异步操作,需要监听 promise 对象状态变化,并且不能阻塞线程
7 timer = setInterval(() => {
8 if ((typeof onfulfilled == 'function' && this._promiseStatus == GPromise.FULFILLED) ||
9 (typeof onrejected == 'function' && this._promiseStatus == GPromise.REJECTED)) {
10 //状态发生变化,取消监听
11 clearInterval(timer);
12 //捕获传入 then 中的回调的错误,交给 then 返回的 promise 处理
13 try {
14 if (this._promiseStatus == GPromise.FULFILLED) {
15 _ref = onfulfilled(this._promiseValue);
16 } else {
17 _ref = onrejected(this._promiseValue);
18 }
19
20 //根据回调的返回值来决定 then 返回的 GPromise 实例的状态
21 if (_ref instanceof GPromise) {
22 //如果回调函数中返回的是 GPromise 实例,那么需要监听其状态变化,返回新实例的状态是根据其变化相应的
23 timer = setInterval(()=>{
24 if (_ref._promiseStatus == GPromise.FULFILLED ||
25 _ref._promiseStatus == GPromise.REJECTED) {
26 clearInterval(timer);
27 result._promiseValue = _ref._promiseValue;
28 result._promiseStatus = _ref._promiseStatus;
29 }
30 },0);
31
32 } else {
33 //如果返回的是非 GPromise 实例
34 result._promiseValue = _ref;
35 result._promiseStatus = GPromise.FULFILLED;
36 }
37 } catch (e) {
38 //回调中抛出错误的情况
39 result._promiseStatus = GPromise.REJECTED;
40 result._promiseValue = e;
41 }
42 }
43 }, 0);
44 //promise 之所以能够链式操作,因为返回了GPromise对象
45 return result;
46 }Promise 的 then 的 注册微任务队列 和 执行 是分离的。
注册 : 是完全遵循 JS 和 Promise 的代码的执行过程。
执行 : 先 同步,再 微任务 ,再 宏观任务。
1/**
2 * promise 是可连续执行的?
3 * 是可以的!
4 */
5
6new Promise((resolve, reject) => {
7 console.log(1);
8 // return reject();
9 return resolve();
10})
11 .then(() => {
12 console.log(2);
13 })
14 .then(()=> {
15 console.log(3);
16 })
17 .then(()=> {
18 console.log(4);
19 })
20 .catch(()=> {
21 console.log('catch');
22 })
23 .finally(()=> {
24 console.log('finally');
25 }); 1new Promise((resolve, reject) => {
2 console.log(1);
3 return resolve()
4}).then(() => {
5 console.log(2);
6 // 外部第一个 then 方法里面 return 一个 Promise,这个 return ,代表 外部的第二个 then 的执行需要等待 return 之后的结果。
7 return new Promise((resolve) => {
8 console.log(3);
9
10 return resolve()
11 })
12 .then(() => {
13 console.log(4);
14 })
15 .then(() => {
16 console.log(5);
17 })
18}).then(() => {
19 console.log(6);
20}).then(() => {
21 console.log(7);
22}); 1// 我们核心要看 then 的回调函数是啥时候注册的,我们知道,事件机制是 “先注册先执行”,
2// 即数据结构中的 “栈” 的模式,first in first out。那么重点我们来看下他们谁先注册的。
3
4// 外部的第二个 then 的注册,需要等待 外部的第一个 then 的同步代码执行完成。
5// 当执行内部的 new Promise 的时候,然后碰到 resolve,resolve 执行完成,
6// 代表此时的该 Promise 状态已经扭转,之后开始内部的第一个 .then 的微任务的注册,此时同步执行完成。
7new Promise((resolve) => {
8 console.log(1);
9 return resolve()
10}).then(() => {
11 console.log(2);
12 // 内部的 resolve 之后,当然是先执行内部的 new Promise 的第一个 then 的注册,这个 new Promise 执行完成,立即同步执行了后面的 .then 的注册。
13 new Promise((resolve) => {
14 console.log(3);
15 return resolve()
16 })
17 .then(() => {
18 console.log(4);
19 })
20 // 然而这个内部的第二个 then 是需要第一个 then 的的执行完成来决定的,而第一个 then 的回调是没有执行,仅仅只是执行了同步的 .then 方法的注册,所以会进入等待状态。
21 .then(() => {
22 console.log(5);
23 })
24 .then(()=> {
25 console.log(6);
26 })
27}).then(() => {
28 // 外部的第一个 then 的同步操作已经完成了,
29 // 然后开始注册外部的第二个 then,此时外部的同步任务也都完成了。
30 // 外部第二个 then 完成之后, 进入等待, 内部的第二个 then 注册之后在执行
31 console.log(7);
32}).then(() => {
33 console.log(8);
34}).then(()=> {
35 console.log(9);
36}); 1/**
2 * 链式调用的注册是前后依赖的 比如上面的外部的第二个 then 的注册,是需要外部的第一个的 then 的执行完成。
3 *
4 * 变量定义的方式,注册都是同步的 比如这里的 p.then 和 var p = new Promise 都是同步执行的。
5 */
6new Promise(resolve=> {
7 console.log('1');
8 resolve();
9})
10 .then(()=> {
11 console.log(2);
12 const p = new Promise(resove=> {
13 console.log(3);
14 resove();
15 });
16
17 p.then(()=> {
18 console.log(4);
19 });
20
21 p.then(()=> {
22 console.log(5);
23 });
24 })
25 .then(()=> {
26 console.log(6)
27 })
28 .then(()=> {
29 console.log(7)
30 }); 1/**
2 * 这段代码中,外部的注册采用了非链式调用的写法,根据上面的讲解,
3 * 我们知道了外部代码的 p.then 是并列同步注册的。
4 * 所以代码在内部的 new Promise 执行完,p.then 就都同步注册完了。
5 *
6 * 内部的第一个 then 注册之后,
7 * 就开始执行外部的第二个 then 了(外部的第二个 then 和 外部的第一个 then 都是同步注册完了)。
8 * 然后再依次执行内部的第一个 then ,内部的第二个 then。
9 * @type {Promise}
10 */
11const p = new Promise(resolve => {
12 console.log(1);
13 resolve()
14});
15
16p.then(() => {
17 console.log(2);
18 new Promise(resolve => {
19 console.log(3);
20 resolve();
21 })
22 .then(() => {
23 console.log(4);
24 })
25 .then(() => {
26 console.log(5);
27 })
28});
29
30p.then(() => {
31 console.log(6);
32});
33
34p.then(() => {
35 console.log(7)
36}); 1new Promise(resolve => {
2 console.log(1);
3 resolve();
4})
5 .then(() => {
6 console.log(2);
7 new Promise(resolve => {
8 console.log(3);
9 resolve();
10 })
11 .then(() => {
12 console.log(4);
13 })
14 .then(() => {
15 console.log(5);
16 });
17
18 return new Promise(resolve => {
19 console.log(6);
20 resolve();
21 })
22 .then(() => {
23 console.log(7);
24 })
25 .then(() => {
26 console.log(8);
27 })
28 })
29 .then(() => {
30 console.log(9);
31 })
32 .then(() => {
33 console.log(10);
34 }); 1new Promise((resolve, reject) => {
2 console.log('外部promise');
3 resolve();
4})
5 .then(() => {
6 console.log('外部第一个then');
7 new Promise((resolve, reject) => {
8 console.log('内部promise');
9 resolve();
10 })
11 .then(() => {
12 console.log('内部第一个then');
13 return Promise.resolve();
14 })
15 .then(() => {
16 console.log('内部第二个then');
17 })
18 })
19 .then(() => {
20 console.log('外部第二个then');
21 })
22 .then(() => {
23 console.log('外部第三个then');
24 })浏览器会『从右往左』解析CSS选择器。
相信很多人在一开始接触CSS的时候都会看到一条规则就是尽量少使用层级关系,比如尽量不要写成:
1#div P.class {
2 color: red;
3}而是写成:
之所以需要这么写,给的解释是这样可以减少选择器匹配的次数。 初看觉得哦,有点道理啊,但是往细了再想想: 如果我把层级定的足够的清晰分明,那不是可以直接去掉很多不对应的CSS选择器的索引路径的么?为什么都是建议少使用层级关系呢?
原因其实很简单,我们犯了一个经验主义错误,默认CSS选择器是从左往右进行解析的,实际上恰恰相反,CSS选择器是从右往左解析的。
再次看下图:
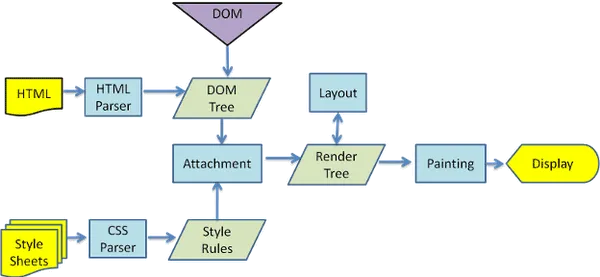
在图中我们可以看到HTML解析出了一颗DOM tree,与此同时样式脚本则解析生成了一个style rules,也可以说是一个CSS tree。 最后,DOM tree同style rules一同结合解析出一颗Render Tree, 而Render Tree就是包含了一个dom对象以及为其计算好的样式规则,提供了布局以及显示方法。
因为不清楚一个DOM对象上究竟对应着哪些样式规则,所以只能选择一个最笨的办法, 即每一个DOM对象都遍历一遍style rules,DOM对象的数量相信大家也都清楚, 如果每次遍历style rules都是像一个晒太阳的老大爷一样的悠哉游哉,因此对CSS选择器进行优化就是一个必须的事情了。
假如有如下的一段HTML:
1<div id="div1">
2 <div class="a">
3 <div class="b">
4 ...
5 </div>
6 <div class="c">
7 <div class="d">
8 ...
9 </div>
10 <div class="e">
11 ...
12 </div>
13 </div>
14 </div>
15 <div class="f">
16 <div class="c">
17 <div class="d">
18 ...
19 </div>
20 </div>
21 </div>
22</div>和如下的CSS:
1#div1 .c .d {}
2.f .c .d {}
3.a .c .e {}
4#div1 .f {}
5.c .d{}假如我们的CSS解析器是从左往右进行匹配的,那么会生成如下的style rules: 
首先,#div1 .c .d {} .f .c .d {}.c .d{}这三个选择器里面都含有 .c .d{}这么一个公用样式, 所以哪怕是我们的DOM节点明确了是在#div1下面都必须对style rules进行全部的匹配查找, 这样一来基本上可以说是每一个DOM节点都必须完全遍历一遍style rules, 不然搞不好就会漏掉一些公用样式之类的,所以想着将层级写的更加详细就能去掉很多不对应的CSS选择器的索引路径的就不要想了, 不管你写的多细,你总是需要把整个style rules都遍历一遍,不然万一漏掉了某个公用样式不就思密达了?
那么如果我们换成从右向左进行解析就能够避免这种情况了么?请看下面这个style rules:

别的先不提,最少这个节点就少了很多嘛,哪怕我这里同样是需要全部遍历一遍就冲着减少了这么多个节点也要从右往左进行解析啊!
更重要的是,只要有公用样式,那么选择器最右边的那个类型选择器一定是相同的,如此公共样式就很自然的都集中到一个分支上, 这个时候我们完全可以将其他不匹配的路径全部去掉而不用担心会漏掉某些个公用样式了。 虽然当这颗CSS树在遍历的时候还有有部分节点会遍历到最后才能确定到底是不是匹配的, 但总的来说从右往左进行解析还是会比从左往右解析要少很多次的匹配,这样带来的效率提升是显而易见的!
同时,这也是不建议使用*通配符来进行样式匹配的原因:浏览器专门建立了一个反常规思维的从右往左的匹配规则就是为了避免对所有元素进行遍历。
最后,从右往左进行解析还有一个好处那就是从右往左进行匹配的时候,匹配的全部是DOM元素的父节点, 而从左往右进行匹配的时候时候,匹配的全部是DOM元素的子节点,这样就避免了HTML与CSS没有下载完需要进行等待的情形。
68.如何避免重绘或者重排?【JavaScript】
任何改变用来构建渲染树的信息都会导致一次重排或重绘:
- 添加、删除、更新DOM节点
- 通过display: none隐藏一个DOM节点-触发重排和重绘
- 通过visibility: hidden隐藏一个DOM节点-只触发重绘,因为没有几何变化
- 移动或者给页面中的DOM节点添加动画
- 添加一个样式表,调整样式属性
- 用户行为,例如调整窗口大小,改变字号,或者滚动。
我们往往通过改变class的方式来集中改变样式
1// 判断是否是黑色系样式
2const theme = isDark ? 'dark' : 'light';
3
4// 根据判断来设置不同的class
5ele.setAttribute('className', theme);我们可以通过createDocumentFragment创建一个游离于DOM树之外的节点,然后在此节点上批量操作,最后插入DOM树中,因此只触发一次重排
1var fragment = document.createDocumentFragment();
2
3for (let i = 0;i<10;i++){
4 let node = document.createElement("p");
5 node.innerHTML = i;
6 fragment.appendChild(node);
7}
8
9document.body.appendChild(fragment);元素提升为合成层有以下优点:
- 合成层的位图,会交由 GPU 合成,比 CPU 处理要快
- 当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层
- 对于 transform 和 opacity 效果,不会触发 layout 和 paint
提升合成层的最好方式是使用 CSS 的 will-change 属性:
1#target {
2 will-change: transform;
3}